数仓专题


实时数仓链路分享:kafka =SparkStreaming=kudu集成kerberos
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 本文档主要介绍在cdh集成kerberos情况下,sparkstreaming怎么消费kafka数据,并存储在kudu里面 假设kafka集成kerberos假设kudu集成kerberos假设用非root用户操作spark基
胖哥的经验 | 一款普适的实时数仓架构设计
什么?胖哥的经验,没错这是来自我们大数据成神之路小伙伴的经验。有什么问题,欢迎大家加群讨论,公众号回复【加群】。 一、实时数仓的架构背景 首先我们来聊一聊实时数仓是怎么诞生的,在离线数仓的时候数据是T+1的也就是隔一天才能看到昨天的数据,这种形式持续了很久的时间,但是有些场景真的只有实时的数据才有用武之地。例如推荐、风控、考核等。那么这个时候实时指标也就应运而生,在最开始的时候,采用flink\
Flink1.12集成Hive打造自己的批流一体数仓
简介 小编在去年之前分享过参与的实时数据平台的建设,关于实时数仓也进行过分享。客观的说,我们当时做不到批流一体,小编当时的方案是将实时消息数据每隔15分钟文件同步到离线数据平台,然后用同一套SQL代码进行离线入库操作。 但是随着 Flink1.12版本的发布,Flink使用HiveCatalog可以通过批或者流的方式来处理Hive中的表。这就意味着Flink既可以作为Hive的一个批处

【硬刚大数据】Flink在实时在实时计算平台和实时数仓中的企业级应用小结
欢迎关注博客主页:https://blog.csdn.net/u013411339 欢迎点赞、收藏、留言 ,欢迎留言交流!本文由【王知无】原创,首发于 CSDN博客!本文首发CSDN论坛,未经过官方和本人允许,严禁转载! 本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的面试部分补充。 大数据领域自 2010 年开始,以 Hadoop、Hive 为代

AliExpress基于Flink的广告实时数仓建设
点击上方蓝色字体,选择“设为星标” 回复"面试"获取更多惊喜 大数据面试提升私教训练营上线 Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。 摘要:实时数仓以提供低延时数据指标为目的供业务实时决策,本文主要介绍基于Flink的广告实时数仓建设,主要包括以下内容: 1. 建设背景 2. 技术架构 3. 数仓架构 4. 实时OLAP 5. 实时保障 6. 未

数仓指标一致性以及核对方法
点击上方蓝色字体,选择“设为星标” 回复”面试“获取更多惊喜 数仓数据质量衡量标准 我们对数仓数据指标质量衡量标准通常有四个维度:正确性、完整性、时效性、一致性。 正确性:正确性代表了指标的可信度,如果一个指标无法保证其正确性,那么是不能提供出去使用,因为很有可能会导致作出错误的业务决策,通常会使用明细数据对比、维度交叉对比、实时对比离线等方式校验数据的正确性;另外一方面可以增加一些DQC

数仓基础(六):离线与实时数仓区别和建设思路
文章目录 离线与实时数仓区别和建设思路 一、离线数仓与实时数仓区别 二、实时数仓建设思路 离线与实时数仓区别和建设思路 一、离线数仓与实时数仓区别 离线数据与实时数仓区别如下: 对比方面 离线数仓 实时数仓 架构选择 传统大数据架构 Kappa架构 建设方法 传统数仓主题建模理论 传统数仓主题建模理论 准确性 准确度高 准确度随着技术

数据治理学习笔记(二):在数仓建模过程中,数据治理要怎么做
前言 之前写了点数据治理的大概定义,中间的工作中也接触到了一部分的数据治理(大概是)工作,最近在复习数仓建模的一些东西,正好结合做个整理备忘,按我自己理解的方式去看数据治理。 背景 数仓在大多数场景里都有运用到,这里按数仓分层的逻辑来讲点数据治理的东西。 叠甲 可能有些地方我理解有问题,不在数据治理工作中,就当是自己的工作总结吧,有人提出大的问题,我再改改。小问题就凑合看看,当一个参考。

大数据-数仓-数仓工具:Hive(离线数据分析框架)【替代MapReduce编程;插入、查询、分析HDFS中的大规模数据;机制是将HiveSQL转化成MR程序;不支持修改、删除操作;执行延迟较高】
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。 Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。 Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单

大数据-案例-离线数仓-在线教育:MySQL(业务数据)-ETL(Sqoop)->Hive数仓【ODS层-数据清洗->DW层(DWD-统计分析->DWS)】-导出(Sqoop)->MySQL->可视化
一、商业BI系统概述 商业智能系统,通常简称为商业智能系统,是商业智能软件的简称,是为提高企业经营绩效而采用的一系列方法、技术和软件的总和。通常被理解为将企业中的现有数据转换为知识并帮助企业做出明智的业务决策的工具。 BI系统中的数据来自企业的其他业务系统。例如,一个面向业务的企业,其业务智能系统数据包括业务系统订单、库存、交易账户、客户和供应商信息,以及企业所属行业和竞争对手的数据,以及其他

实时数仓,站上产业潮头
在这场新的数据驱动战场里,谁能更好的对数据进行智能、准确、迅速、高性价比的体系化处理,谁能以更低的成本、更高效的能力构建底层的PaaS、IaaS组件,谁就能在如今的市场竞争中构建更具竞争力的业务模型,成为新的弄潮儿。 对ByteHouse而言,在被越来越多企业选择的如今,属于它的新战场,也更是一个个像布鲁肯一样的降本增效新故事,正在到来。 作者| 皮爷 出品|产业家
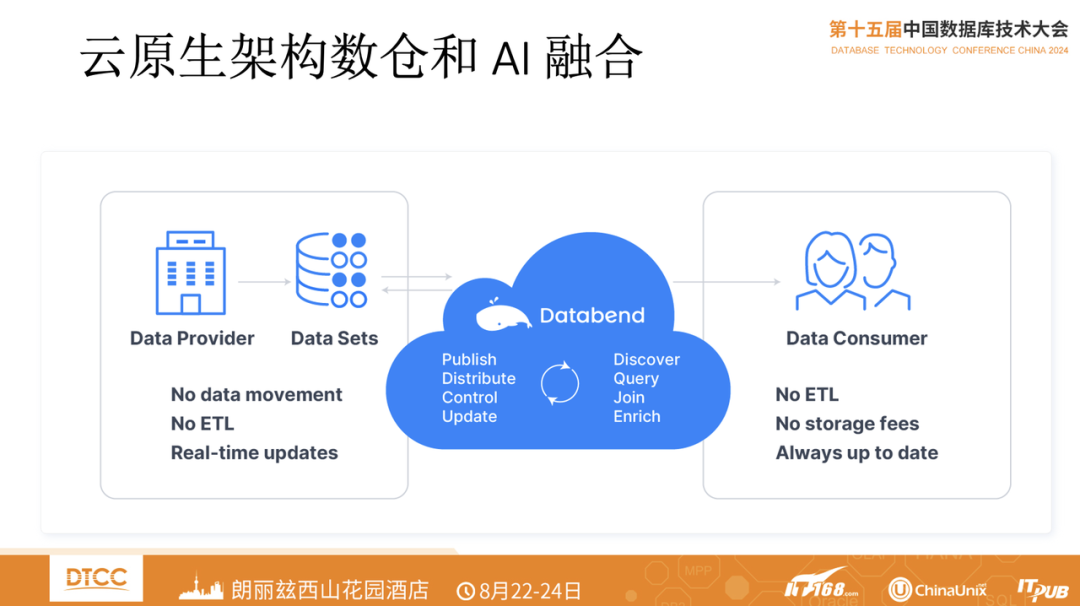
解析云上实时数仓的挑战与实践 | Databend @DTCC 2024 演讲回顾
8 月 22 日 ~ 24 日,由 IT168 联合旗下 ITPUB、ChinaUnix 两大技术社区主办的第 15 届中国数据库技术大会(DTCC2024)在北京朗丽兹西山花园酒店成功召开。本次大会以“自研创新 数智未来”为主题,通过深度交流与探讨,推动数据库技术的自主创新和数智化转型。 作为一家技术领先的数据仓库服务商,Databend 也在本次大会亮相。Databend 联合创始人吴炳锡在
大数据基础:离线与实时数仓区别和建设思路
文章目录 离线与实时数仓区别和建设思路 一、离线数仓与实时数仓区别 二、实时数仓建设思路 离线与实时数仓区别和建设思路 一、离线数仓与实时数仓区别 离线数据与实时数仓区别如下: 对比方面 离线数仓 实时数仓 架构选择 传统大数据架构 Kappa架构 建设方法 传统数仓主题建模理论 传统数仓主题建模理论 准确性 准确度高


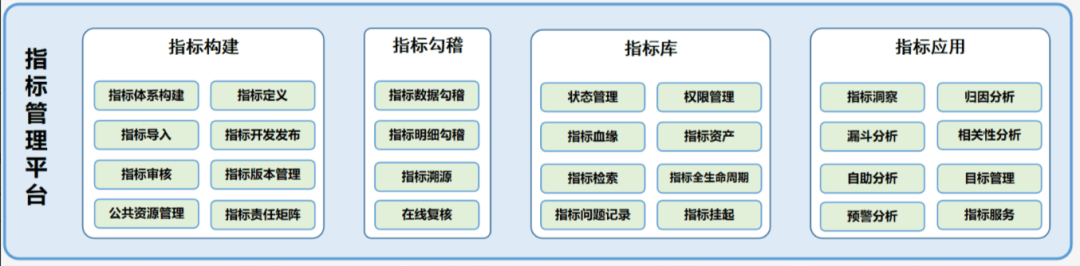
浅谈企业数仓建设及指标管理
随着数据时代的到来,企业正面临着大数据时代下数据管理和分析的挑战。企业数仓作为一个专门用于数据存储和分析的系统,在企业管理中扮演着举足轻重的角色。同时,企业指标管理中同名不同义、同义不同名、口径不清晰、命名难理解、逻辑不准确、数据难追溯的问题层出不穷,直接后果是数据质量差,业务对分析平台的指标数据缺乏信任度,一旦发现数据不符合预期变化,往往首先质疑数据部门,而不是从业务发展的情况出发和分析问题。

大数据基础:数仓架构演变
文章目录 数仓架构演变 一、传统离线大数据架构 二、Lambda架构 三、Kappa架构 四、混合架构 五、湖仓一体架构 六、流批一体架构 数仓架构演变 20世纪70年代,MIT(麻省理工)的研究员致力于研究一种优化的技术架构,该架构试图将业务处理系统和分析系统分开,即将业务处理和分析处理分为不同层次,针对各自的特点采取不同的架

实时数仓Hologres如何支持超大规模部署与运维
2021年11月23日至12月3日,中国信息通信研究院(以下简称“中国信通院”)对第13批分布式分析型数据库共计27款产品进行了大数据产品能力评测。阿里云实时数仓Hologres(原阿里云交互式分析)在报表任务、交互式查询、压力测试、稳定性等方面通过了中国信通院分布式分析型数据库性能评测(大规模),并以8192个节点刷新了通过该评测现有参评的规模记录。 在本次评测中,Hologres是目前通过中

深入理解数据仓库建模——数据湖、数仓一体化
引言 在当今数据驱动的时代,数据仓库和数据湖的结合已经成为企业数据管理的关键。本文将深入探讨数据湖与数据仓库一体化的概念、优势以及实现方法,并结合实际案例,为大家展示如何有效地实现这一目标。 数据湖与数据仓库的区别 数据湖和数据仓库虽然都是用于存储和管理数据的解决方案,但它们在架构、功能和用途上有着明显的区别。 数据湖:数据湖是一个存储大规模原始数据的存储库,可以存储结构化、半结构化和
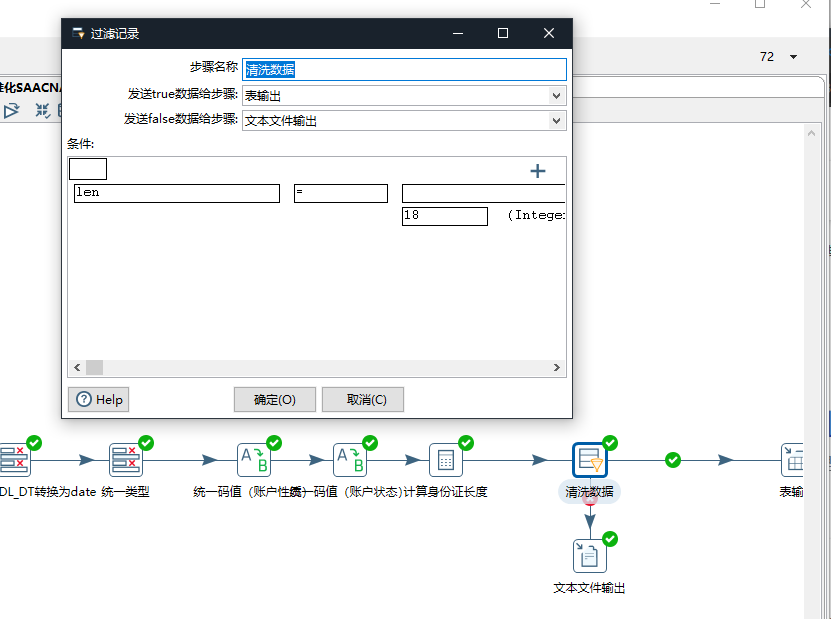
银行数仓项目实战(五)--搭建数仓和数据标准化
文章目录 搭建数仓数据采集 标准层 搭建数仓 数据采集 业务系统源 -》ODS贴源层,添加标签,添加系统来源,添加时间戳 问甲方要建表语句,自己添加etldt字段和来源字段,通过之前文章教的Kettle把数据抽到自己数据库中。 如图成功即可 标准层 要求对SAACNACN表进行数据标准化,要求如下 在oracle中新建一个用户命名为SDS,用来存放标准层数据。 新建转换
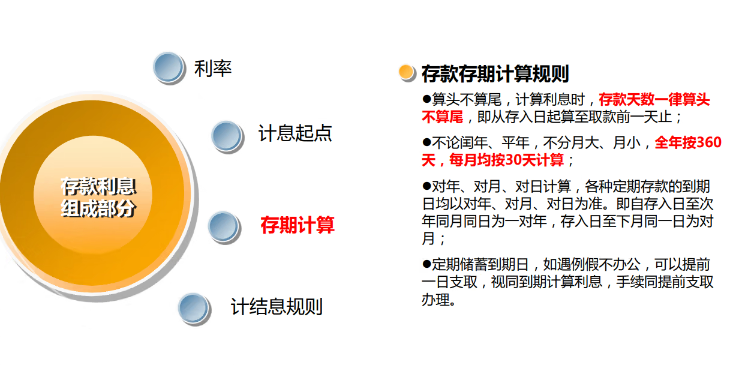
银行数仓项目实战(四)--了解银行业务(存款)
文章目录 项目准备存款活期定期整存整取零存整取存本取息教育储蓄定活两便通知存款 对公存款对公账户协议存款 利率 项目准备 (贴源层不必写到项目文档,因为没啥操作没啥技术,只是数据。) 可以看到,银行的贴源层并不紧贴源数据,而是从数据交换服务读取数据,因为处于安全性考虑,银行不能把敏感数据交给外包服务,因而银行会将必要的数据提交到数据交换服务。 但这样做也有弊端,效率很低。
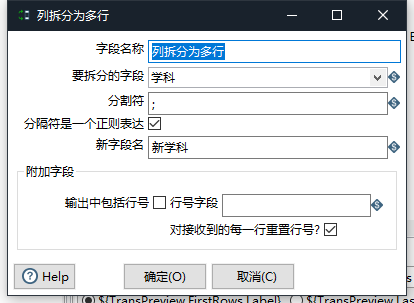
银行数仓项目实战(二)--数据采集(Kettle的抽取(E)转换(T)加载(L))
Kettle安装 Kettle又名PDI 要求电脑中有Java环境。 下载Kettle9.0的安装包,如有需要可以联系up私发噢。 注意!!! 解压路径不能有中文,空格 解压后双击spoon.bat即可使用 链接数据库需要相应的驱动,Oracle的驱动是OJDBC,导入到相应的文件夹中 之后需要重启Kettle ETL:Extract(抽取)-translate(转换)-load(加载)
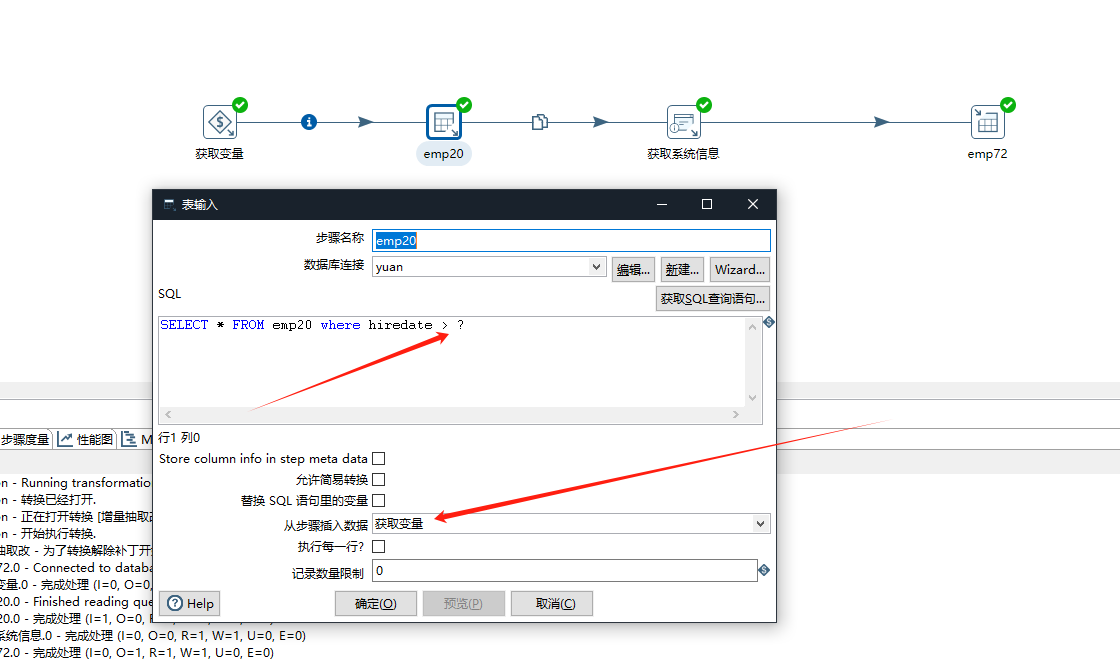
银行数仓项目实战(三)--使用Kettle进行增量,全量抽取
文章目录 使用Kettle进行全量抽取使用Kettle进行增量抽取 使用Kettle进行全量抽取 一般只有项目初始化的时候会使用到全量抽取,全量抽取的效率慢,抽取的数据量大。 我们在第一次进行全量抽取的时候,要在表中新建一个字段记录抽取时间,用于后面方便进行增量抽取。 全量抽取抽取的是T+1天到昨天的23.59分的数据 首先我们需要在目标表中新建一个字段用于记录上次抽取的时间。

数仓开发那些事_番外
一位神州的正式员工(没错,就是之前文章中出现的实习生):一闪,你今年涨工资了吗? 一闪:mad,一年辛苦到头只涨了500米 神州员工:你去年绩效不是优秀吗,怎么就涨了500米,还没我零头多 一闪:放肆! (听说是当时招进来开的工资太高....导致涨薪的时候人资不通过....最后只涨了这么点.....) 一闪表示不理解,但是尊重 ---------------------回到工作
离线数仓VS实时数仓
离线数据仓库(Offline Data Warehouse)和实时数据仓库(Real-time Data Warehouse)的实施有一些相似之处,但也存在显著的差异。以下是两者在几个关键方面的对比: 相同点: 数据集成: 都需要从多个数据源提取、转换和加载数据(ETL/ELT)。都需要处理数据清洗、去重和规范化,以保证数据的一致性和准确性。 数据建模: 都需要进行数据建模,设计数据仓库的星