本文主要是介绍银行数仓项目实战(三)--使用Kettle进行增量,全量抽取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 使用Kettle进行全量抽取
- 使用Kettle进行增量抽取
使用Kettle进行全量抽取
一般只有项目初始化的时候会使用到全量抽取,全量抽取的效率慢,抽取的数据量大。
我们在第一次进行全量抽取的时候,要在表中新建一个字段记录抽取时间,用于后面方便进行增量抽取。
全量抽取抽取的是T+1天到昨天的23.59分的数据
首先我们需要在目标表中新建一个字段用于记录上次抽取的时间。
我们拿emp表举例
//添加字段
alter table emp72 add lastdate date;
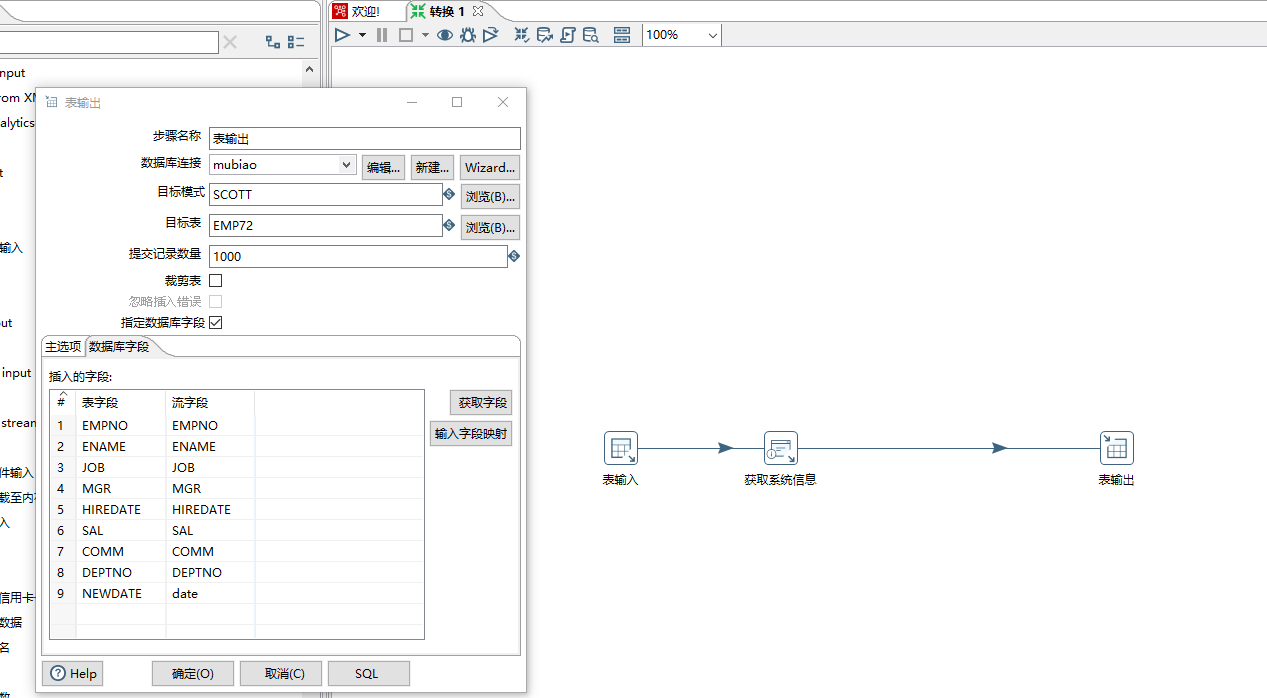
在Kettle中获取系统时间,并将其插入到目标表中,完成全量抽取。
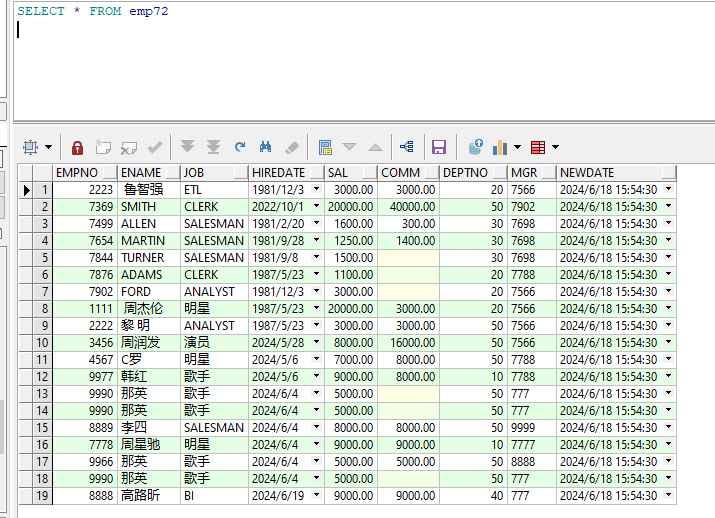
全量抽取完之后,得到的目标emp表如图所示
使用Kettle进行增量抽取
如何判断那一条数据是增量呢?
我们之前全量抽取的时候,设置了上一次的抽取时间为newdate,我们判断新记录可以选择一个字段判断增量,在这个表中,无疑使用hiredate(入职时间)是最佳选择。我们进行增量抽取的时候,只需要判断每一条数据中的hiredate是否大于上一次的抽取时间,如果大于说明是新数据,需要抽取。
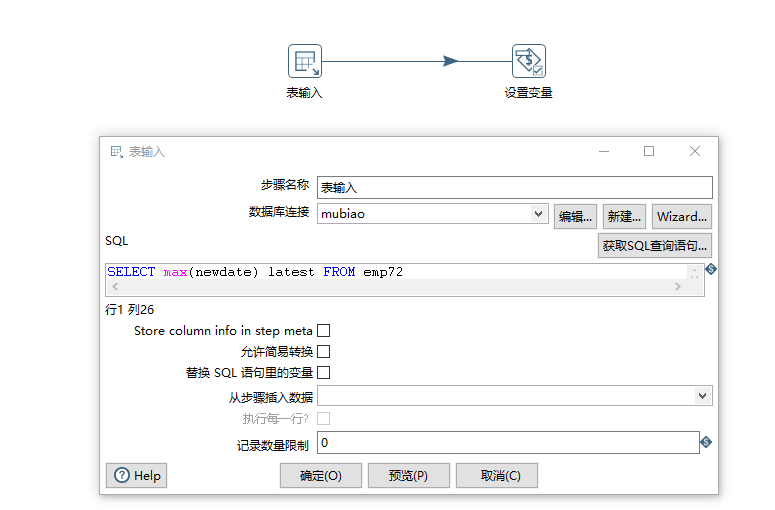
增量抽取中,我们的目标表是旧数据,源表是新数据。我们在目标表中添加了NEWDATE这一行代表上次抽取的时间,上次抽取的时间有很多,可以用MAX(NEWDATE)选择距离我们上次抽取最近的时间。将其作为变量,与源表中入职时间作比较,如果入职时间比上次抽取的时间晚,说明是新数据,我们需要对其进行增量抽取。
将最近的时间设置为变量latest
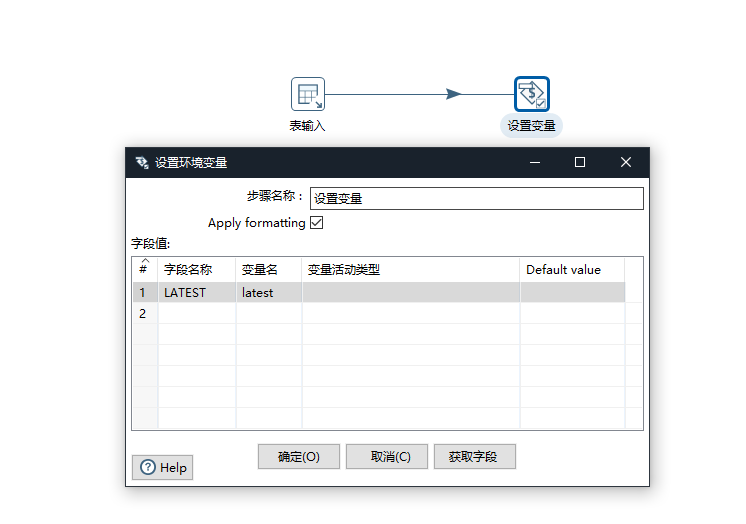
先将这个转换跑一遍,把变量存到系统中去,再执行增量抽取。
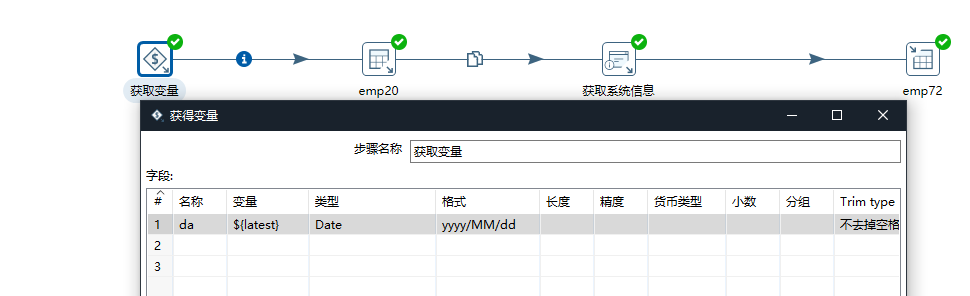
新建一个转换,进行增量抽取。
首先获取上次抽取时间,即刚刚设置的latest变量如上图
注意!变量要用==${xxx}== ,== %%xxx%%==标注
双击源表(emp20)
SQL语句中筛选出hiredate>latest的数据
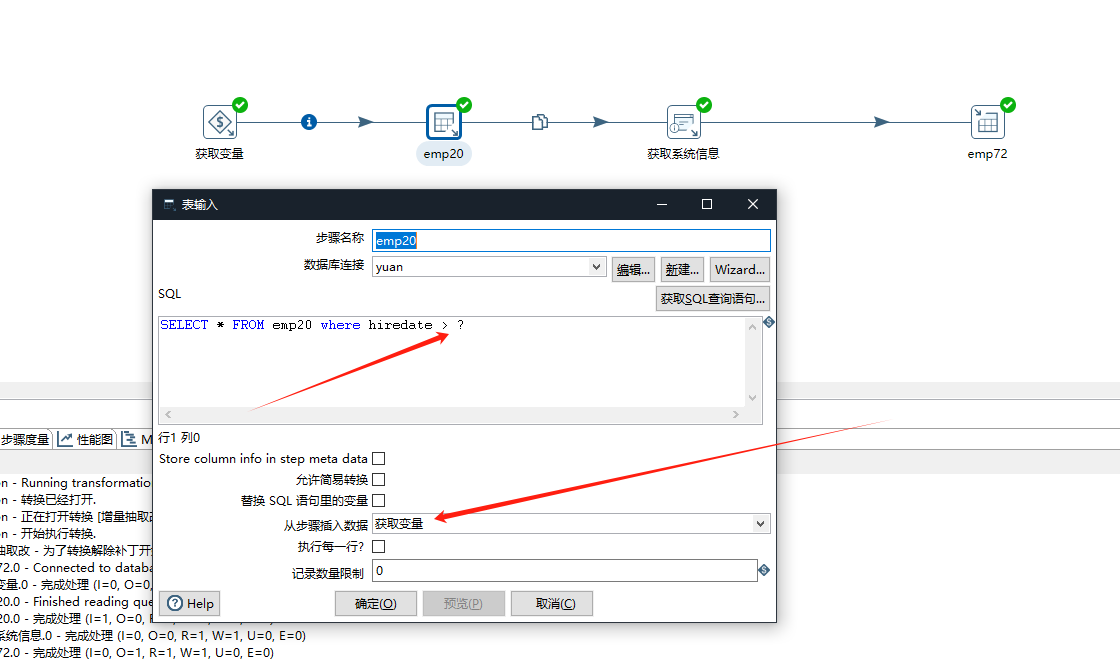
注意,选择 “从步骤中插入数据”有下拉框可以选择指向源表的步骤,如果使用此种方法,前面步骤传入的变量可以使用 ? 代替,如上图==?==代表latest变量,点击确定,其他步骤如全量抽取所示。
这篇关于银行数仓项目实战(三)--使用Kettle进行增量,全量抽取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






