抽取专题

基于Linux的ffmpeg python的关键帧抽取
《基于Linux的ffmpegpython的关键帧抽取》本文主要介绍了基于Linux的ffmpegpython的关键帧抽取,实现以按帧或时间间隔抽取关键帧,文中通过示例代码介绍的非常详细,对大家的学... 目录1.FFmpeg的环境配置1) 创建一个虚拟环境envjavascript2) ffmpeg-py

MySQL中的`SUBSTRING()`和`MID()`函数:精准抽取字符串中的子串
在数据库操作中,经常需要从存储的字符串中提取出特定的部分,比如从用户全名中提取姓氏、从日期字符串中提取年份等。MySQL提供了SUBSTRING()和MID()两个函数,它们的功能几乎完全相同,都是用来从字符串中抽取子串的。本文将详细介绍这两个函数的用法、参数以及在实际场景中的应用。 一、SUBSTRING()和MID()函数的基本语法 1. SUBSTRING()函数 SUBSTRING(

实体关系抽取——ACE2005数据介绍
ACE2005数据介绍 overallEnglish partrelation chinese partarabic part overall ACE2005数据集包括英语,阿拉伯语和中文三部分数据,可以用来做实体,关系,事件抽取等。 English part English部分包括了broadcast news(广播新闻)(bn), broadcast conversa

实体关系抽取——CRF++
CRF++是CRF算法的一个实现。 它最重要的功能我认为是采用了特征模板。这样就可以自动生成一系列的特征函数,而不用我们自己生成特征函数,我们要做的就是寻找特征,比如词性等。 crf 首先需要一些预备知识,如对crf中转移特征和位置特征的理解。 首先需要知道我们的观测序列x即输入的句子是完全已知的,可以得到任意位置的观测值,特征也是从观测序列中得出。所以在李航的统计学习方法中,特征函数的形式是

NLP-信息抽取:关系抽取【即:三元组抽取,主要用于抽取实体间的关系】【基于命名实体识别、分词、词性标注、依存句法分析、语义角色标注】【自定义模板/规则、监督学习(分类器)、半监督学习、无监督学习】
信息抽取主要包括三个子任务: 实体抽取与链指:也就是命名实体识别关系抽取:通常我们说的三元组(triple)抽取,主要用于抽取实体间的关系事件抽取:相当于一种多元关系的抽取 一、关系抽取概述 关系抽取通常在实体抽取与实体链指之后。在识别出句子中的关键实体后,还需要抽取两个实体或多个实体之间的语义关系。语义关系通常用于连接两个实体,并与实体一起表达文本的主要含义。常见的关系抽取结果

NLP-信息抽取-NER-2015-BiLSTM+CRF(一):命名实体识别【预测每个词的标签】【评价指标:精确率=识别出正确的实体数/识别出的实体数、召回率=识别出正确的实体数/样本真实实体数】
一、命名实体识别介绍 命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型。是信息提取, 问答系统, 句法分析, 机器翻译等应用领域的重要基础工具, 在自然语言处理技术走向实用化的过程中占有重要地位. 包含行业, 领域专有名词, 如人名, 地名, 公司名, 机构名, 日期, 时间, 疾病名, 症状名, 手术名称, 软


OA系统Dao层抽取方法总结
在做OA系统的过程中,涉及到Dao层的抽取,下边对其作如下总结: 1、 第一步:最初设计为:为每一个实体都设计出一个Dao层的接口,同时有一个实现类实现该接口。结构如下: 这种设计的问题在于,因为每一个实体类Dao层接口中的方法都有很大一部分是相同的,这就造成了不必要的重复,每增加一个实体类都需要做很大的工作量。 2、 第二步:为了解决实体类Dao层接口中代码重复的问题,向
[论文笔记] DCLM 分长度区间进行长文本抽取
import osimport zstandard as zstdimport jsonimport ioimport multiprocessingfrom tqdm import tqdm# 定义根目录路径root_dir = "dclm-baseline-1.0"output_base_dir = "dclm" # 输出的基准路径# 定义长度区间 (字符数)length_r

【知识图谱】2.知识抽取与知识存储
目录 一、知识抽取 1、实体命名识别(Name Entity Recognition) 2、关系抽取(Relation Extraction) 3、实体统一(Entity Resolution) 4、指代消解(Coreference Resolution) 二、知识图谱的存储 一、知识抽取 知识图谱的构建是后续应用的基础,而且构建的前提是需要把数据从不同

机器学习(第六关--文本特征抽取)
以下内容,皆为原创,制作实属不易,感谢大家的观看和关注。 在此真诚的祝愿大家,生活顺顺利利,身体健健康康,前途似锦。 第一关:机器学习概念和流程http://t.csdnimg.cn/IuHh4第二关:数据集的使用http://t.csdnimg.cn/1AD9D第三关:特征工程-字典特征提取http://t.csdnimg.cn/tSES1第四关:特征工程-文本特征提取http://t.

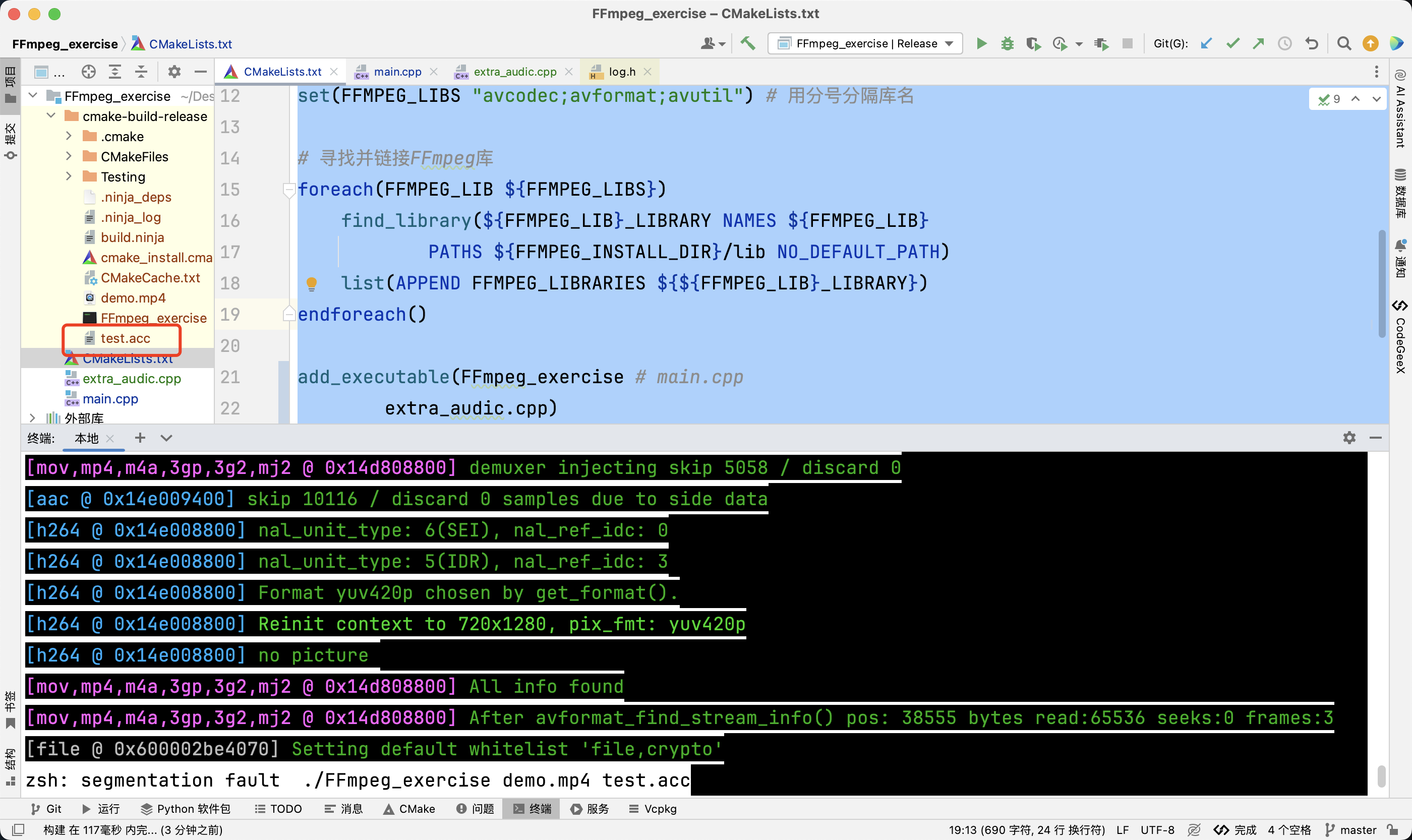
ffmpeg音视频开发从入门到精通——ffmpeg实现音频抽取
文章目录 FFmpeg 实现音频流抽取1. 包含FFmpeg头文件与命名空间声明2. 主函数与参数处理3. 打开输入文件4. 获取文件信息5. 查找音频流6. 分配输出文件上下文7. 猜测输出文件格式8. 创建新的音频流9. 打开输出文件10. 写入文件头信息11. 读取并写入音频数据12. 写入文件尾部信息并释放资源 运行程序注意事项抽取音频完整代码 FFmpeg 实现音频流抽

NLP领域内,文本分类、Ner、QA、生成、关系抽取等等,用过的最实用、效果最好的技巧或思想是什么?
作者:杨夕 链接:https://www.zhihu.com/question/451107745/answer/1801709801 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 命名实体识别用过的最实用、效果最好的技巧或思想可以看一下 这个 【关于 NER trick】 那些你不知道的事github.com/km1994/NLP-Interview

文本挖掘之降维技术之特征抽取之非负矩阵分解(NMF)
通常的矩阵分解会把一个大的矩阵分解为多个小的矩阵,但是这些矩阵的元素有正有负。而在现实世界中,比如图像,文本等形成的矩阵中负数的存在是没有意义的,所以如果能把一个矩阵分解成全是非负元素是很有意义的。在NMF中要求原始的矩阵的所有元素的均是非负的,那么矩阵可以分解为两个更小的非负矩阵的乘积,这个矩阵 有且仅有一个这样的分解,即满足存在性和唯一性。 Contents

文本分类之降维技术之特征抽取之SVD矩阵的分解的原理的介绍
http://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html 一、奇异值与特征值基础知识: 特征值分解和奇异值分解在机器学习领域都是属于满地可见的方法。两者有着很紧密的关系,我在接下来会谈到,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。先谈谈特征值分解吧:

文本挖掘之降维之特征抽取之主成分分析(PCA)
PCA(主成分分析) 作用: 1、减少变量的的个数 2、降低变量之间的相关性,从而降低多重共线性。 3、新合成的变量更好的解释多个变量组合之后的意义 PCA的原理: 样本X和样本Y的协方差(Covariance): 协方差为正时说明X和Y是正相关关系,协方差为负时X和Y是负相关关系,协方差为0时X和Y相互独立。 Cov(X,X)就是X的方差(Variance).
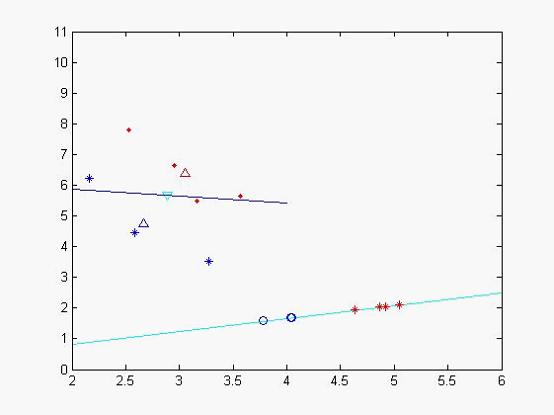
文本分类之降维技术之特征抽取之LDA线性判别分析
背景:为什么需要特征抽取? 基于的向量空间模型有个缺点,即向量空间中的每个关键词唯一地代表一个概念或语义单词,也就是说它不能处理同义词和多义词,然而实际情况是:一个词往往有多个不同的含义,多个不同的词可以代表一个概念。在这种情况下,基于的向量空间模型不能很好的解决这种问题。 特征抽取方法则可以看作从测量空间到特征空间的一种映射或变换,一般是通过构造一个特征评分函数,把测量空间的
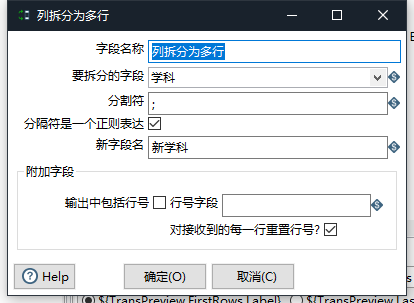
银行数仓项目实战(二)--数据采集(Kettle的抽取(E)转换(T)加载(L))
Kettle安装 Kettle又名PDI 要求电脑中有Java环境。 下载Kettle9.0的安装包,如有需要可以联系up私发噢。 注意!!! 解压路径不能有中文,空格 解压后双击spoon.bat即可使用 链接数据库需要相应的驱动,Oracle的驱动是OJDBC,导入到相应的文件夹中 之后需要重启Kettle ETL:Extract(抽取)-translate(转换)-load(加载)
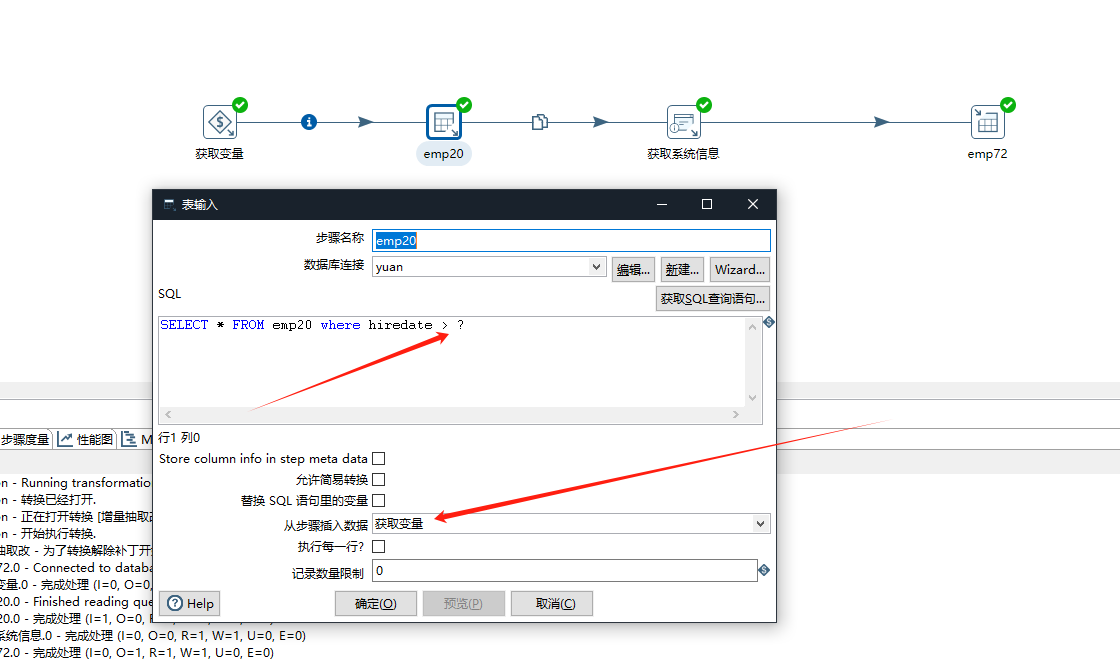
银行数仓项目实战(三)--使用Kettle进行增量,全量抽取
文章目录 使用Kettle进行全量抽取使用Kettle进行增量抽取 使用Kettle进行全量抽取 一般只有项目初始化的时候会使用到全量抽取,全量抽取的效率慢,抽取的数据量大。 我们在第一次进行全量抽取的时候,要在表中新建一个字段记录抽取时间,用于后面方便进行增量抽取。 全量抽取抽取的是T+1天到昨天的23.59分的数据 首先我们需要在目标表中新建一个字段用于记录上次抽取的时间。
特征抽取、特征选择、特征工程
(更新于2019/03/02) 注意:关于这三个名词的概念,网上的一些内容并不是非常权威,当然也有人对这方面的内容做了比较详细的区分,所以看这部分内容的时候就需要仔细甄别,多看不同的内容。 1. 引言 在机器学习的流程中,如图1所示,这是一个完整的循环,针对一个特定的机器学习问题,这个循环应该是一直进行的,直到你对整个的模型性能满意的时候。 图1 机器学习流程[1] 因

抽取BaseAdapter,省代码
看着BaseAdapter,总在那里重复写,嫌烦,然后今天把BaseAdapter封装了一下 BaseAdapter.Java文件 public class CommonAdapter<T> extends BaseAdapter {private LayoutInflater inflater;private List<T> datas;private int layoutId;priv

基于Zero-shot实现LLM信息抽取
基于Zero-shot方式实现LLM信息抽取 在当今这个信息爆炸的时代,从海量的文本数据中高效地抽取关键信息显得尤为重要。随着自然语言处理(NLP)技术的不断进步,信息抽取任务也迎来了新的突破。近年来,基于Zero-shot(零样本学习)的大型语言模型(LLM)在信息抽取领域展现出了强大的潜力。这种方法能够在没有预先标注数据的情况下,通过理解自然语言指令来完成信息抽取任务,极大地提高了
0099__Linux命令-ar命令(建立或修改备存文件,或是从备存文件中抽取文件)
Linux命令-ar命令(建立或修改备存文件,或是从备存文件中抽取文件)_-ar linux-CSDN博客

用kettle调用js抽取数据库照片到本地
本来打算先开发kettle插件的,但是比较麻烦,同时要的比较急,就临时写了个js来; js代码: //Script here//文件路径var filepath = "G:\\zp\\";//相片名称var filename = SFZH+".jpg";//写到硬盘var fos = new Packages.java.io.FileOutputStream(new Packa

复合材料数据整合与自动识别抽取系统
概述:为材料行业的研发提供自动化数据整合与识别抽取系统,以降低研发成本、提升效率并推动行业智能化转型。 客户背景 在复合材料行业中,信息的获取和整合是一个复杂且成本高昂的过程。由于该行业的数据分散在各种文献、报告、网站等渠道,企业在搜集、整理和分析这些信息时面临巨大挑战。这种信息的分散性不仅增加了企业获取有价值信息的成本,而且也影响了企业决策的效率和准确性。此外,随着新材料技术的快速发