白手起家专题

2024不起眼的“致富”野路子,不想打工了,做做这些暴利创业项目。2024个人创业做什么项目好;最适合白手起家的创业项目
经济大环境差,并不代表就没有机会。相反,主流经济不好正是另一些人所看重的千载难逢的机会。就像股票市场一样,有人靠做多赚钱,有人靠做空赚钱。下面我们就来分析一下哪些行业会在这个时候崛起。 首先二手行业会迅速崛起,比方说咖啡厅倒闭的平均周期是7个月,想开咖啡厅的创业者又此起彼伏,导致咖啡机就很贵。所以二手公司就会以1.5折的价格收购所有设备,然后在闲鱼上以3折的价格卖给这些人,含泪赚一倍。
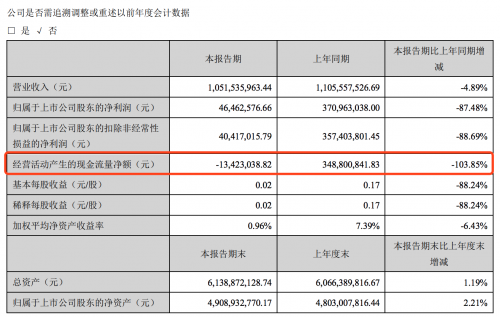
从最年轻的白手起家富豪到身陷囹圄,这个80后创始人也就用了3年
创始人被刑拘、多名高管被带走、公司被证监会立案调查、业绩大幅下滑……恺英网络正在遭遇“多事之秋”。 回到四年前,恺英网络也算是一家明星企业,2015年4月借壳泰亚股份登陆A股,曾连拉12个涨停板。其创始人王悦在33岁就以近70亿元的身价登上“2016全球胡润富豪榜”,被称为“白手起家的中国最年轻富豪”。 公开信息显示,恺英网络在上市之前已经连续三年实现盈利,2015年借壳上市时还与泰

sql~~白手起家~~
目录 SQL的用途: SQL中的字符串类型定义 SQL的数值类型的定义 sql有三种语言 1.DML---数据操纵语言 2.DDL---数据定义语言 3.DCL---数据控制语言 SQL的用途: SQL中的字符串类型定义 SQL的数值类型的定义 SQL的日期类型的定义 SQL的命名 SQL的三种语言类型 1.DML---数据操纵
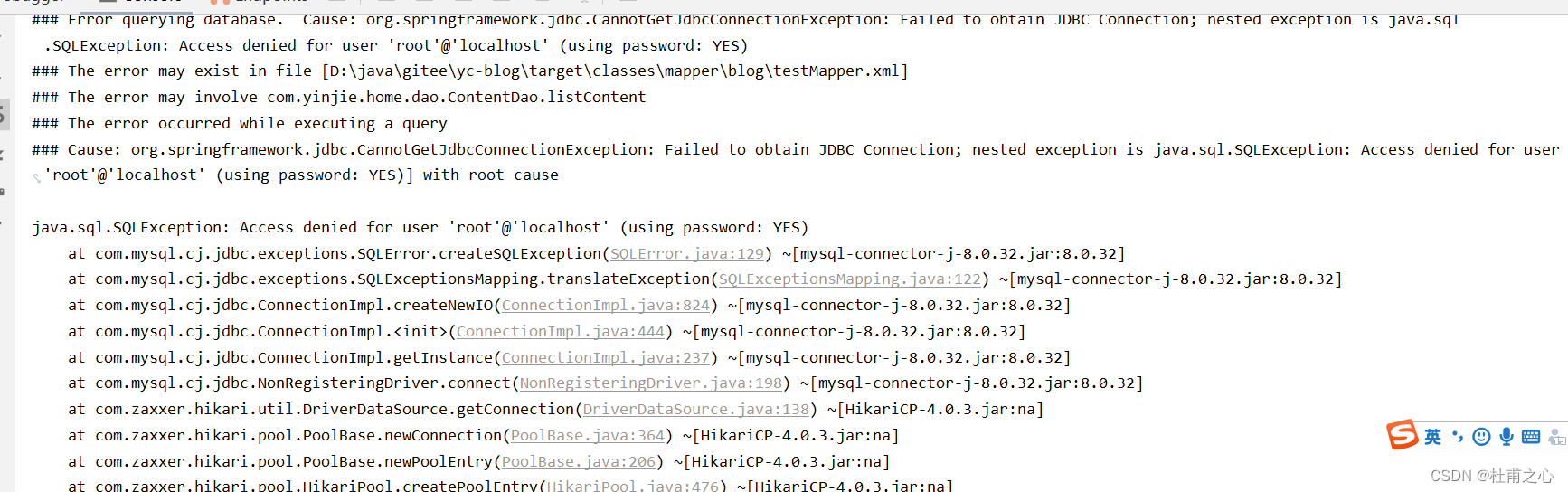
yc博客项目创建-白手起家
初始化项目 1、码云创建代码库 2、下载码云项目到本地 3、IDEA直接生成springboot项目 接入mysql 1、配置文件 2、代码配置 启动项目 访问项目 访问连接: http://localhost:8089/yc-blog/index/listlistContent 注意点:server.servlet.conte
三个二十多岁的年轻人白手起家,一年半跻身业内一线
现如今互联网行业竞争如此惨烈,不仅有三巨头,还有许多的大企业也加入了互联网的大家庭。 2017年,三个二十多岁的年轻人选择了白手起家,成立了一家深耕电子竞技内容生态的文化传播公司。 “大鹅文化”的公司,成立不足一年半,已完成三轮总计超过1亿的巨额融资。自身业务成果与公司实力也足以跻身电竞行业的头部阵营,获得了资本与市场的多方认可。 大鹅文化的创始人王智开、王宇阳、何惠惠,出身于80年代末

说几个白手起家的高手
今天给你们介绍几个获取额外信息和认知的渠道,他们都是各个垂直领域的资深玩家、行业大佬,公司高管,也都是有本事的狠人。 他们分享的内容涵盖了副业探索、抖音运营、商业变现、私域流量、案例分析等等,有一定的启发性。 如果你平时获取信息的渠道有限,可以关注一下他们的公众号或围观他们的朋友圈分享。 顺哥有道说一说 推荐理由:顺哥是有10多年线上和线下实战经验的营销操盘手,他曾经在没有资金、资源和人脉的

李开复:白手起家的10个步骤
李开复:白手起家的10个步骤 有同学问如果专业没兴趣怎么办?1)寻找专业里面可能有兴趣的小专业,寻找专业和其他有兴趣的专业的交集;2)如果仍没兴趣,换一个有兴趣的领域,毕业后考研或直接申请那个领域的工作,不过多咨询别再犯选择的错误了。3)无论有兴趣或没有,都要尽力去读。如果成绩太差,会被认为责任心和态度有问题。 ——摘自2月21日李

7位白手起家的亿万富豪的7大独特做事准则 凤凰科技02-0411:46 原标题:7位白手起家的亿万富豪的7大独特做事准则 那些白手起家的亿万富翁企业家是否有一些独特的思维方式和做事准则,从而让自己获得
7位白手起家的亿万富豪的7大独特做事准则 凤凰科技 02-04 11:46 原标题:7位白手起家的亿万富豪的7大独特做事准则 那些白手起家的亿万富翁企业家是否有一些独特的思维方式和做事准则,从而让自己获得从人群中脱颖而出的独特优势呢?作为一个连续创业者和作家,我的整个职业生涯都被这个问题所深深吸引,我读过数不清的亿万富翁企业家的传记,研究了他们的一些共同点,并且亲自采访

创业白手起家也须要条件——北漂18年(14)
有种非常市井说法叫“平地抠饼”意思是:平地抠饼,意思也就为从一块平地上画一个圆,演员在里头表演,就像抠出一个饼来。有自食其力、自力更生、白手起家之意。创业非常多时候就是要白手起家。所以才更须要创新。 选址是第一步,也是我犯第一个错误。 回到北京中关村之后,我先租了房子,六郎庄有的是,然后直奔现代电子市场租柜台。 选这里是考虑三个因素。一是算是在中关村大街上(要往西走个十多米。站在中关村大街上

她白手起家创业开3D墙秀坊,年收入达50多万
一个只有技校文评的懵懂少女自费念完大学,平凡的80后少女王燕用一年时间成就了自己的非凡事业,实现了人生的价值,诠释出一段白手起家的创业传奇。 2008年,王燕完成了技校的学业,当时老家的经济还并不发达,工资水平也不高,姐姐工作后每月的收入不过500元。看着年迈的双亲,想到还有一个上学的弟弟,19岁的王燕也决定和姐姐一起挑起家庭的重担,于是王燕也选择了去外地打工挣钱。 王燕来到深圳的一个窗帘
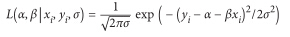
白手起家学习数据科学 ——线性回归之“简单线性回归篇”(十一)
在前面的章节中,我们使用相关系数函数测量2个变量之间线性相关的强度,对于大多数应用只是知道线性相关是不够的,我们想要理解这个关系的本质,我们会使用简单线性回归来加以理解。 The Model 有2个变量,一个是DataSciencester网站用户的数量,另一个是每个用户在这个网站上每天所花费的时间。假设你自己确信有更多朋友引起人们在这个网站上花费更多的时间。 Engagement部门的副总
白手起家学习数据科学 ——Naive Bayes之“测试模型篇”(十)
这有一个好的数据集 [ SpamAssassin public corpus ]。 我们使用前缀为20021010的文件(在Windows中你可能需要像7-Zip的软件用于解压它们)。 在抽取数据之后(例如,放到C:\spam中),你得到3个文件夹:spam,easy_ham和hard_ham,每个文件夹包含许多邮件,每个邮件包含在单独的文件中,为了让事情变得变得简单些,我们只考虑每个邮件的标

白手起家学习数据科学 ——Naive Bayes之“背后的思想”(十)
如果人们不能互相沟通,那么社会网络就不是一个好的网络。基于此,DataSciencester网站有个大众的特点,允许用户发送消息给其他的用户。大多数用户是有责任的公民,他们只发送受欢迎的“最近好么”(how is it going?)消息,其他一些用户发送极端的垃圾邮件,关于致富方案、无需开处方的药物等,你的用户开始抱怨,所以Messaging部门的副总要求你使用数据科学找到一个方法过滤这些垃圾邮
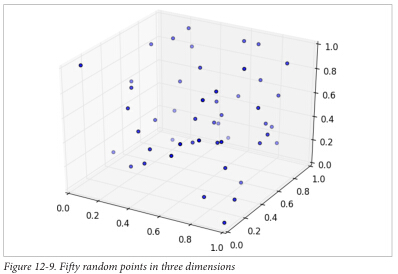
白手起家学习数据科学 ——k-Nearest Neighbors之“维度诅咒”(九)
维度诅咒(The Curse of Dimensionality) KNN在高维空间运行会出现”维度诅咒”的问题,那是因为在高维空间太广阔,高维空间的数据点不趋向接近另外的数据点。有一个办法可以证明这一点,随机产生很多对d维度的向量,然后计算每对的向量距离。 产生随机数据点: def random_point(dim):return [random.random() for _ in ran
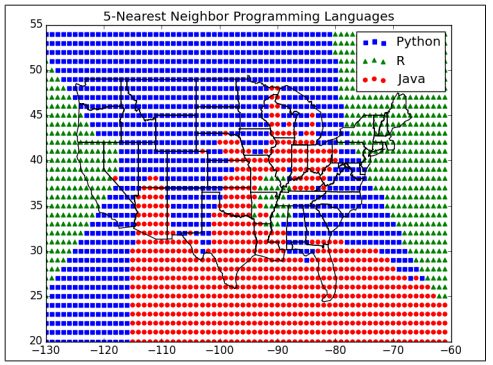
白手起家学习数据科学 ——k-Nearest Neighbors之“例子篇”(九)
例子:最喜欢的编程语言(Example: Favorite Languages) DataSciencester网站用户调查结果出来了,我们发现在许多大城市里人们所喜欢的编程语言如下: # each entry is ([longitude, latitude], favorite_language)cities = [([-122.3 , 47.53], "Python"), # Seat

白手起家学习数据科学 ——k-Nearest Neighbors之“背后的思想”(九)
设想一下,你正在预测接下来总统选举”我将要选择谁”,如果你不知道关于我的任何信息,一个合乎情理的方法是看我的邻居计划投谁,我们居住在西雅图,我的邻居一定按着计划投给Democratic候选人,这个暗示”Democratic候选人”对我也是个不错的猜想。 设想你知道更多关于我的信息,而不只是地理信息,也许你知道我的年龄、收入、我有几个孩子等等,这些特性扩大了影响我的行为,观察跟我这些特性相似的邻居
创业白手起家也需要条件——北漂18年(14)
有种很市井说法叫“平地抠饼”意思是:平地抠饼,意思也就为从一块平地上画一个圆,演员在里头表演,就像抠出一个饼来。有自食其力、自力更生、白手起家之意。创业很多时候就是要白手起家,所以才更需要创新。 选址是第一步,也是我犯第一个错误。 回到北京中关村之后,我先租了房子,六郎庄有的是,然后直奔现代电子市场租柜台。选这里是考虑三个因素,一是算是在中关村大街上(要往西走个十多米,站在中关村大街上能
弘辽科技单品链接破80W+,中年大叔白手起家日出万单!
原标题《弘辽科技单品链接破80W+,中年大叔白手起家日出万单!》 我是一个40多岁的中年大叔,标准穷人家的孩子,干过苦力当过服务员;2013年来到石狮白手起家,接触服装生意,用多年的积蓄经营分销。 然而做分销苦累不说,质量不好得不到钱,卖得太好又要资金顶得住,其中的波折与艰辛干过分销的都能懂!2018年公司因为经营不善,面临解散,仓库屯着好几十万的货卖不出去,资金周转不过来,精神一度几近崩溃,

MIT辍学白手起家!25岁的他,成为全球最年轻亿万富翁
转自:新智元 今天的这位主角是Alexandr Wang,他: 17岁,成为美国知名问答网站Quora的全职码农; 18岁,考入麻省理工学院攻读机器学习; 19岁,辍学创办Scale AI并担任CEO; 25岁,成为世界上最年轻的白手起家的亿万富翁。 19岁,MIT辍学 Alexandr Wang出生在新墨西哥州,而他的爸妈都是在新墨西哥州洛斯阿拉莫斯国家实验室的物理学家。 这处国家实验室和

从白手起家到人尽皆知,他的大佬程序员之路是怎样走向成功的?
中国作为一个拥有14亿人口的大国,幅员辽阔,可是在程序员这个行业中,却似乎总是外国人名气较大,难道中国没有很牛的程序员? 其实事实并非如此,根据数据统计,2021年我国程序员数量就已经达到了755万,那么,在这755万程序员中,有有没有特别成功的呢?他是如何成功的呢?答案是肯定的,那就是小米科技的创始人——雷军,现在就和小编一起来看看吧,一起学习别人的成功经验。 说起雷军,想必这个名字