计算方法专题

IBS和IBD的区别和计算方法介绍
大家好,我是邓飞。 今天介绍一下IBS和IBD的区别: IBS(肠易激综合症)和IBD(炎症性肠病)是两种不同的消化系统疾病,主要区别如下: IBS(Irritable Bowel Syndrome):是一种功能性肠道疾病,主要表现为腹痛、腹胀、腹泻或便秘,症状通常与饮食、压力和心理因素相关,没有明显的器质性病变。 IBD(Inflammatory Bowel Disease):是一组

组合c(m,n)的计算方法
问题:求解组合数C(n,m),即从n个相同物品中取出m个的方案数,由于结果可能非常大,对结果模10007即可。 共四种方案。ps:注意使用限制。 方案1: 暴力求解,C(n,m)=n*(n-1)*...*(n-m+1)/m!,n<=15 ; int Combination(int n, int m) { const int M = 10007; int

计算方法——插值法程序实现(一)
例题 给出的函数关系表,分别利用线性插值及二次插值计算的近似值。 0.10.20.30.40.51.1051711.2214031.3498591.4918251.648721 参考代码一:Python代码实现(自编码) import math""":parameter用于计算插值多项式的系数"""def Parameters(data_x,data_y,size):param
音频帧率计算方法(为防止以后忘了)
采样率 sampling = 44100 格式(编码字节数、采样一位所占的字节数) format = s16(格式)=16(bit) 声道数 channels = 2 一次采样(一秒中所占的位数)TotalBit = sampling * channels * format = 1411200 一次采样(一秒中所占的字节数)TotalByte = TotalBit/8 = 17640

常用的相似度计算方法----欧式距离、曼哈顿距离、马氏距离、余弦、汉明距离、切比雪夫距离、闵可夫斯基距离、马氏距离
在深度学习以及图像搜索中,经常要对特征值进行比对,得到特征的相似度,常见的特征值比对方法有汉明距离、余弦距离、欧式距离、曼哈顿距离、切比雪夫距离、闵可夫斯基距离、马氏距离等,下面对各种比对方法分别进行介绍。 目录 1汉明距离 2余弦相似度 3欧式距离 4曼哈顿距离 5切比雪夫距离 6闵可夫斯基距离 7马氏距离 1汉明距离 汉明距离/Hamming Distance也能用来计算两
BMS中SOC的计算方法
在电池管理系统(BMS)中,状态的充电(SOC,State of Charge)的计算方法主要有以下几种: 1. 库仑计数法(Coulomb Counting) 原理:通过测量电流并积分来计算SOC。公式: \text{SOC} = \text{SOC}_0 + \frac{1}{C} \int I(t) dtSOC=SOC0+C1∫I(t)dt 其中,CC是电池的额定容量,I(t)I(t

【数值计算方法】蒙特卡洛方法积分的Python实现
原文:https://www.cnblogs.com/aksoam/p/18378332 原理不做赘述,参见【数值计算方法】数值积分&微分-python实现 - FE-有限元鹰 - 博客园,直接上代码,只实现1d,2d积分,N维积分的蒙特卡洛方法也类似. 代码 from typing import Callable,Union,Listdef MonteCarloInt2d(f:Calla

太阳方向角/高度角/赤纬角/太阳时角/真平太阳时差/理论计算方法(matlab)
1. 理论学习 方向角,高度角计算公式 如图,直观地描述了方位角(圆盘上红色夹角)与高度角(黄色线与圆盘的夹角) 赤纬角计算公式 地球赤道平面与太阳和地球中心的连线之间的夹角 如图所示,23度那个. 时角计算公式 太阳时角是指从观测点的天球子午圈沿天赤道量至太阳所在时圈的角距离。它用来表示太阳在天空中的位置。 太
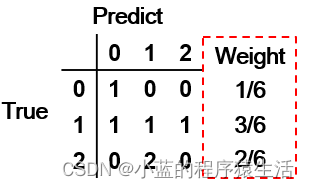
多分类问题中评价指标F1-Score 加权平均权重的计算方法
多分类问题中评价指标F1-Score 加权平均权重的计算方法 众所周知,F1分数(F1-score)是分类问题的一个衡量指标。在分类问题中,常常将F1-score作为评价分类结果好坏的指标。它是精确率和召回率的调和平均数,值域为[0,1]。 F 1 = 2 ∗ P ∗ R P + R F_1=2*\frac{P*R}{P+R} F1=2∗P+RP∗R 其中,P代表着准确率(

推荐系统三十六式学习笔记:原理篇.近邻推荐09|协同过滤中的相似度计算方法有哪些?
目录 相似度的本质相似度的计算方法:1、欧式距离2、余弦相似度3、皮尔逊相关度4 、杰卡德(Jaccard)相似度 总结 相似度的本质 推荐系统中,推荐算法分为两个门派,一个是机器学习派,一个是相似度门派。机器学习派是后起之秀,而相似度门派则是泰山北斗。 近邻推荐,近邻并不一定只是在三维空间下的地理位置的近邻,也可以是高维空间的近邻。 近邻推荐的核心就是相似度计算方法的选择,由

KMP算法next数组的手工计算方法
KMP是三位大牛:D.E.Knuth、J.H.Morris和V.R.Pratt同时发现的。其中第一位就是《计算机程序设计艺术》的作者!! KMP算法要解决的问题就是在字符串(也叫主串)中的模式(pattern)定位问题。说简单点就是我们平时常说的关键字搜索。模式串就是关键字(接下来称它为P),如果它在一个主串(接下来称为T)中出现,就返回它的具体位置,否则返回-1(常用手段)。 1.next数组
基于STM32的各种数学函数优化计算方法(代码开源)
前言:本文为手把手教学 STM32 的数学计算公式优化方法的教程,本教程的 MCU 使用 STM32F103ZET6 。本篇博客将使用非传统数学库计算手段进行各种数学函数的计算,优化的数学计算包括:sin()、cos()、arctan()、arcsin() 与 1/sqrt()。作为研发的项目产品,实现产品功能往往是很容易的,最重要的核心其实是产品功能的优化,以最优的控制亦或是消耗时间去完成制定的

概率论中两种特殊的 E(x) 计算方法:先求积分再求导,或者先求导再求积分
为了求解某个函数 ( E(x) ),可以使用两种方法:先求积分再求导,或者先求导再求积分。这里我们以数列求和公式为例,分别介绍这两种方法。 1. 先求积分再求导 假设我们有一个函数 ( f(x) ) 的级数展开: E ( x ) = ∑ n = 1 ∞ a n x n E(x) = \sum_{n=1}^{\infty} a_n x^n E(x)=n=1∑∞anxn 我们可以通过对
概率论中,积分和再求导的计算方法
为了求解级数 1 + 2 2 q + 3 2 q 2 + … 1 + 2^2q + 3^2q^2 + \ldots 1+22q+32q2+… 的和,可以使用积分再求导的方法。我们考虑如下步骤: 1. 定义函数并进行积分 我们先定义一个函数 S ( q ) S(q) S(q): S ( q ) = ∑ n = 1 ∞ n 2 q n − 1 S(q) = \sum_{n=1}^{\inf

(P107)abcbank框架搭建(四):MD5类使用,包尾作用和包尾计算方法,密码加密方法IDEA+MD5
文章目录 1.MD5类使用2.包尾作用和包尾计算方法3.密码加密方法IDEA+MD5 1.MD5类使用 网站上的使用的MD5 16bit大实际上是32bit大的中间的16个字符 eg:P107\ABCBank\BankClient\main.cpp #include "Server.h"#include "../Public/MD5.h"#include <std

CUDA中线程索引计算方法
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 本文链接: https://blog.csdn.net/hujingshuang/article/details/53097222 由于项目需要用到GPU,所以最近开始学习CUDA编程模型,刚开始接触,先搞清楚线程关系和内存模型是非常重要的,但是发现书上和许

碳实践|如何快速掌握组织碳核算中范围3的计算方法
前面我们提到进行企业组织层面碳核算步骤、界定组织排放边界时,按照温室气体核算体系“GHG Protocol”标准,将碳排放的范围分为范围1、范围2和范围3,前面的内容也进行了相关介绍。 碳实践|基于“界、源、算、质、查”五步法,实现企业组织碳核算 范围3排放相对来说更难计算和控制,因为它们由第三方(如供应链成员)产生,同时范围3排放也是碳排放中的主要排放来源。所以本文对范围3碳排放核算方法进行
资金流入流出计算方法
资金流入流出计算方法 我们是按照交易所主动成交单的成交方向计算流入还是流出。目前交易所都是采用Maker-Taker成交机制,我们的资金流数据是按照逐笔数据计算而来。逐笔数据中,我们记录的是Taker的成交方向。因此,如果Taker成交是买入则计为资金流入,等于成交价格乘以成交量;如果Taker成交是卖出则计为资金流出,等于成交价格乘以成交量。 通俗的讲就是主动成交的买单就计为流入,反之

【数值计算方法】雅可比解线性方程
废话少说,直接上干货。 #include <stdio.h>#include <stdlib.h>#include <math.h>#define MaxSize 100double A[MaxSize][MaxSize]; //系数矩阵double B[MaxSize]; //系数矩阵double C[MaxSize][MaxSize]; //去对角线矩阵d

时间复杂度的表示、分析、计算方法……一文带你看懂时间复杂度!
如果你还在发愁究竟怎么计算时间复杂度和空间复杂度,那你是来对地方了! 名词解释: 在计算机科学中,时间复杂性,又称时间复杂度,算法的时间复杂度是一个函数,它定性描述该算法的运行时间。这是一个代表算法输入值的字符串的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的低阶项和首项系数。使用这种方式时,时间复杂度可被称为是渐近的,亦即考察输入值大小趋近无穷时的情况。 时间复杂度的表

转载:卷积算子计算方法(卷积运算)
原链接:http://blog.csdn.net/niuwei22007/article/details/48969709可以查看更多文章 卷积操作是对图像处理时,经常用到的一种操作。它具有增强原信号特征,并且能降低噪音的作用。 那么具体是如何计算的呢?且看下文。 待处理图像数据(5*5): 卷积核:(3*3) A = [17 24 01 08 15