由小到大专题

题目:输入 5 个数(含负数、小数)将它们按由小到大的顺序排列起来。提示:需要排序的数字通过参数传递进来。
题目:输入 5 个数(含负数、小数)将它们按由小到大的顺序排列起来。 提示:需要排序的数字通过参数传递进来。 例如: 输入:-1 2.1 -3 5 7 输出: -3 -1 2.1 5 7 import java.util.Scanner;public class FuShuXiaoShuPaiXu {public static void swap(double[] arr,int a,in

输入三个整数,按由小到大的顺序输出
输入三个整数,按由小到大的顺序输出 Time Limit: 1 Sec Memory Limit: 128 MB Submit: 669 Solved: 302 [ Submit][ Status][ Web Board] Description 输入三个整数,按由小到大的顺序输出。分别使用指针和引用方式实现两个排序函数。在主函数中输入和输出数据。 Inpu

输入3个字符串,要求将字母按由小到大顺序输出
对于将3个整数按由小到大顺序输出,是很容易处理的。可以按照同样的算法来处理将3个字符串按大小顺序输出。可以直接写出程序。 编写程序: 运行结果: 这个程序是很好理解的。在程序中对字符串变量用关系运算符进行比较,如同对数值型数据进行比较一样方便。
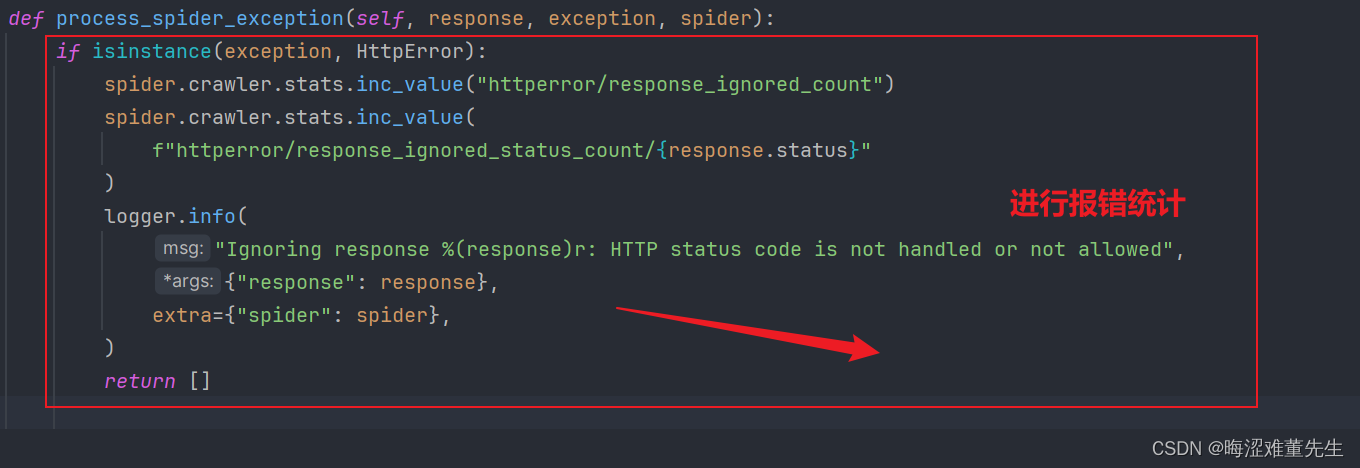
爬虫工作量由小到大的思维转变---<第七十三章 > Scrapy爬虫详解一下HTTPERROE的问题
前言: 在我们的日常工作中,有时会忽略一些工具或组件的重要性,直到它们引起一连串的问题,我们才意识到它们的价值。正如在Scrapy框架中的HttpErrorMiddleware(HTTP错误中间件)一样,在开始时,我并没有太重视它。但在实际工作中由于它引起的问题连贯性,让我深刻认识到了对其进行深入理解的必要性。对此,有必要在这个章节对HttpErrorMiddleware进行一番
cocos2dx 由小到大弹出对话框
问题: 有些UI界面会需要一个类似与对话框的东西,弹出对话框时,如何添加一个 由小到大的效果 实现: function actionEndFunc()enddialogBg:setScale(1/100)local actionScale = CCScaleTo:create(0.3, 1)local callfunc = CCCallFunc:create(actionEndF
爬虫工作量由小到大的思维转变---<第六十九章 > Scrapy.crawler模块中的异常
前言: 继续上一章: 爬虫工作量由小到大的思维转变---<第六十八章 > scrapy.utils模块中的异常-CSDN博客 Scrapy.crawler模块是Scrapy框架的核心之一,它负责管理和控制整个爬虫的生命周期。该模块提供了各种工具和功能,以便开发者可以配置和运行爬虫、处理请求和响应、解析数据以及生成输出等。它是构建Scrapy爬虫的基础,为高效地执行爬虫任务提

题目:输入三个整数x,y,z,请把这三个数由小到大输出。
题目:输入三个整数x,y,z,请把这三个数由小到大输出。 There is no nutrition in the blog content. After reading it, you will not only suffer from malnutrition, but also impotence. The blog content is all parallel goods. Th
爬虫工作量由小到大的思维转变---<第五十七章 Scrapy 降维挖掘---中间件系列(6)>
前言: 继续上一篇:https://hsnd-91.blog.csdn.net/article/details/136978761 我们继续将探讨Scrapy框架中的三个重要中间件:HTTP压缩中间件、重定向中间件和Cookie中间件。 首先,HTTP压缩中间件(HttpCompressionMiddleware)能够处理服务器返回的经过压缩的响应内容,并自动进行解压缩,从中获取原始内容。这
爬虫工作量由小到大的思维转变---<第五十章 Scrapy 深入理解Scrapy爬虫引擎(1)--核心功能>
前言: Scrapy的引擎是该框架的中心角色,负责协调整个爬虫流程的执行。引擎充当了整个框架的核心,并提供了一套强大灵活的机制来管理请求的调度、页面的下载、数据的提取和处理等关键任务。以下是关于Scrapy引擎的详细论述。 首先,Scrapy引擎负责调度和管理请求。它从待处理的请求队列中获取请求,并根据其优先级和调度策略来决定下一个要处理的请求。引擎允许用户

回溯算法题解(难度由小到大)(力扣,洛谷)
目录 注意: P1157 组合的输出(洛谷)https://www.luogu.com.cn/problem/P1157int result[10000] = { 0 }; 216. 组合总和 IIIhttps://leetcode.cn/problems/combination-sum-iii/ 17. 电话号码的字母组合https://leetcode.cn/problems/lett
爬虫工作量由小到大的思维转变---<第四十八章 Scrapy 的请求和follow问题>
前言: 有时,在爬取网页的时候,页面可能只能提取到对应的url,但是具体需要提取的信息需要到下一页(url)里面; 这时候,不要在中间件去requests请求去返回response; 用这个方法.... 正文: 在Scrapy框架内,如果你想从一个页面提取URL,然后跳转到这个URL以提取数据,最佳做法是 使用Scrapy的请求和回调系统,而不是通过外部的requests库跳转。 使用S
写一个函数,用“起泡法”对输入的10个字符按由小到大的顺序排列
#include<stdio.h> #include<conio.h> #include<string.h> int main(){ void qipao(char array[10]); printf("输入10个字符:\n"); char a[10],i; gets(a); qipao(a); for(i=0;i<10;i++) printf

用选择法对数组中10个整数按由小到大排序
#include <stdio.h> #include <conio.h> int main(){ void sort(int a[],int n); int a[10],i; printf("输入数组:\n"); for(i=0;i<10;i++) scanf("%d",&a[i]); sort(a,10); printf("排

爬虫工作量由小到大的思维转变---<第四十五章 Scrapyd 关于gerapy遇到问题>
前言: 本章主要是解决一些gerapy遇到的问题,会持续更新这篇! 正文: 问题1: 1400 - build.py - gerapy.server.core.build - 78 - build - error occurred (1, ['E:\\项目文件名\\venv\\Scripts\\python.exe', 'setup.py', 'clean', '-a', 'bdist
爬虫工作量由小到大的思维转变---<第四十三章 Scrapy Redis mysql数据连通问题(2)>
前言: 接上一章的爬虫工作量由小到大的思维转变---<第四十一章 Scrapy Redis 转mysql数据连通问题>-CSDN博客 这一章主要是讲关于多机连上sql要注意的问题! 正文: 会遇到哪些问题: 数据重复写入:当多个Scrapy-Redis实例同时运行并将数据写入同一个MySQL数据库时,可能会导致数据重复写入的问题。这是因为Scrapy-Redis使用分布式爬取的原理
爬虫工作量由小到大的思维转变---<第三十九章 Scrapy-redis 常用的那个RetryMiddleware>
前言: 为什么要讲这个RetryMiddleware呢?因为他很重要~ 至少在你装配代理ip或者一切关于重试的时候需要用到!----最关键的是:大部分的教学视频里面,没有提及这个!!!! 正文: 源代码分析 这个RetryMiddleware是来自: from scrapy.downloadermiddlewares.retry import RetryMiddleware 我们可以看
爬虫工作量由小到大的思维转变---<第四十章 Scrapy Redis 实现IP代理池管理的最佳实践>
前言: 本篇是要结合上篇一起看的姊妹篇:爬虫工作量由小到大的思维转变---<第三十九章 Scrapy-redis 常用的那个RetryMiddleware>-CSDN博客 IP代理池的管理对于确保爬虫的稳定性和数据抓取的匿名性至关重要。围绕Scrapy-Redis框架和一个具体的IP代理池中间件代码,在分布式爬虫中如何使用Redis实现IP代理池的管理,这篇文章进行探讨一下 (当然,还有更好
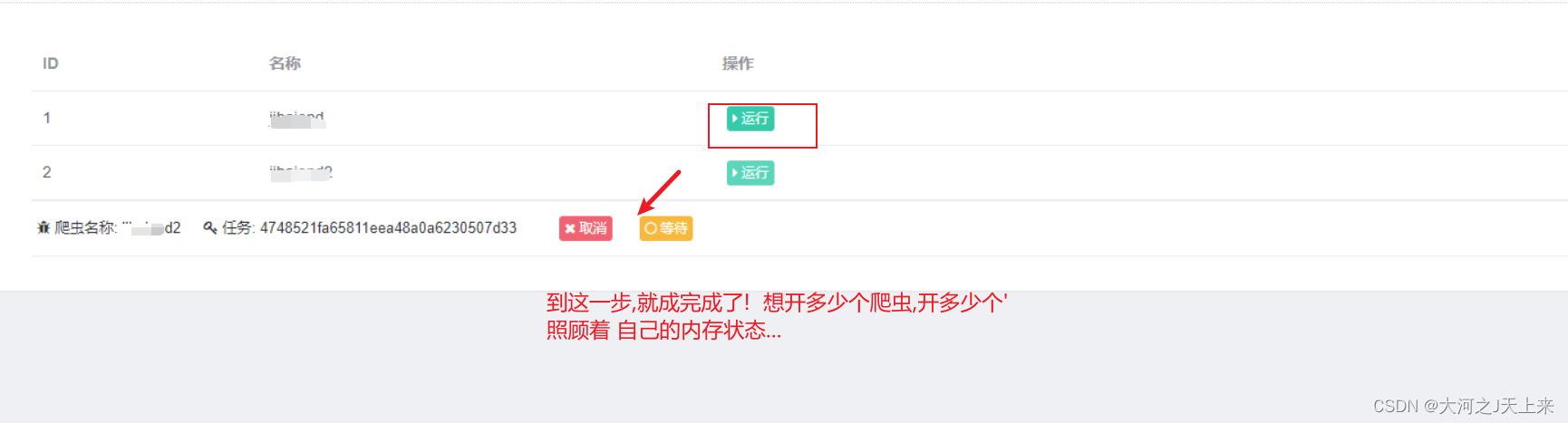
爬虫工作量由小到大的思维转变---<第三十五章 Scrapy 的scrapyd+Gerapy 部署爬虫项目>
前言: 项目框架没有问题大家布好了的话,接着我们就开始部署scrapy项目(没搭好架子的话,看我上文爬虫工作量由小到大的思维转变---<第三十四章 Scrapy 的部署scrapyd+Gerapy>-CSDN博客) 正文: 1.创建主机: 首先gerapy的架子,就相当于部署服务器上的;所以,我们先要连接主机(用户名/密码随你填不填) ----ps:我建议你填一下子,养成习惯;别到时

爬虫工作量由小到大的思维转变---<第三十四章 Scrapy 的部署scrapyd+Gerapy>
前言: scrapy-redis没被部署,感觉讲起来很无力;因为实在编不出一个能让scrapy-redis发挥用武之地的案子;所以,索性直接先把分布式爬虫的部署问题给讲清楚!! 然后,曲线救国式地再在部署的服务器上,讲scrapy redis我感觉这样才好! 正文: 现在还有不少人在用scrapy web进行爬虫管理,但我个人感觉是那玩意儿BUG挺多的;且不灵光! 而Gerapy和sc
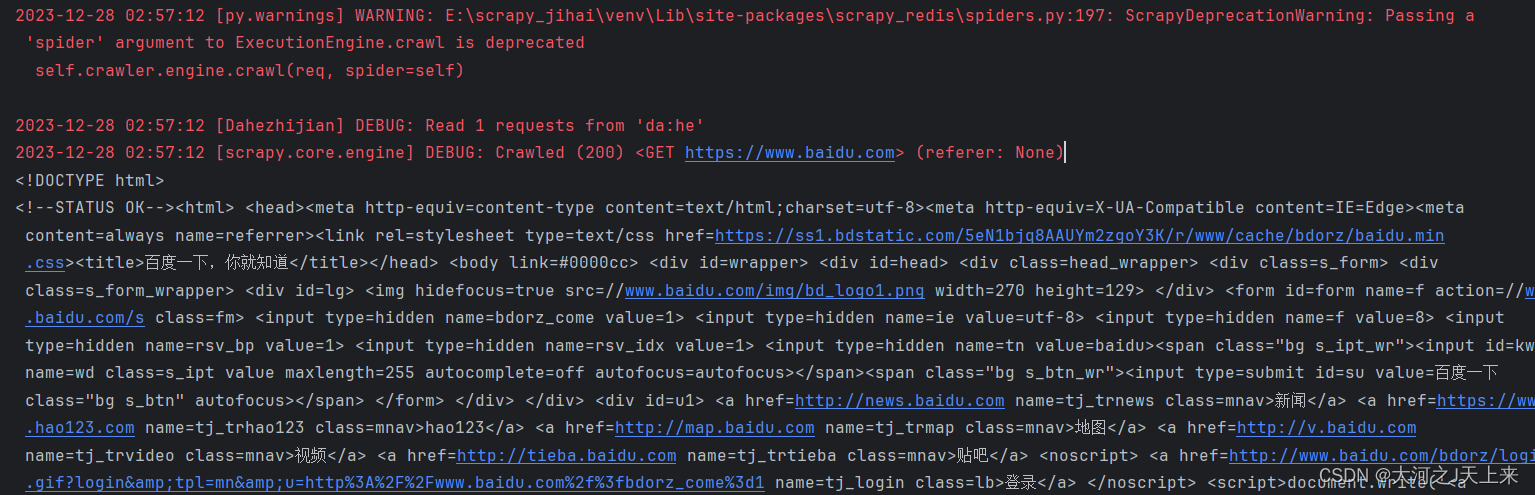
爬虫工作量由小到大的思维转变---<第三十三章 Scrapy Redis 23年8月5日后会遇到的bug)>
前言: 收到回复评论说,按照我之前文章写的: 爬虫工作量由小到大的思维转变---<第三十一章 Scrapy Redis 初启动/conn说明书)>-CSDN博客 在启动scrapy-redis后,往redis丢入url网址的时候遇到: TypeError: ExecutionEngine.crawl() got an unexpected keyword argument 'spider
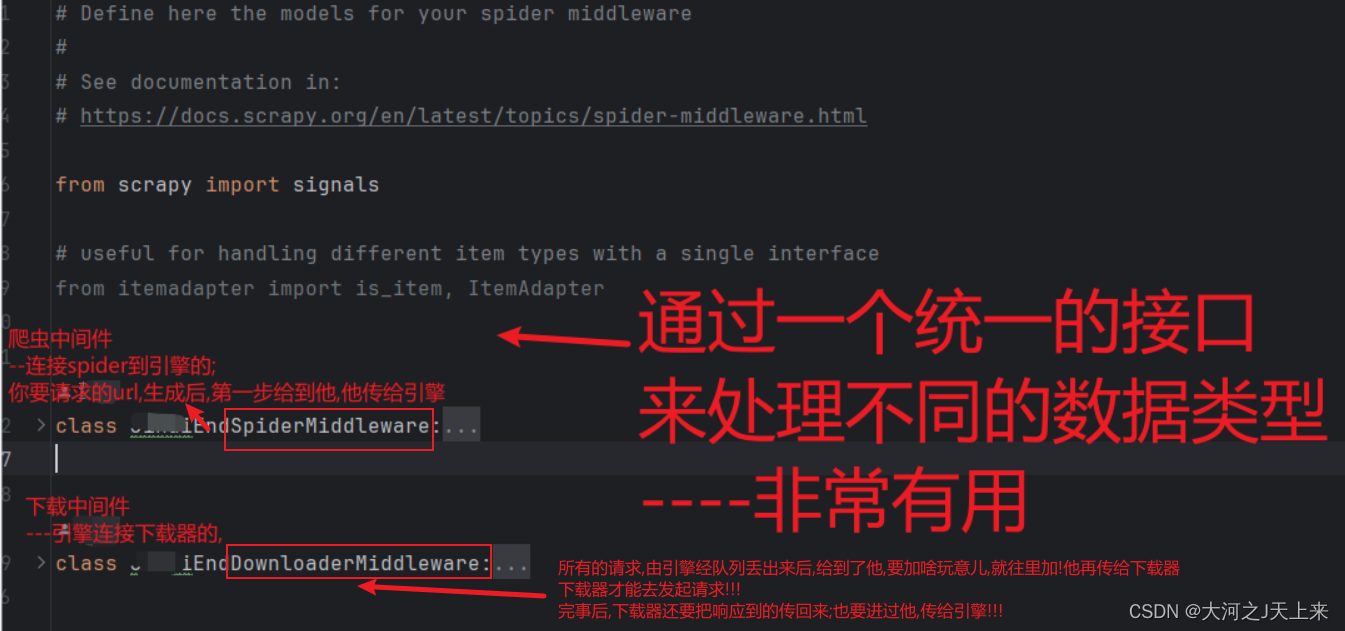
爬虫工作量由小到大的思维转变---<第二十八章 Scrapy中间件说明书>
爬虫工作量由小到大的思维转变---<第二十六章 Scrapy通一通中间件的问题>-CSDN博客 前言: (书接上面链接)自定义中间件玩不明白? 好吧,写个翻译的文档+点笔记,让中间件更通俗一点!!! 正文: 全局图: 爬虫中间件--->翻译+笔记: from scrapy import signals# useful for handling different item ty
爬虫工作量由小到大的思维转变---<Scrapy异常的存放小探讨>
前言: 异常很正常,调试异常/日志异常/错误异常~ 但在爬虫的时候,写完代码--->运行后根本挡不住一些运行异常;于是,把异常写到了中间件~ 当然,这也没有错; 不过,其实可以直接这么设计一下... 正文: 参照一下中间件处理的异常 def process_exception(self, request, exception, spider):pass 我们除了在请求异常的时候给他记
爬虫工作量由小到大的思维转变---<Scrapy异常的存放小探讨>
前言: 异常很正常,调试异常/日志异常/错误异常~ 但在爬虫的时候,写完代码--->运行后根本挡不住一些运行异常;于是,把异常写到了中间件~ 当然,这也没有错; 不过,其实可以直接这么设计一下... 正文: 参照一下中间件处理的异常 def process_exception(self, request, exception, spider):pass 我们除了在请求异常的时候给他记
爬虫工作量由小到大的思维转变---<第二十六章 Scrapy通一通中间件的问题>
前言: 准备迈入scrapy-redis或者是scrapyd的领域进行一番吹牛~ 忽然想到,遗漏了中间件这个环节! 讲吧~太广泛了;不讲吧,又觉得有遗漏...所以,本章浅谈中间件; (有问题,欢迎私信! 我写文告诉你解法) 正文: 当我们谈到 Scrapy 的中间件时,可以将其比作一个特殊的助手,负责在爬虫的不同阶段进行处理和干预。Scrapy 有两种类型的中间件:爬虫中间件和下载
爬虫工作量由小到大的思维转变---<第二十五章 Scrapy开始很快,越来越慢(追溯篇)>
爬虫工作量由小到大的思维转变---<第二十二章 Scrapy开始很快,越来越慢(诊断篇)>-CSDN博客 爬虫工作量由小到大的思维转变---<第二十三章 Scrapy开始很快,越来越慢(医病篇)>-CSDN博客 前言: 之前提到过,很多scrapy写出来之后,不知不觉就会造成整体scrapy速度越来越慢的情况,且大部分都是内存泄漏问题(前面讲了如何诊断,各人往上看链接); `通药`也就是
爬虫工作量由小到大的思维转变---<第二十四章 Scrapy的`统计数据`收集stats collection>
前言: 前两篇是讲的数据诊断分析,还有一篇深挖`解决内存泄漏`的文章,目前我还没整理汇编出来;但是,想到分析问题的时候,忽然觉得`爬虫的数据统计`好像也挺重要;于是,心血来潮准备来插一篇这个------让大家对日常scrapy爬的数据,做到心里有数!不必自己去搅破脑汁捣腾日志,敲计算器了; 正文: 在 Scrapy 中,可以使用 Stats Collection(统计信息收集)来收集和获取有