全量专题

大模型全量微调和LoRA微调详细说明,如何避免灾难性遗忘
在使用大模型进行微调时,特别是在语音识别、自然语言处理等任务中经常会遇到两个主要方法:全量微调和LoRA微调。全量微调涉及更新模型的所有参数,而LoRA(Low-Rank Adaptation)则专注于更新少量的参数来适应新的任务。这两种方法各有优缺点,并有不同的应用场景。 全量微调 1. 什么是全量微调? 全量微调是指在微调阶段,更新模型中所有参数。这个过程通常在大规模数据集上进行,以适应

数据仓库系列13:增量更新和全量更新有什么区别,如何选择?
你是否曾经在深夜加班时,面对着庞大的数据仓库,思考过这样一个问题:“我应该选择增量更新还是全量更新?” 这个看似简单的选择,却可能影响整个数据处理的效率和准确性。今天,让我们深入探讨这个数据仓库领域的核心问题,揭示增量更新和全量更新的秘密,帮助你在实际工作中做出明智的选择。 目录 引言:数据更新的重要性增量更新vs全量更新:基本概念增量更新的优势与挑战优势挑战示例:增量更新实现 全量更新的

全量知识系统 设计的数据的三大问题:存储、计算和连接
特征feature Q1: 今天先从全知系统中的“特征feature”说起。在全知系统中,特征作为除线性结构以外的其它组合结构(祖传代码脚本模板)中的槽填充物,为特征提供三种计算:合取积(边缘计算 ,左右聚类法)、加权和(神经元计算,上下分类法)、析取商(云计算,中心周围的集类法)。请理解并详细展开或者提出质疑 在全知系统中,特征(Feature)作为知识实体的一种核心属性,扮演着极其重要的角

大模型全量微调和 LoRA 微调:一看就懂_lora微调
在模型微调领域,全量微调和LoRA微调是我们经常听到的技术术语。 首先,我们需要了解什么是模型微调。模型微调本质上是因为有时我们发现模型在某个方面的性能不足。因此,我们希望通过一些训练方法来更新模型,使更新后的模型在某些方面具有更强的能力。本质上,这是对模型的一种修改。在这里,我们通过数据和基于训练的方法,将现有的模型改造为新模型。 微调的本质 那么模型的修改本质上是对模型参数的修改。因此,

centos7 xtrabackup mysql(8)压缩 全量备份 还原(4)
centos7 xtrabackup mysql(8)压缩 全量备份 还原(4) 查看版本: xtrabackup --version qpress --help 主机端 mysql -u root -p 1234aA~1 use company_pro; insert into employee(name) value (‘20240823_1401’); sudo mkdir -p
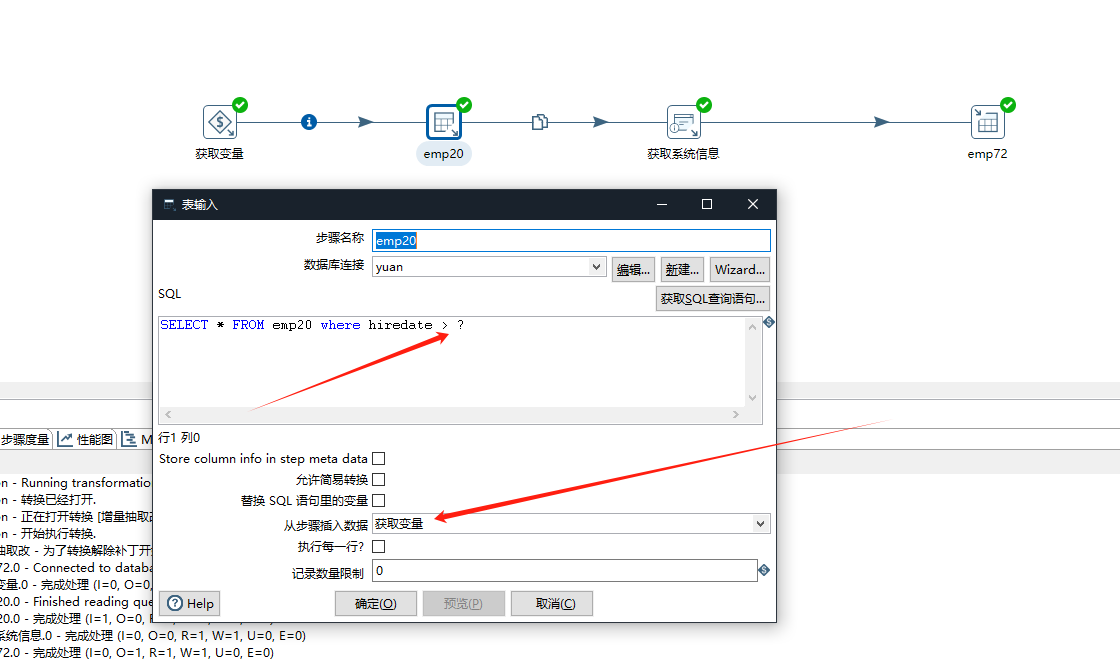
银行数仓项目实战(三)--使用Kettle进行增量,全量抽取
文章目录 使用Kettle进行全量抽取使用Kettle进行增量抽取 使用Kettle进行全量抽取 一般只有项目初始化的时候会使用到全量抽取,全量抽取的效率慢,抽取的数据量大。 我们在第一次进行全量抽取的时候,要在表中新建一个字段记录抽取时间,用于后面方便进行增量抽取。 全量抽取抽取的是T+1天到昨天的23.59分的数据 首先我们需要在目标表中新建一个字段用于记录上次抽取的时间。

开发一个python工具,pdf转图片,并且截成单个图片,然后修整没用的白边及循环遍历文件夹全量压缩图片
§ 今天推荐一键款本人开发的pdf转单张图片并截取没有用的白边工具 § 一、开发背景: 业务需要将一个pdf文件展示在前端显示,但是基于各种原因,放弃了h5使用插件展示 原因有多个,文件资源太大加载太慢、pdf展示兼容性问题、pdf展示效果不好、pdf字体有时缺失等等,所以将项目中的协议等,全部由pdf文档转成图片,因为文档太多,不可能找UI同学一个一个截图,所以我就基于python代码写了三
正则表达式全量分类--手机号身份证电话金钱邮箱银行卡正则表达式
目录 前言: 匹配8-16位数字或字母【用作卡号账户】 匹配电话号码校验(不包含港澳台手机号) 匹配金钱校验,金融需要钱数字的校验 6-18位纯数字 不能以0开头【用作电话号码】 身份证校验【18位身份证正则表达式】 邮箱校验【匹配邮箱格式的正则表达式】 银行卡号校验【匹配银行卡号】 替换手机号中间4位【正则替换脱敏数据展示】 前言: 主要是金融相关软件开发需要设置一
![MySQL 使用 XtraBackup 进行数据热备份指导 [全量+增量]](https://img-blog.csdnimg.cn/20210128155458644.png)
MySQL 使用 XtraBackup 进行数据热备份指导 [全量+增量]
背景 最近一直涉猎 MySQL 数据库的操作、集群部署知识 注意到,为保证数据安全,掌握数据备份是极为重要的 相比小型服务的冷备份而言 在此推荐并整理,更受推崇的 XtraBackup 下的热备份技巧 ☞ 概念了解 [XtraBackup] XtraBackup 是一种物理备份工具,通过协议连接到 MySQL 服务端,然后读取并复制底层的文件,完成物理备份 优势 XtraBacku

kettle从入门到精通 第六十五课 ETL之kettle 执行动态SQL语句,轻松实现全量增量数据同步
本次课程的逻辑是同步t1表数据到t2表,t1和t2表的表机构相同,都有id,name,createtime三个字段。 CREATE TABLE `t1` (`id` bigint NOT NULL AUTO_INCREMENT,`name` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,`cr
【5】MySQL数据库备份-XtraBackup - 全量备份
MySQL数据库备份-XtraBackup-全量备份 前言环境版本 安装部署下载RPM 包二进制包 安装卸载 场景分析全量备份 | 恢复备份恢复综合 增量备份 | 恢复部分备份 | 恢复 前言 关于数据库备份的一些常见术语、工具等,可见《MySQL数据库-备份》章节,当前不再重复概述。本篇主要对 XtraBackup 工具的使用做下详细讲解。 首先,说下所使用的环境、版本。

理解BW DSO/Cube 增量/全量抽数
1.对于数据删除后,怎么抽数使得DSO/Cube实现数据同步? 首先需要说明的是:BW在处理删除没有优势,通过Delta或Full DTP都不能满足要求,目前有两种方法可以实现 第一种:从数据源上下手,增加一个删除标记,在报表展示的时候,filter删除的数据,使得不显示 第二种:伪增量,从Transformation入手,在开始例程中,比较上载的数据和已有数据,设置其指
【Solr6.6.0】Solr对IK分词器的配置、Solr自动生成唯一ID、Solr服务器的增量和全量更新(五)
版权声明:本文为博主原创文章,未经博主允许不得转载。 转载请标明出处:http://blog.csdn.net/u011035026/article/details/79568628
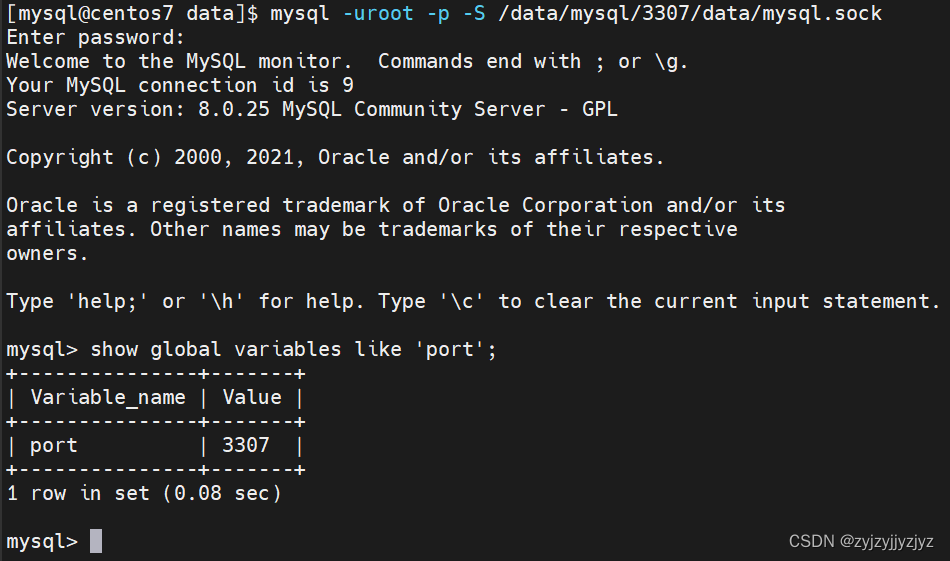
mysql实战——xtrabackup全量备份/增量备份及恢复
一、测试前准备 mysql数据库 端口3306数据文件目录 /data/mysql/3306/data 安装目录/usr/lcoal/mysql配置文件/etc/my.cnf 创建数据库 testXtra 创建备份目录 备份目录/data/backup/备份恢复数据文件目录/data/mysql/3307/data备份恢复配置文件/etc/my_3307.cnf 二、开始测试
Oracle中全量CHECKPOINT和增量CHECKPOINT的区别与作用
全量CHECKPOINT和增量CHECKPOINT对用户都是透明的,而增量CHECKPOINT只不过是将全量CHECKPOINT要写的脏块分时间分批次写到数据文件中而已,此操作可以极大地减少对数据库性能的影响。 全量CHECKPOINT 全量CHECKPOINT是指DBWR进程将脏缓冲区列表中的脏块一次性地写入数据文件中。该操作可以简单地分为2个步骤(这里假设执行全量CHECKPOINT的时间点

华为OD机试【全量和已占用字符集】(java)(100分)
1、题目描述 给定两个字符集合,一个是全量字符集,一个是已占用字符集,已占用字符集中的字符不能再使用。 2、输入描述 输入一个字符串 一定包含@,@前为全量字符集 @后的为已占用字符集;已占用字符集中的字符一定是全量字符集中的字符;字符集中的字符跟字符之间使用英文逗号隔开;每个字符都表示为字符+数字的形式用英文冒号分隔,比如a:1标识一个a字符;字符只考虑英文字母,区分大小写;数字只考虑正整

AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
系列篇章💥 AI大模型探索之路-训练篇1:大语言模型微调基础认知 AI大模型探索之路-训练篇2:大语言模型预训练基础认知 AI大模型探索之路-训练篇3:大语言模型全景解读 AI大模型探索之路-训练篇4:大语言模型训练数据集概览 AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化 AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理 AI大模型探索之路-训练篇7:大语言模型

Windows系统下将MySQL数据库表内的数据全量导入Elasticsearch
目录 下载安装Logstash 配置Logstash配置文件 运行配置文件 查看导入结果 使用Logstash将sql数据导入Elasticsearch 下载安装Logstash 官网地址 选择Windows系统,需下载与安装的Elasticsearch相同版本的,下载完成后解压安装包。 配置Logstash配置文件 在config文件夹下新建一个名为 sql.c
Mysql全量数据迁移(备份+恢复)
linux/windows环境大同小异 1、数据备份 mysqldump命令备份指定数据库全量数据 登录服务器 mysqldump -u 用户名 -p数据库密码 数据库名 > 备份文件地址/database.sql sql脚本备份完成! 2、数据库迁移/恢复 我选用的是source命令,当然也有其他的方式 以下为source命令的方式 1、一般全量sql脚本数据较大,需修改数据
mysql全量备份及数据恢复实践
前置 myql:8.0.34 percona-xtrabackup:percona-xtrabackup-8.0.34-29 一、全量备份脚本 #!/bin/bash#删除历史find /data/backups -mtime +10 -exec rm -rf {} \;#下载备份工具#wget https://file.zjwlyy.cn/percona-xtrabacku
全量知识系统 程序详细设计 master:统一建模 元对象设施 <类别categorization 及其计算器>
Q1. 今天想聊聊 全量知识系统中 的 范畴大辩论 : 三方(论点论证论据)辩论 。 先抛开 全知系统说说“ 范畴大辩论 : 三方(论点论证论据)辩论” 当我们谈到“范畴大辩论:三方(论点、论证、论据)辩论”时,我们实际上是在讨论一个逻辑和论证的基本结构。在任何讨论、辩论或论文中,这三个元素都是至关重要的。 论点(Claim):这是你想要证明或反驳的主要观点。论点应该清晰、明确,并且具有可辩论
全量知识系统 程序详细设计 三次模型:数据模型图算模型和统计模型(QA百度文库)
Q1. 递归迭代和回溯是什么的基本结构,为什么 递归、迭代和回溯都是算法设计中常用的策略,它们各自有不同的基本结构和应用场景。 递归: 基本结构:递归的基本结构包括两个部分:递归终止条件和递归过程。递归终止条件是基本情形,当满足这个条件时,递归停止并返回结果。递归过程是将问题分解为更小的子问题,然后对这些子问题递归调用自身,直到达到终止条件。示例:斐波那契数列的递归实现,fib(n) = f
全量知识系统 程序详细设计 之 计算模型-情态模型中的λ演算图灵机微感机:计算分界“表”/“里”的“边框”(QA 百度文库)
Q1. 你上面说到:λ演算和图灵机是两种不同的计算模型。λ演算是一种函数定义、函数应用和函数等价性的理论,而图灵机是一种抽象的计算设备,用于模拟任何可能的计算过程。那么,请问,在全知系统的程序详细设计中 总结了三种程序语言模型:函数式、声明式和命令式。如果非要将 这两种计算模型(λ演算和图灵机) 对应到三种程序语言模型中,应该λ演算 可以视为 函数式,那推图灵机呢?以及还有一个计算模型应该是什么?
solr通过http方式全量更新索引
启动tomcat,访问http://localhost:8080/solr/dataimport?command=full-import 将数据全部导入solr服务器进行索引 访问http://localhost:8080/solr/dataimport?command=status可以查看运行状态 当修改data-config.xml 文件配置时运行http://localhost:8
全量知识系统 程序详细设计 定稿之 “祖传代码”:Preserving(QA百度文库)
Q1.今天继续聊 全量知识系统 程序详细设计 定稿- “祖传代码”。“祖传代码”表示全知系统的全部“可能的世界”:“Preserving”的一个 Python Class 母版。 采用MVC软件架构,设计了视图V、模型M和控制C 的表示法:HTML+JSP业务页面(命名空间 人机交互界面“准线”),https +Json 数据斑面(天花板-实验室 “法线”) ,restful+SAOP 技术版面(