本文主要是介绍爬虫工作量由小到大的思维转变---<第三十五章 Scrapy 的scrapyd+Gerapy 部署爬虫项目>,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
项目框架没有问题大家布好了的话,接着我们就开始部署scrapy项目(没搭好架子的话,看我上文爬虫工作量由小到大的思维转变---<第三十四章 Scrapy 的部署scrapyd+Gerapy>-CSDN博客)
正文:
1.创建主机:
首先gerapy的架子,就相当于部署服务器上的;所以,我们先要连接主机(用户名/密码随你填不填)
----ps:我建议你填一下子,养成习惯;别到时候布到云服务上去了,被人给扫了,那不好玩的!
这里ip就填 127.0.0.1 ,端口6800 --->就是你scrapyd的端口!

创建完成,应该会是这样的:
此时他说你的主机没连接上,为啥?
-----因为这是个基于scrapyd的可视化网页架子,你不开scrapyd服务,他基于啥给你可视化?
所以...
2.开启scrapyd服务
(本地127.0.0.1的不用调设置哈,直接开! 布云端服务器以后会另外说的)
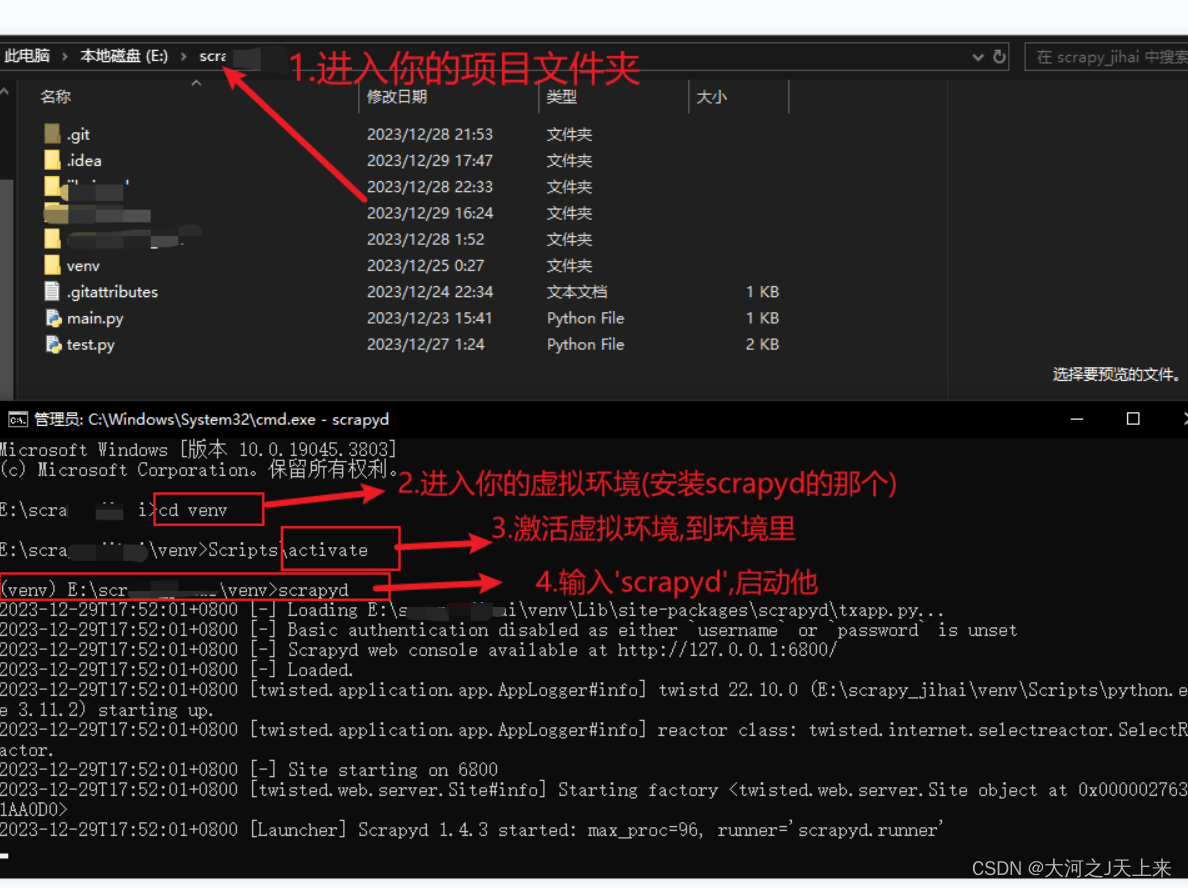
ps:(我这里是拿个项目过来改的,以上一篇爬虫工作量由小到大的思维转变---<第三十四章 Scrapy 的部署scrapyd+Gerapy>-CSDN博客)里面的文件为准; 你哪里装的gerapy和scrapyd,就去那个文件夹;
成功之后,如图:

---你的状态指标,刷新一下:正常! 就是成功了~
3.创建项目文件夹(你也可以自己cmd完成,都随意! 看我原理就成):
特别注意:
-
log是日志文件夹,你每开启一次gerapy,他就会在里面生成一个日志文件;报错的话,你就去找对应的ERROR看去~
-
gerapy文件夹里也有一个projects文件夹; 他是你装gerapy文件就生成了的; 我目前的版本是gerapy= 0.9.13 ; 这个版本,是在log同级文件里,创建projects(手动创建 mkdir projects)
-
如果你的projects创建的层级错了,他会报:

----认真看我说的1 2 3条,还有图! 标红的是极为关键的地方(也就是你丢爬虫工程的地方),搞错了你就丢不上去爬虫工程了~
4.丢爬虫工程:
1.怎么丢爬虫工程:
-丢你scrapy的根文件,也就是那个含着"scrapy.cfg"文件的包,全部拷贝!

2.从github上/其他地方拷(后面会讲,这里只谈本地的先带着走一遍)
5.部署到XX服务器(这里是部署本机链接服务):
步骤1. 你爬虫项目丢的没问题,这个图就没问题!
步骤2: 打包如果有问题,去看log! 很有可能是坏在setting上---按我步骤,一般不会报错;你就反复去看 '4.丢爬虫工程'那个环节!
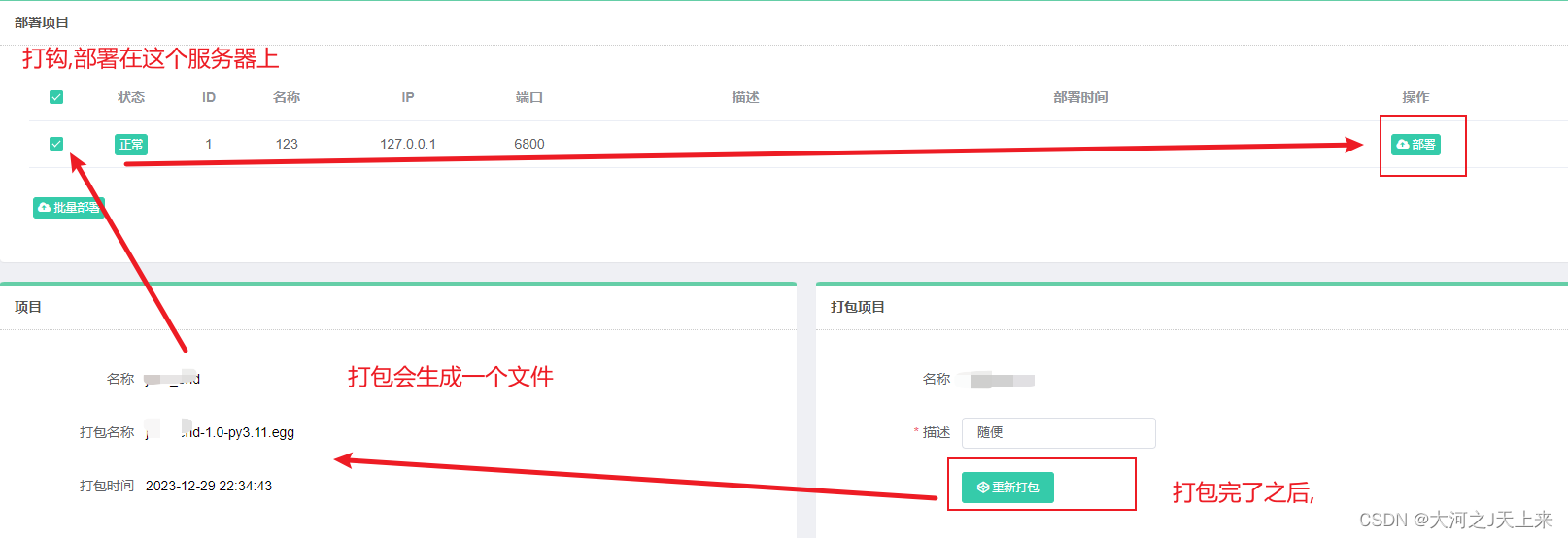
6.部署成功!


7.随便玩了
敞开了玩~~ 鼠标点点点,各种乱造...every body 造坏了再来一遍!!吼吼!!!
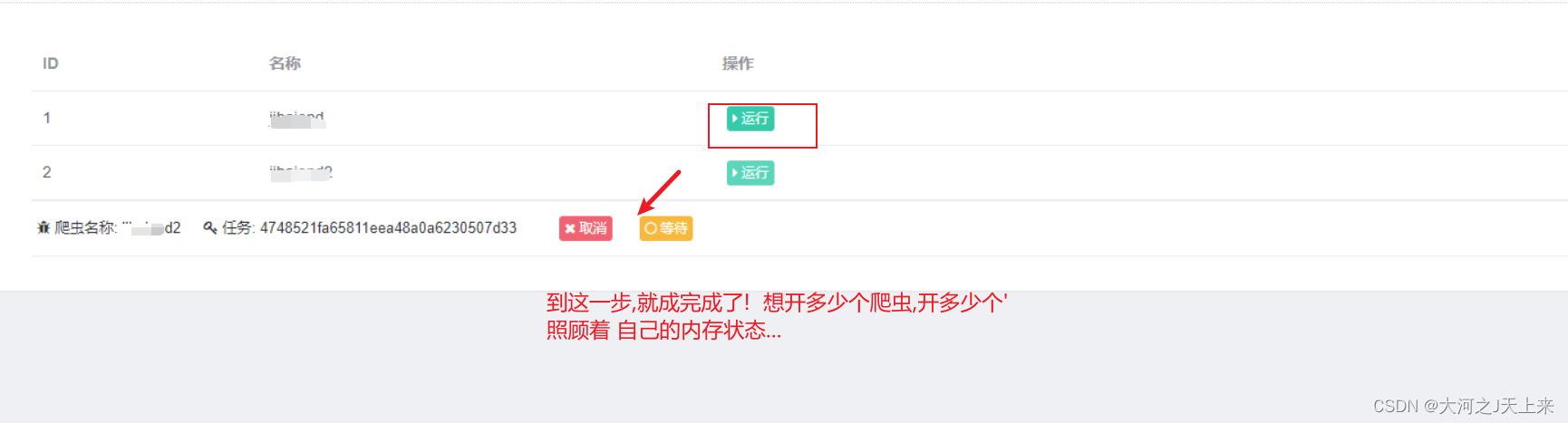
-----------恭喜大家,部署了自己第一个爬虫项目! 是不是瞬间感觉其他都不香了....
所以我就说嘛.爬虫没意思. 趁早散伙....
这篇关于爬虫工作量由小到大的思维转变---<第三十五章 Scrapy 的scrapyd+Gerapy 部署爬虫项目>的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








