本文主要是介绍爬虫工作量由小到大的思维转变---<第七十三章 > Scrapy爬虫详解一下HTTPERROE的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
在我们的日常工作中,有时会忽略一些工具或组件的重要性,直到它们引起一连串的问题,我们才意识到它们的价值。正如在Scrapy框架中的HttpErrorMiddleware(HTTP错误中间件)一样,在开始时,我并没有太重视它。但在实际工作中由于它引起的问题连贯性,让我深刻认识到了对其进行深入理解的必要性。对此,有必要在这个章节对HttpErrorMiddleware进行一番详尽的分析。
问题也不会太多,主要讲的就是几个点;关于httperror在前文有过一个简单版本的论述
爬虫工作量由小到大的思维转变---<第五十三章 Scrapy 降维挖掘---中间件系列(2)> (HttpErrorMiddleware、OffsiteMiddleware和RefererMiddl)-CSDN博客
可以先看这篇文章~
正文:
首先,通过源码剖析,我们可以了解到HttpErrorMiddleware的基本作用:它负责处理Spider的HTTP错误,根据配置来决定是否忽略非200响应。简单来说,当响应状态码在200到300之间,Scrapy会认为这是一个成功的响应,并继续其它处理。然而,如果响应状态码不在这个范围内,中间件将决定基于你的设置是否将其忽略:也就是说,如果你通过设置handle_httpstatus_all或
handle_httpstatus_list来明确指出希望接收非200响应,Scrapy会相应地处理这些响应而不是简单地抛出异常。
1.源码刨析:
a.对应路径:
b.对应源码:
"""
HttpError Spider Middleware该中间件处理Spider的HTTP错误。它根据配置决定是否忽略非200响应。See documentation in docs/topics/spider-middleware.rst
"""import loggingfrom scrapy.exceptions import IgnoreRequestlogger = logging.getLogger(__name__)# HttpError类继承自IgnoreRequest,用于表示被过滤的非200响应。
class HttpError(IgnoreRequest):"""表示一个非200响应被过滤的异常类。Attributes:response: 发生错误的响应对象。"""def __init__(self, response, *args, **kwargs):self.response = responsesuper().__init__(*args, **kwargs)# 处理HTTP错误的中间件类。
class HttpErrorMiddleware:"""处理Spider输入时的HTTP错误。Attributes:handle_httpstatus_all: 布尔值,配置项,表示是否允许所有非200响应。handle_httpstatus_list: 列表,配置项,包含允许的非200响应状态码。"""@classmethoddef from_crawler(cls, crawler):"""从爬虫实例创建中间件对象。Args:crawler: Crawler实例。Returns:HttpErrorMiddleware实例。"""return cls(crawler.settings)def __init__(self, settings):"""初始化中间件。Args:settings: Scrapy设置对象。"""self.handle_httpstatus_all = settings.getbool("HTTPERROR_ALLOW_ALL")self.handle_httpstatus_list = settings.getlist("HTTPERROR_ALLOWED_CODES")def process_spider_input(self, response, spider):"""处理Spider输入的响应。Args:response: 响应对象。spider: 当前处理的Spider。Returns:如果响应应该被忽略,则返回None;否则将响应传递给下一个中间件。"""# 如果响应状态码是200到300之间,则认为是成功响应,直接返回。if 200 <= response.status < 300:returnmeta = response.meta# 如果设置为允许所有非200响应,则直接返回。if meta.get("handle_httpstatus_all", False):return# 如果响应元数据中有指定允许的状态码列表,则只处理列表中的状态码。if "handle_httpstatus_list" in meta:allowed_statuses = meta["handle_httpstatus_list"]elif self.handle_httpstatus_all:returnelse:# 默认情况下,使用Spider或中间件的允许状态码列表。allowed_statuses = getattr(spider, "handle_httpstatus_list", self.handle_httpstatus_list)# 如果响应状态码在允许的列表中,则认为是有效响应,返回None。if response.status in allowed_statuses:return# 如果响应状态码未在允许的范围内,则抛出HttpError异常。raise HttpError(response, "Ignoring non-200 response")def process_spider_exception(self, response, exception, spider):"""处理Spider异常。Args:response: 响应对象。exception: 异常对象。spider: 当前处理的Spider。Returns:如果异常为HttpError,则记录日志并忽略该响应;否则将异常传递给下一个中间件。"""# 如果异常为HttpError,则认为是需要忽略的响应。if isinstance(exception, HttpError):spider.crawler.stats.inc_value("httperror/response_ignored_count")spider.crawler.stats.inc_value(f"httperror/response_ignored_status_count/{response.status}")logger.info("Ignoring response %(response)r: HTTP status code is not handled or not allowed",{"response": response},extra={"spider": spider},)return []
2.对代码进行总结:
a.运行机制
- 当status在【200,300】内的时候,直接返回(无异常);
- 当status开始出现问题的时候,看你是否设置允许状态码;
--- 在spider里面,发送请求的时候会在mata里面带着handle_httpstatus_list或者handle_httpstatus_all ;-->如果是all,表示所有的状态码都不会引发httpError的问题;而handle_httpstatus_list则是需要在集合里面设置对应允许的一些状态码;
--- 也可以直接在setting里面直接进行handle_httpstatus_list 的设置;(如图)
b.报错机制
在允许范围内的status通通不会报错,就没有
process_spider_exception
什么事了; 只有不在范围内的错误,会进行一个统计;
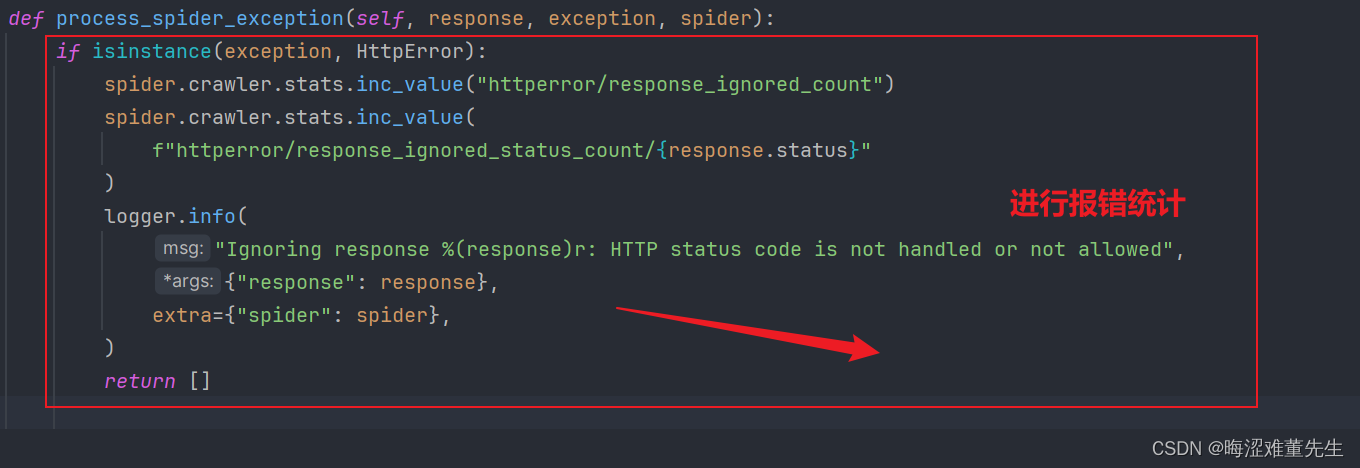
这种设计非常灵活,允许开发者根据实际需求决定哪些HTTP状态码是可接受的,而哪些应当被视为错误。比如,在某些应用场景下,接收到404响应可能是正常的一部分,不应该中断整个爬取流程。因此,通过合理配置HttpErrorMiddleware,就可以实现这样的需求。
3.总结:
HttpErrorMiddleware是Scrapy框架中一个非常重要的组件,尤其是在处理复杂网页爬取时。它不仅能帮助我们更灵活地处理HTTP错误,还能通过设置,让我们的爬虫更加健壮。了解它的工作原理和如何配置,对于开发高效的爬虫程序来说是非常关键的。通过对源码的解析和应用实践,我们能更好地利用这个中间件,优化我们的网络爬虫,不仅提升数据采集效率,还能保证数据的质量和完整性。
总的来说,HttpErrorMiddleware加深了我们对Scrapy框架灵活性和强大功能的认识,是值得每个使用Scrapy框架的开发者深入了解和掌握的知识点。
这篇关于爬虫工作量由小到大的思维转变---<第七十三章 > Scrapy爬虫详解一下HTTPERROE的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





