放弃专题

1秒的价值:来自谷歌的统计数据:网页加载超过4秒,25%的人会放弃;手机网页超过10秒,50%用户会放弃,60%的人不会再返回该网站
【1秒的价值】来自谷歌的统计数据:网页加载超过4秒,25%的人会放弃;手机网页超过10秒,50%用户会放弃,60%的人不会再返回该网站。亚马逊每天销售额约6700万美元,网页延迟1秒可导致全年最高损失16亿美元。此外,“谷歌一代”的线下生活也是快节奏的:盗版、快餐、速配、少耐心。 本文来自义乌用友网:www.ywerpsoft.com

Jenkins 从小白入门到企业实践打怪放弃之路系列笔记 【持续集成与交付快速入门必备】
我在B站学运维之Jenkins持续集成和交付快速入门介绍与安装(1): https://www.bilibili.com/read/cv13512558 我在B站学运维之Jenkins持续集成和交付入门基础使用与集成部署实践(2): https://www.bilibili.com/read/cv13512906 我在B站学运维之Jenkins持续集成和交付之邮箱&钉钉&企业微信消息

力扣第71题:简化路径 放弃栈模拟,选择数据流√(C++)
目录 题目 思路 解题过程 复杂度 Code 题目 给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。 在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'/

Gmapping从开始到放弃—写一个TF 监听
这篇文章主要 记录如何监听一个TF广播,通过监听tf,我们可以避免繁琐的旋转矩阵的计算,而直接获取我们需要的相关信息.当然也是接着上一篇文章创建的开发包继续走下去 (1)在my_tf文件下的src下新建一个文件命名turtle_tf_listener.cpp. 添加代码如下 #include <ros/ros.h>#include <tf/transform_listener.h> //

Gmapping从开始到放弃—写一个TF 广播
这是一个关于实现把机器人的位姿广播到TF中,这是对ROS 有一定的熟悉之后教程 (1)cd catkin_ws/src 进入我们的ROS 的工作空间 (2)catkin_create_pkg my_tf tf roscpp rospy turtlesim 这一句是新建一个ROS 的包,也就是一个ROS的工程,并添加他的依赖项,主要依赖tf和C++以及你可以使用python开发 (3) c

从入门到放弃:CPU流水线技术全解析
一、CPU 流水线技术初识 在当今数字化的时代,计算机已经成为我们生活中不可或缺的一部分。而在计算机的核心部位,中央处理器(CPU)则是其重要的组成部分。CPU 的性能决定了计算机的运行速度和处理能力,而流水线技术则是 CPU 性能提升的关键所在。 1.1 指令执行生命周期回顾 一条指令的生命周期分为五个阶段: 取指阶段(Instruction Fetch):取指阶段是指将指令从存储器中读

spark从入门到放弃五十四:Spark Streaming(14)checkpoint
1.概述 每一个spark streaming 应用正常来说都要7*24小时运转的,这就是实时计算程序的特点。因为要持续不断的对数据进行计算。因此,对实时计算的要求,应该是必须能够与应用程序逻辑无关的失败,进行容错。 如果要实现这个目标,spark streaming 程序就必须将足够的信息checkpoint 到容错的存储系统上,从而让他能够从失败中进行恢复。有两种数据需要进行checkpo

spark从入门到放弃五十三:Spark Streaming(13)缓存于持久化
与RDD 类似,spark Streaming 也可以让开发人员手动控制,将数据流中的数据持久化到内存中。对DStream 调用persist ( ) 方法,就可以让spark Streaming 自动将该数据流中的所有产生的RDD 都持久化到内存中。如果要对于一个DStream 多次执行操作,那么对DStream 持久化是非常有用的。因为多次操作,可以共享一份数据。 对于基于窗口的操作,例如re
spark从入门到放弃五十二:Spark Streaming(12)结合spark Sql
文章地址:http://www.haha174.top/article/details/253627 1.简介 Spark Streaming 强大的地方在于,可以于spark core 和spark sql 整合使用,之前已经通过transform foreachRDD 等算子看到了 如何将DStream 种的RDD 使用spark core 执行批处理操作。现在就来看看 如何将spark s
spark从入门到放弃五十五:设置executor 数量 和task 并行数
一.指定spark executor 数量的公式 在spark standalone 模式下无法直接指定每个worker 创建多少个executor 但是我们可以使用这样的方式。 executor 数量 = spark.cores.max/spark.executor.cores spark.cores.max 是指你的spark程序需要的总核数 spark.executor.cores 是指每

Dagger2 这次入门就不用放弃了
Dagger2 这次入门就不用放弃了 前言 之前也研究过很多次Dagger2这东西了,可能以后RxJava+Retrofit+MVP+Dagger2是Android发展的主流框架,看了Dagger2的实现代码,有点不明所以。上网也有很多文章介绍依赖注入、Dagger2的组件等等那些,这样这样这样什么组件呀、模块呀、注入呀。但是感觉对于入门来说那些文章都没有说到点子上,具体怎么用这个核心点而且应

Kafka为什么要放弃Zookeeper
最近,confluent社区发表了一篇文章,主要讲述了Kafka未来的2.8版本将要放弃Zookeeper,这对于Kafka用户来说,是一个重要的改进。之前部署Kafka就必须得部署Zookeeper,而之后就只要单独部署Kafka就行了。[1] 1.Kafka简介 Apache Kafka最早是由Linkedin公司开发,后来捐献给了Apack基金会。 Kafka被官方定义为分布式流式处理

【AI】准备放弃“文心一言”,不再续费
百度真是把一手好牌打的稀烂,最近感觉文心一言起步很猛,但是能力越来越差。 不要说毫无技术极客精神,几乎没有斗志和追求了。 有2个案例,让我非常的失望。 第一个案例体现了它的不诚实,过度的商业“考量”。第二个案例体现了它的不专业。 第一个提示词对比:开源大模型 我的提示词是: 国产开源大模型有哪些,给我3-5个例子。 文心一言是这样回答我的: 国产开源大模型在近年来取得了显著的发展,

git 放弃本地修改 强制更新
git fetch --all git reset --hard origin/分支名称 git fetch 只是下载远程的库的内容,不做任何的合并 git reset 把HEAD指向刚刚下载的最新的版本
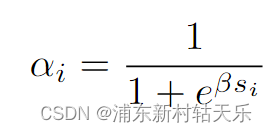
NeRF从入门到放弃5: Neurad代码实现细节
Talk is cheap, show me the code。 CNN Decoder 如patch设置为32x32,patch_scale设置为3,则先在原图上采样96x96大小的像素块,然后每隔三个取一个像素,降采样成32x32的块。 用这32x32个像素render feature,再经过CNN反卷积预测出96x96的像素,与真值对比。 def _patches_from_c

NeRF从入门到放弃3: EmerNeRF
https://github.com/NVlabs/EmerNeRF 该方法是Nvidia提出的,其亮点是不需要额外的2D、3Dbox先验,可以自动解耦动静field。 核心思想: 1. 动、静filed都用hash grid编码,动态filed比静态多了时间t,静态的hash编码输入是(x,y,z),动态是(x,y,z,t)。 2. 使用flow融合多帧的特征,预测当前时刻的点的前向和后向的fl

NeRF从入门到放弃2:InstantNGP
原始的NeRF每条光线上的点都要经过MLP的查询,才能得到其密度和颜色值,要查询的点非常多,而MLP的推理是比较耗时的。 InstantNGP将空间划分成多个层级的体素(voxels),并且在每个体素内部使用神经网络来预测feature。 而Plenoxels则干脆就不使用神经网络了,它直接在体素中存储场景的辐射亮度和密度信息。通过使用球谐函数(Spherical Harmonics)来近似每

飞控学习从入坑到放弃心路历程 ——————致敬无名小哥
大一开始接触单片机,一个老乡带我进入的学校实验室,然后开始学习c语言,51单片机,做了一个蓝牙小车,大一暑假电赛老师做的高频题目,一脸懵逼,后面师兄建议我学习下32,我记得当时老师来了一句你明天是不是就要学64了,感觉当时很无语,(老师貌似喜欢做硬件的)还是一边玩一边学了下32,后面电赛测试的时候就没去了,因为什么都没做出来,也是当时才知道原来有无人机的控制题目可以选,但是老师并不同意我们
MySQL从放弃到疯狂
SQL基础 InnoDB存储引擎 存储引擎常用的命令 show engines; # 查看所支持的所有存储引擎show variables like '%storage_engine%'; # 查看默认的存储引擎SET DEFAULT_STORAGE_ENGINE=MyISAM; # 设置默认存储引擎#创建表时指定存储引擎create table tableNmae{...}engi
javaweb从入门到不放弃
知识点: git: 常用命令冲突解决版本回退 java&guava: 常见容器java8流 maven: - 父子pom- profile- scope- 生命周期- 依赖冲突- 插件- 占位符; linux: 常见命令(文件grep,wc,查找,权限、压缩、scp)crontab进程awkcrul系统性能方面: free、zostat、vmstat
事出反常必有妖,难道真的要放弃FastJSON?
目录 小编使用FastJSON的情况 FastJSON是什么? FastJSON使用体验 FastJSON真的很快吗? FastJSON活跃度如何? FastJSON要不要用? 小编使用FastJSON的情况 1、4年前的一个项目中,有一位老架构前辈发现我们项目中用FastJSON,跟我们说,FastJSON的源码比较恶心,而且有很多漏洞,用的时候注意点,当时也不太懂,没怎么在

Python 项目应该放弃requirements.txt?揭秘PDM的强大功能
目录 requirements.txt的局限性 PDM 的优势 如何使用 PDM 安装 PDM 初始化项目 添加依赖 管理依赖 示例代码 初始化项目并添加依赖 编写简单的 Flask 应用 运行应用 PDM高级功能 多环境管理 脚本管理 发布包 在 Python 项目中管理依赖项,最常见的方式是使用 requirem)ents.txt 文件。但最近有一种新的

放弃Venn-Upset-花瓣图,拥抱二分网络
写在前面 让点随机排布在一个区域,保证点之间不重叠,并且将点的图层放到最上层,保证节点最清晰,然后边可以进行透明化,更加突出节点的位置。这里我新构建了布局函数 PolyRdmNotdCirG 来做这个随机排布。调用的是packcircles包的算法。使用和其他相似函数一样,这里我们重点介绍一下使用这种算法构造的二分网络布局。 微生物网络 ggClusterNet 安装 ggClusterNe
iptables 从放弃 到 熟悉
之前碰到 iptables 就感觉像天书一样,其实找到靠谱的资料,然后自己理解,也并不是那么难。 靠谱资料 强烈推荐–>http://www.zsythink.net/archives/tag/iptables/page/2/ 如果认真读完,可以有个很全面的理解视频:http://www.imooc.com/video/7602

Java从入门到放弃
线程池的主要作用 线程池的设计主要是为了管理线程,为了让用户不需要再关系线程的创建和销毁,只需要使用线程池中的线程即可。 同时线程池的出现也为性能的提升做出了很多贡献: 降低了资源的消耗:不会频繁的创建、销毁线程,线程池中的线程随取随用。提高了相应速度:因为线程是已经创建好的线程,所以减少了线程创建的时间。提高了线程的可管理性:线程是稀缺资源不能无限制的创建,使用线程池使得线程的数量是可控的。
spark从入门到放弃 之 分布式运行jar包
scala代码如下: import org.apache.spark.SparkConfimport org.apache.spark.SparkContextimport org.apache.spark.SparkContext._/*** 统计字符出现次数*/object WordCount {def main(args: Array[String]) {if (args.len