赵世钰专题

▶《强化学习的数学原理》(2024春)_西湖大学赵世钰 Ch5 蒙特卡洛方法【model-based ——> model-free】
PPT 截取必要信息。 课程网站做习题。总体 MOOC 过一遍 1、视频 + 学堂在线 习题 2、 过 电子书 是否遗漏 【下载:本章 PDF GitHub 页面链接 】 【第二轮 才整理的,忘光了。。。又看了一遍视频】 3、 过 MOOC 习题 看 PDF 迷迷糊糊, 恍恍惚惚。 学堂在线 课程页面链接 中国大学MOOC 课程页面链接 B 站 视频链接 PPT和书籍下载网址: 【Gi

▶《强化学习的数学原理》(2024春)_西湖大学赵世钰 Ch4 值迭代 与 策略迭代 【动态规划 model-based】
PPT 截取必要信息。 课程网站做习题。总体 MOOC 过一遍 1、视频 + 学堂在线 习题 2、过 电子书 补充 【下载: 本章 PDF 电子书 GitHub】 [又看了一遍视频。原来第一次跳过了好多内容。。。] 3、总体 MOOC 过一遍 习题 学堂在线 课程页面链接 中国大学MOOC 课程页面链接 B 站 视频链接 PPT和书籍下载网址: 【GitHub 链接】 总述:
▶《强化学习的数学原理》(2024春)_西湖大学赵世钰 Ch4 值迭代 与 策略迭代 【动态规划 算法】
PPT 截取必要信息。 课程网站做习题。总体 MOOC 过一遍 1、视频 + 学堂在线 习题 2、过 电子书 补充 【下载: 本章 PDF 电子书 GitHub】 [又看了一遍视频。原来第一次跳过了好多内容。。。] 3、总体 MOOC 过一遍 习题 学堂在线 课程页面链接 中国大学MOOC 课程页面链接 B 站 视频链接 PPT和书籍下载网址: 【GitHub 链接】 总述:

⭐ ▶《强化学习的数学原理》(2024春)_西湖大学赵世钰 Ch3 贝尔曼最优公式 【压缩映射定理】
PPT 截取必要信息。 课程网站做习题。总体 MOOC 过一遍 1、视频 + 学堂在线 习题 2、过 电子书,补充 【下载:本章 PDF 电子书 GitHub 界面链接】 [又看了一遍视频] 3、总体 MOOC 过一遍 习题 学堂在线 课程页面链接 中国大学MOOC 课程页面链接 B 站 视频链接 PPT和书籍下载网址: 【GitHub 链接】 强化学习的最终目标: 寻求最优策略

▶《强化学习的数学原理》(2024春)_西湖大学赵世钰 Ch2 贝尔曼公式
PPT 截取有用信息。 课程网站做习题。总体 MOOC 过一遍 1、学堂在线 视频 + 习题 2、相应章节 过电子书 复习 GitHub界面链接 3、总体 MOOC 过一遍 学堂在线 课程页面链接 中国大学MOOC 课程页面链接 B 站 视频链接 PPT和书籍下载网址: 【github链接】 onedrive链接: 【书】 【课程PPT】 文章目录 计算 return方法一:

西湖大学赵世钰老师【强化学习的数学原理】学习笔记1节
强化学习的数学原理是由西湖大学赵世钰老师带来的关于RL理论方面的详细课程,本课程深入浅出地介绍了RL的基础原理,前置技能只需要基础的编程能力、概率论以及一部分的高等数学,你听完之后会在大脑里面清晰的勾勒出RL公式推导链条中的每一个部分。赵老师明确知道RL创新研究的理论门槛在哪,也知道视频前的你我距离这个门槛还有多远。 本笔记将会用于记录我学习中的理解,会结合赵老师的视频截图,以及PDF文

西湖大学赵世钰老师【强化学习的数学原理】学习笔记2节
强化学习的数学原理是由西湖大学赵世钰老师带来的关于RL理论方面的详细课程,本课程深入浅出地介绍了RL的基础原理,前置技能只需要基础的编程能力、概率论以及一部分的高等数学,你听完之后会在大脑里面清晰的勾勒出RL公式推导链条中的每一个部分。赵老师明确知道RL创新研究的理论门槛在哪,也知道视频前的你我距离这个门槛还有多远。 本笔记将会用于记录我学习中的理解,会结合赵老师的视频截图,以及PDF文
西湖大学赵世钰老师【强化学习的数学原理】学习笔记-1、0节
强化学习的数学原理是由西湖大学赵世钰老师带来的关于RL理论方面的详细课程,本课程深入浅出地介绍了RL的基础原理,前置技能只需要基础的编程能力、概率论以及一部分的高等数学,你听完之后会在大脑里面清晰的勾勒出RL公式推导链条中的每一个部分。赵老师明确知道RL创新研究的理论门槛在哪,也知道视频前的你我距离这个门槛还有多远。 本笔记将会用于记录我学习中的理解,会结合赵老师的视频截图,以及PDF文

【强化学习的数学原理-赵世钰】课程笔记(九)策略梯度方法(Policy Gradient Method)
目录 一.policy gradient 的基本思路(Basic idea of policy gradient) 二.定义最优策略的 metrics,也就是 objective function 是什么 三.objective function 的 gradient 四.梯度上升算法(REINFORCE) 五.总结 上节课介绍了 value function approxim

【强化学习的数学原理-赵世钰】课程笔记(二)贝尔曼公式
【强化学习的数学原理-赵世钰】课程笔记(二)贝尔曼公式 一. 内容概述 1. 第二章主要有两个内容 (1)一个核心概念:状态值(state value):从一个状态出发,沿着一个策略我所得到的奖励回报的平均值。状态值越高,说明对应的策略越好。之所以关注状态值,是因为它能评价一个策略的好坏。 (2)基本工具:贝尔曼公式(the Bellman equation): 用于分析状态值,描述所有

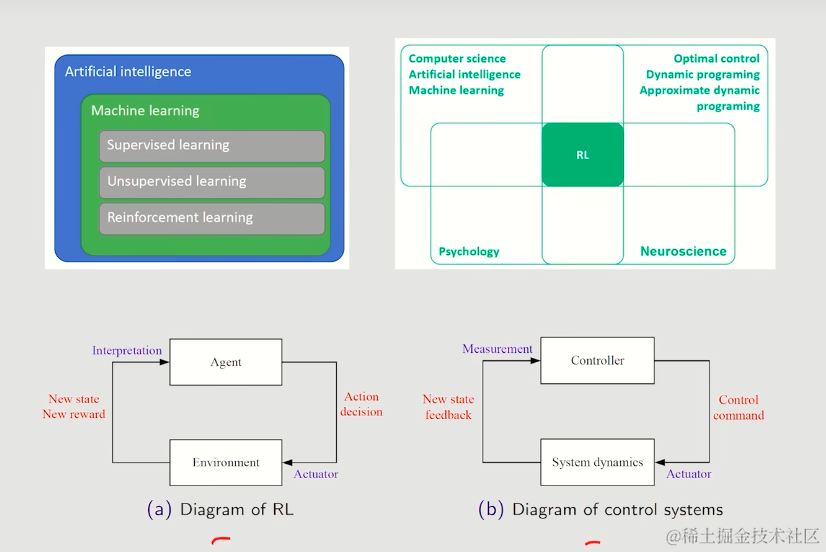
【强化学习的数学原理-赵世钰】课程笔记(一)基本概念
目录 一. 内容概述1. 通过案例介绍强化学习中的基本概念2. 在马尔可夫决策过程(MDP)的框架下将概念正式描述出来 二. 通过案例介绍强化学习中的基本概念1. 网格世界(A grid world example)2. 状态(State)3. 动作(Action)4. 状态转移(State transition)5. 策略(Policy)6. 奖励(Reward)7. 轨迹和收益(Traj

【强化学习的数学原理-赵世钰】课程笔记(七)时序差分方法
一.内容概述 第五节课蒙特卡洛(Mento Carlo)方法是全课程中第一次介绍 model-free 的方法,本节课的 Temporal-difference learning(TD learning)是我们要介绍的第二种 model-free 的方法。基于蒙特卡洛(Mento Carlo)的方法是一种非递增(non-incremental)的方法,Temporal-difference le

【强化学习的数学原理-赵世钰】课程笔记(六)随机近似与随机梯度下降
目录 一.内容概述 二.激励性实例(Motivating examples) 三.Robbins-Monro 算法(RM 算法): 1.算法描述 2.说明性实例(llustrative examples) 3.收敛性分析(Convergence analysis) 4.在平均值估计中的应用(Application to mean estimation) 四.随机梯度下降(stoch

强化学习-赵世钰(二):贝尔曼公式/Bellman Equation【用于计算State Value:①线性方程组法、②迭代法】、Action Value【据状态值求解得到;用来评价action优劣】
State Value :the average Return that an agent can obtain if it follows a given policy/π【给定一个policy/π,所有可能的trajectorys得到的所有return的平均值/期望值: v π ( s ) ≐ E [ G t ∣ S t = s ] v_\pi(s)\doteq\mathbb{E}[G_t|