邻接矩阵专题

C语言-数据结构 克鲁斯卡尔算法(Kruskal)邻接矩阵存储
相比普里姆算法来说,克鲁斯卡尔的想法是从边出发,不管是理解上还是实现上都更简单,实现思路:我们先把找到所有边存到一个边集数组里面,并进行升序排序,然后依次从里面取出每一条边,如果不存在回路,就说明可以取,否则就跳过去看下一条边。其中看是否是回路这个操作利用到了并查集,就是判断新加入的这条边的两个顶点是否在同一个集合中,如果在就说明产生回路,如果没在同一个集合那么说明没有回路可以加入

「图」邻接矩阵|边集数组|邻接表 / LeetCode 35|33|81(C++)
概述 我们开始入门图论:图的存储。 图是一种高级数据结构:链表是一个节点由一条边指向下一个节点,二叉树是一个节点由两条边指向下两个节点,而图是由任意多个节点由任意多条边指向任意多个节点。 图由节点和边构成,边往往存在边权。边权在不同的问题中往往有不同含义,如在最短路径中表示边的长度,在AOE网中表示任务所需时间。 对于这种复杂的结构,如何存储在计算机的程序语言中呢? 我们先来介绍三种存储

数据结构实验图论:基于邻接矩阵/邻接表的广度优先搜索遍历(BFS)
数据结构实验图论一:基于邻接矩阵的广度优先搜索遍历 Time Limit: 1000MS Memory limit: 65536K 题目描述 给定一个无向连通图,顶点编号从0到n-1,用广度优先搜索(BFS)遍历,输出从某个顶点出发的遍历序列。(同一个结点的同层邻接点,节点编号小的优先遍历) 输入 输入第一行为整数n(0< n <100),表示数据的组数。 对于

图的广度优先搜索(BFS)算法与邻接矩阵表示
图的广度优先搜索(BFS)算法与邻接矩阵表示 1. 图的表示2. 广度优先搜索(BFS)BFS 算法步骤: 3. 使用邻接矩阵的 BFS 实现4. 运行时间分析时间复杂度:空间复杂度: 5. BFS 使用邻接列表与邻接矩阵的比较BFS 在邻接列表上的运行时间: 6. 结论 在计算机科学中,图是一种重要的数据结构,用于表示对象之间的复杂关系。图可以通过多种方式表示,包括邻接矩阵和邻接

(转)图算法单源最短路径Dijkstra算法(邻接表/邻接矩阵+优先队列STL)
一、前言 最短路径算法,顾名思义就是求解某点到某点的最短的距离、消耗、费用等等,有各种各样的描述,在地图上看,可以说是图上一个地点到达另外一个地点的最短的距离。比方说,我们把地图上的每一个城市想象成一个点,从一个城市到另一个城市的花费是不一样的。现在我们要从上海去往北京,需要考虑的是找到一条路线,使得从上海到北京的花费最小。有人可能首先会想到,飞机直达啊,这当然是时间消耗最小的方法,但是考虑

06-6.2.1 邻接矩阵法
👋 Hi, I’m @Beast Cheng 👀 I’m interested in photography, hiking, landscape… 🌱 I’m currently learning python, javascript, kotlin… 📫 How to reach me --> 458290771@qq.com 喜欢《数据结构》部分笔记的小伙伴可以订阅专栏,今后还会
【数据结构与算法】图的存储(邻接矩阵,邻接表)详解
图的邻接矩阵数据结构 typedef enum { NDG, DG, NDN, DN } GraphKind;using VRType = int;using InfoType = int;typedef struct ArcCell {VRType adj;InfoType *info;} Arc[N][N];struct MGraph {ElemType vexs[N];Arc arc;
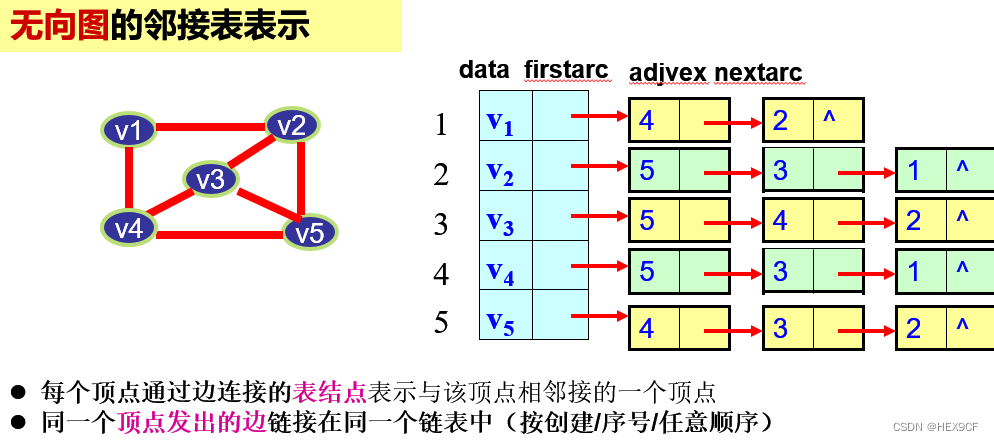
图的邻接矩阵和邻接表表示法
链表是一种线性存储结构,是一对一对应关系。而树是一种层次存储结构,是一对多的对应关系。而图则是一种关系存储结构,是多对多对应关系。树和图类似于数据库中的层次模型和关系模型。图的存储结构主要有两种,分别为邻接矩阵和邻接表法,其中邻接表较难,但本质相同,都是记录结点与其邻接结点,只是方法不同而已。下面分别讨论邻接表和邻接矩阵的思想。邻接表的思想是:定义三个结点,分别为表结点,头结点,邻接表结点,表结点
成长路上的小程序之——图的邻接矩阵DFS、BFS
之所以发这篇博客是不甘心我写了这么长的代码,结果一个贱人告诉我存储方式用错了。。。 这里的BFS因为嫌写队列函数太麻烦,所以直接用数组加标识front、rear完成队列的操作,反正节点个数小,使用数组并不会浪费很多空间。 贴上代码纪念一下我曾经二过: #define MAX -1;#define MAX_VERTEX_NUM 20typedef enum {DG,DN,UDG,UDN
再谈图的存储方式(邻接矩阵,邻接表,前向星)
1.邻接矩阵 1.存图思想 使用一个矩阵来描述一个图,对于矩阵的第i行第j列的值,表示编号为i的顶点到编号为j的顶点的权值。 2.代码实现 // 最大顶点数const int V = 1000;// 邻接矩阵的定义// mat[i][j] 表示 顶点'i'到顶点'j'的权值int mat[V][V];// 邻接矩阵的初始化操作// 假设权值为零表示没有该边memset(ma

数据结构——图的数组实现(邻接矩阵表示法)
Graph 基本知识这里不做介绍,可以去看<DSAA>或者<algorithm>.这里主要给出图的C语言实现。 首先我们要对图进行“抽象”,具体的找出关键能够描述图的关键信息,这里我简单的选取了vertex和edge,就是节点和节点所连同的路径。 下面是基于数组描述节点间关系的实现 graph.h /***************************

图的深度优先搜索(邻接矩阵)
Problem Description 给出图的顶点数和顶点与顶点之间的连接关系,请输出用邻接矩阵存储的图的深度优先搜索顶点序列。 Input 输入的第一行是一个整数T表示测试示例的数目,每组示例的第一行有两个数m(2<=m<=10)和n(1<=n<=m*(m-1)/2),m表示顶点的个数(顶点的标号从1-m),n表示边的个数。下面n行的每行表示一条边。后面一行是一个数k,k表示需要
【Python-图结构准备】“pickled object“、 调整邻接矩阵使其对称、图加自环 图邻接矩阵归一化、稀疏邻接矩阵格式转换
引言:python代码学习,本博客对python的"pickled object" (腌制对象,也叫序列化对象), 调整邻接矩阵使其对称、图加自环 & 图邻接矩阵归一化、稀疏邻接矩阵格式转换从代码实现的角度进行介绍。我们先引入一段代码,通过这段代码来解释相应的知识点。 with open('data/' + args.dataset + '_mean_' + args.diffusion_mod

求连通分量(无向图,邻接矩阵,BFS)
1、题目: Problem Description 设有一无向图,其顶点值为字符型并假设各值互不相等,采用邻接矩阵表示法存储表示。利BFS用算法求其各连通分量,并输出各连通分量中的顶点。 Input 有多组测试数据,每组数据的第一行为两个整数n和e,表示n个顶点和e条边(0<n<20);第二行为其n个顶点的值,按输入顺序进行存储;后面有e行,表示e条边的信息,每条
广度优先生成树(无向图,邻接矩阵,BFS)
1、题目: Problem Description 设有一连通无向图,其顶点值为字符型并假设各值互不相等,采用邻接矩阵表示法存储表示。利用BFS算法求其广度优先生成树(从下标0的顶点开始遍历),并在遍历过程中输出广度优先生成树的每一条边。 Input 有多组测试数据,每组数据的第一行为两个整数n和e,表示n个顶点和e条边(0<n<20);第二行为其n个顶点的值,按
邻接矩阵遍历(无向图,邻接矩阵,DFS,BFS)
1、题目: Problem Description 有多组数据,每组数据第一行有两个整数n、m,(0<n,m<100),n表示是有n个点(1~n)形成的图,接下来有m行数据,每一行有两个整数(表示点的序号),说明这两点之间有一条边。 Input 分别输出从标号为1点开始深度和广度优先搜索的序列,每个数之后有一个空格。 每组数组分别占一行。 Output
图的邻接矩阵存储方式
图的邻接矩阵的存储方式是用两个数组来表示图。一个一维数组存储图的顶点信息一个二维数组存储图中的边的信息。假设一维数组为vexs[maxvex],二维数组为arc[maxvex][maxvex],maxvex=100。 在无向图中: 若顶点vi与vj之间的权重为w则arc[i][j]=w;若顶点vi与vj之间无连接则arc[i][j]=65535;若顶点vi与vi之间则arc[i][j]=0。

图的基本操作(基于邻接矩阵):图的构造,深搜(DFS),广搜(BFS)
#include <iostream> #include <stdio.h> #include <cstdlib> #include <cstring> #include <string> #include <queue> using namespace std; typedef struct MGraph{ string vexs[10];//顶点向量 int ar
![[数据结构]图邻接矩阵C语言简单实现](https://img-blog.csdn.net/20171201100714457?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdHVkYW9kaWFvemhhbGU=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[数据结构]图邻接矩阵C语言简单实现
Github:(https://github.com/FlameCharmander/DataStructure) 到了图这章确实会比较复杂,因此我想分几个部分,一个是邻接矩阵实现,一个是邻接表实现,然后是基于邻接矩阵的广度优先搜索遍历,基于邻接表的深度优先搜索遍历来讨论。 首先现在大概有几种图的数据结构,一个是邻接矩阵,邻接表,十字链表(有向图),邻接多重表。 我们先来看下邻接矩阵是怎么实现的吧
邻接矩阵图的dfs和bfs
int G[maxn][maxn];int n; //点数int m; //边数int vis[maxn];void init(){memset(G,0,sizeof(G));memset(vis,0,sizeof(vis));for(int i=0; i<m; i++){int u,v;scanf("%d%d",&u,&v);G[u][v] = 1;}}void dfs(int u)
JGraphX生成的通风网络图导出为解算图模型时确保邻接矩阵正确的处理
JGraphX生成的通风网络图,反映了风网的拓扑关系,但是Jgraph中的edge的节点mxcell虽然是正确的,但是其中的Node却不是与label对应的, 其原因可能是由于插入边时的方法问题, 所以在网络图导出为解算图时,应进行如下处理: mxgraph.selectVertices();Object[] vcells = graphComponent.getGraph().g

Prim算法的C语言实现(邻接矩阵)
#include <stdio.h>#include <stdlib.h>#include <malloc.h>#include <string.h>#define MAX 100 // 矩阵最大容量#define INF (~(0x1<<31)) // 最大值(即0X7FFFFFFF)#define isLetter(a) ((
基于邻接矩阵的朴素Dijkstra单源最短路C++极简实现
基于邻接矩阵的Dijkstra实现 最近刷题遇到了1个最短路算法的题: https://leetcode-cn.com/problems/network-delay-time/,我就在想有没有一个最佳的通用的朴素Dijkstra的C++实现。看了一些解答,有一个很经典,核心逻辑20行左右,没有任何冗余操作,像是搞ACMer同学的风格。核心实现如下: #include <vector>#inc