质控专题

消化学科的领军人物陈烨教授在会议上作了《幽门螺杆菌的规范检测与质控》的专题报告
由广东省药学会主办的“第十九届消化疾病诊疗会暨胃肠疾病药物临床研究交流会”于2024年8月8日-9日在广东省深圳市召开。陈烨教授,作为消化学科的领军人物、中华医学会消化病学分会的常务委员,以及全国幽门螺杆菌学组的组长,在会议上作了《幽门螺杆菌的规范检测与质控》的专题报告。 知识点一 尿素呼气试验(UBT) 是临床最常用的非侵入性诊断方法,具有操作简便、准确性较高和不受H.pylori在

全外显子测序分析流程1 - Fastq质控与去接头、低质量和引物序列
全外显子测序分析流程1 - Fastq质控与去接头、低质量和引物序列 1. 运行实例 # -d 样本根目录# -s 样本名称python trim_fastq.py -d /result/WES/sample -s sample 2. fastqc质控报告与去接头、低质量序列主程序 对raw fastq和clean fastq生成质控QC报告trim_galore去接头、低质量序列和

生信学习笔记:测序数据质控
文章目录 测序数据质控1.原始数据统计2.质控数据统计 测序数据质控 Illumina 测序属于第二代测序技术,单次运行能产生数十亿级的reads,如此海量的数据无法逐个展示每条read的质量情况;运用统计学的方法,对所测序列进行统计和质控,可以从宏观上直观地反映出样本的文库构建质量和测序质量。 1.原始数据统计 1)原始数据获得 Illumina 平台通过将测序图像信号

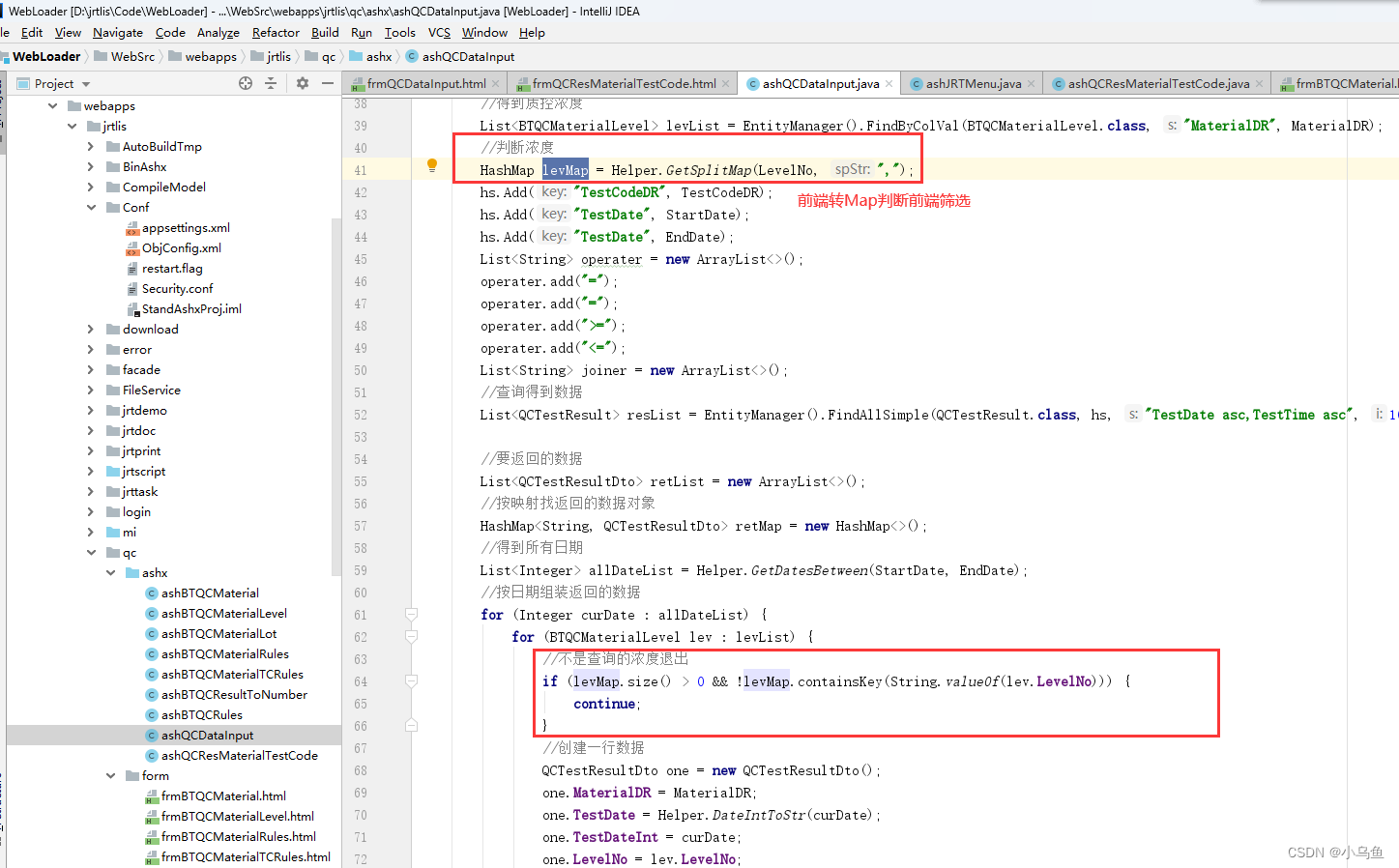
windows ubuntu 子系统:肿瘤全外篇,2. fq 数据质控,比对。
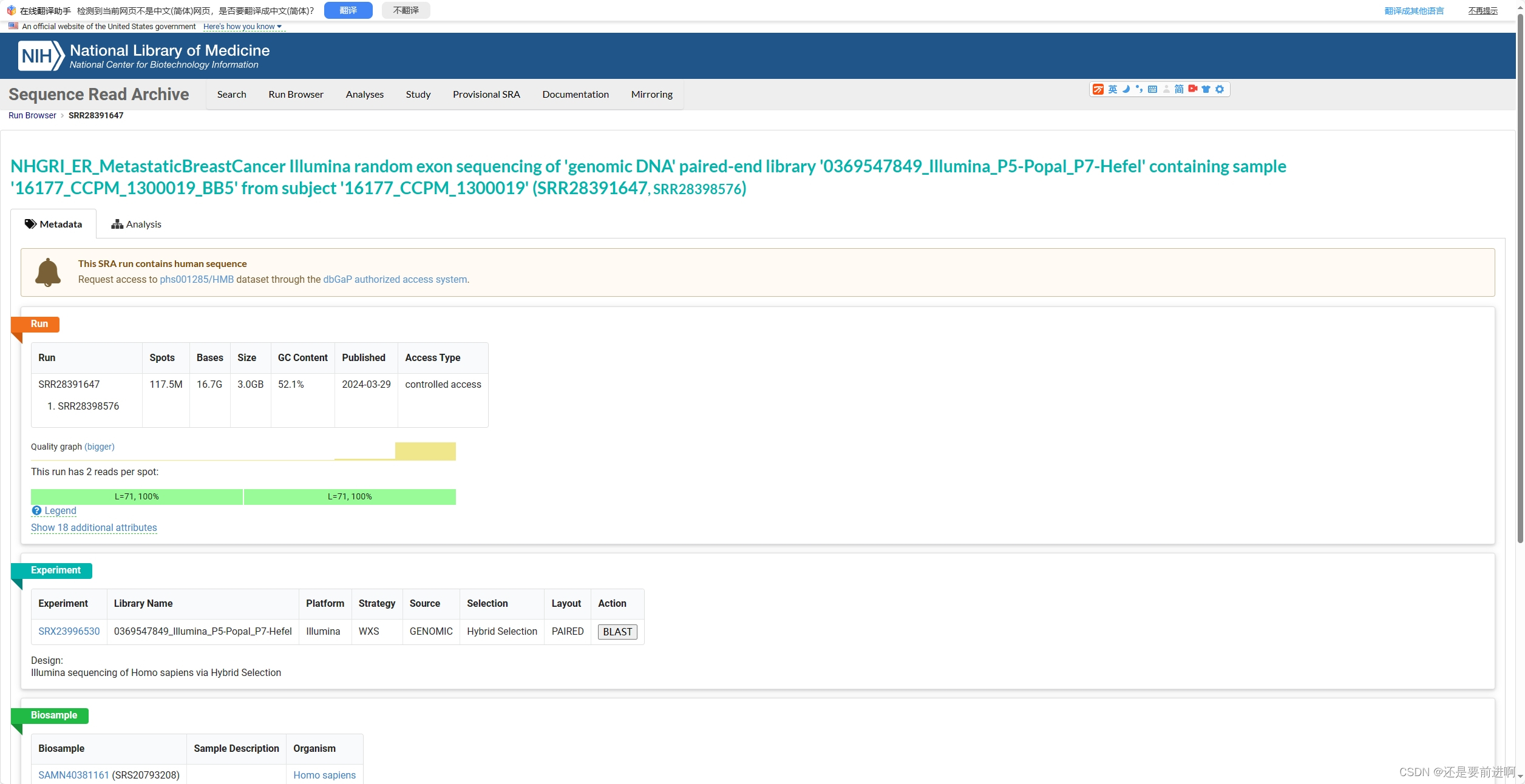
首先我们先下载一组全外显子测序数据。nabi sra库,随机找了一个。 来自受试者“16177_CCPM_1300019”(SRR28391647, SRR28398576)的样本“16177_CCPM_1300019_BB5”的基因组DNA配对端文库“0369547849_Illumina_P5-Popal_P7-Hefel”的Illumina随机外显子测序 下载下来,转为两个配对的fq

单细胞RNA测序(scRNA-seq)Cellranger流程入门和数据质控
单细胞RNA测序(scRNA-seq)Cellranger流程入门和数据质控 单细胞RNA测序(scRNA-seq)基础知识可查看以下文章: 单细胞RNA测序(scRNA-seq)工作流程入门 单细胞RNA测序(scRNA-seq)细胞分离与扩增 1. 单细胞RNA-seq样本数据说明 样本数据来源文章:Acquired cancer resistance to combination

医保dip质控系统如何实现医保控费?
医保DIP质控系统通过数据分析和监管手段实现医保控费的目标。下面是一些常见的实现方式: 医疗服务审核:系统对医疗机构提供的医疗服务进行审核,确保医疗行为符合规范和政策要求。例如,对门诊病历、住院病历等进行审核,发现存在的问题和不合理的费用,并及时纠正。 费用管理和控制:系统对医疗费用进行管理和控制,包括限制某些高价药品或耗材的使用,设定费用上限或支付比例等。通过设定规则和限制条件,确保医疗费

dRep-基因组质控、去冗余及物种界定
文章目录 Install依赖关系 常用命令常见问题pplacer线程超过30报错当比较基因组很多(>4096)有了Bdv.csv文件后无需输入基因组list 超多基因组为什么需要界定种?dRep重要概念次级ANI的选择Minimum alignment coverage3. 选择有代表性的基因组4. 使用贪婪的算法5. 基因组完整性的重要性7. 基因组比较算法概述8. 对非细菌基因组进行比较

单病种上报系统如何促进医院单病种质控管理
米软单病种上报系统自面市以来,一直以产品实力取胜,在助力医院实现病例数据快速、准确上报后,米软将自我优化重心投向了单病种医疗质量控制。 从填报过程监管,到结果分析、预警整改,米软重视质控的数据管理及应用。通过单病种上报系统,将线下、线上断层管理部分打通贯穿,最终实现单病种管理的质控闭环,促进医院提升医疗质量管理水平。 自国家卫健委将单病种质量管控陆续扩展至51个病种以来,全国仍有为数不少的

RNA-seq流程学习笔记(9)-使用RSeQC软件对生成的BAM文件进行质控
参考文章: 用RSeQC对比对后的转录组数据进行质控 高通量测序质控及可视化工具包RSeQC RSeQC使用笔记 1. 质控的原因及相关软件 在A survey of best practices for RNA-seq data analysis里面,提到了人类基因组应该有70%~90%的比对率,并且多比对read(multi-mapping reads)数量要少。另外比对在外显子和所比对链

linux质控命令,Linux下microRNA质控-cutadapt安装
如果Linux系统已安装pip或conda,cutadapt的安装相对简便一些,示例如下: 1.pip安装 pip install --user --upgrade cutadapt 添加环境变量 echo 'export PATH=$PATH:/your path/cutadapt-1.10/bin ' >> ~/.bashrc 2.conda安装 conda install -c bioco

谈思生物医疗直播 | 霍德生物研发中心负责人王安欣博士“iPSC衍生神经细胞产品全悬浮自动化工艺及特殊质控方法开发”
iPSC通过人体来源的终端体细胞重编程而来,其衍生细胞产品的生产与质控面临着诸多挑战,但也解决了许多自体细胞治疗的不稳定性和高成本等产业化难点。例如自体细胞不仅供体之间的差异对产品质量可能造成影响,即使同一个供体,体细胞的异质性对细胞产品的质量和功能也有较大影响。iPSC可以做到单细胞克隆来源的稳定的细胞库,通过从WCB进行定向分化实现大规模批次生产和质控,批次之间差异可以非常小。iPSC向人体终

医院上线单病种上报接口及质控管理的必然性
随着国家持续重视及投入医疗卫生与健康事业,我国医疗卫生水平显著提升,相关标准体系得以建立、完善。而提高医疗技术能力和医疗质量是医疗卫生工作的核心,是实施健康中国战略、构建优质高效医疗卫生服务体的基础。 为什么说单病种质控管理很重要? 为什么说单病种上报及质控管理,必须使用接口系统? 国家平台直报与接口系统对比 单病种上报数据将如何应用于医疗大数据分析,是不少医院在单病种质控通知发布
基因型填充前的质控条件简介
欢迎关注”生信修炼手册”! 影响基因型填充准确率的因素有很多,比如分型结果的质量,填充软件的选择,reference panel的选择,样本量的大小, SNP的密度等等。 为了提高填充的准确率,我们需要在填充前进行质量过滤。对于原始的分型结果,可以根据一些条件进行筛选和过滤,得到高质量的分型结果,用于后续的填充。 分型结果本质上是一张由样本和SNP位点构成的表格,对应的过滤手段也分成了两个大的方
linux质控命令,Biostar_handbook||Charpter_6789_数据的格式_获取_质控_seqkit
Charpter6:数据的格式Data Formats 常用数据库 NCBI EBI Uniprot Phytozome Ensemble plants TAIR PlantGDB PlantTFDB 植物转录因子数据库 这些是我目前常用的一些数据库,可以看出来我是做植物的。其实植物领域还有许多重要的数据库,更不必说动物的了,各个物种都能拿出来做个数据库。数据这么多,如何更加高效的从数据库中实现