本文主要是介绍银行数仓项目实战(二)--数据采集(Kettle的抽取(E)转换(T)加载(L)),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Kettle安装
Kettle又名PDI
要求电脑中有Java环境。
下载Kettle9.0的安装包,如有需要可以联系up私发噢。
注意!!!
解压路径不能有中文,空格
解压后双击spoon.bat即可使用
链接数据库需要相应的驱动,Oracle的驱动是OJDBC,导入到相应的文件夹中


之后需要重启Kettle
ETL:Extract(抽取)-translate(转换)-load(加载)
Kettle是一个ETL工具。
Kettle使用
打开Kettle
创建资料库
点击connect
选择Other Repositories
1.Database Repository
是数据库资料库(需要连接数据库)
点击Create
输入对应的数据库实例即可
Oracle如下:
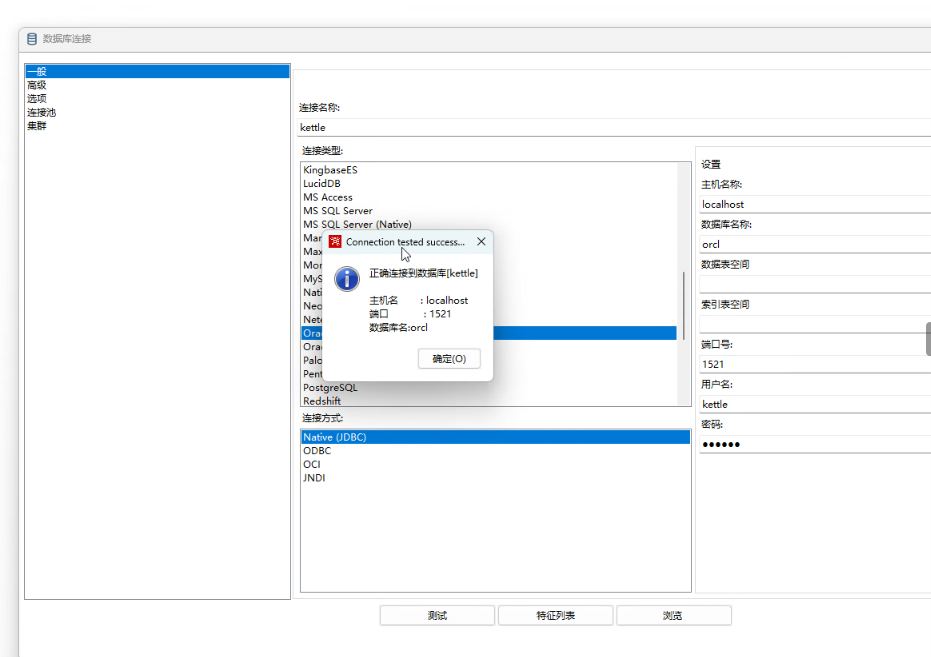
不推荐
2.File Repository
文件资料库
开始创建
起名
选择路径(路径不能有中文!!!!!)
点击finish
接下来做的所有东西都存到新建的文件夹中
连接即可
Kettle可以将数据从源抽取到目标
首先需要Kettle能连接源,又能连接目标
Kettle连接数据库
文件-新建-转换
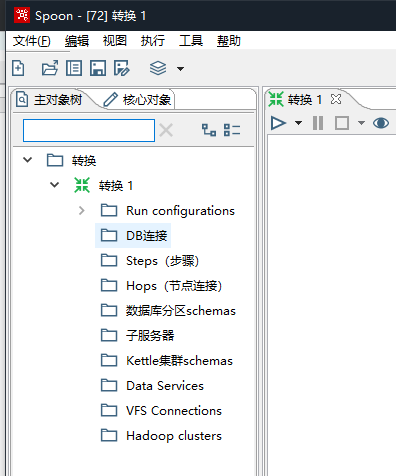
右键DB连接,新建连接,添加源数据库
新建DB连接,添加目标数据库
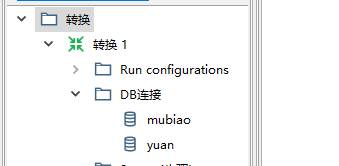
输入代表源
输出代表目标

从输入中,拖出表输入到页面
同样,添加表输出
按住shift连接表输入输出。双击输入输出,根据源,目标对应的数据库实例添加表。
在表输出中选择数据库字段,将其与源一一对应
表字段是目标表的字段,流字段是源表的字段。需要一一对应,否则数据与字段有可能不对应
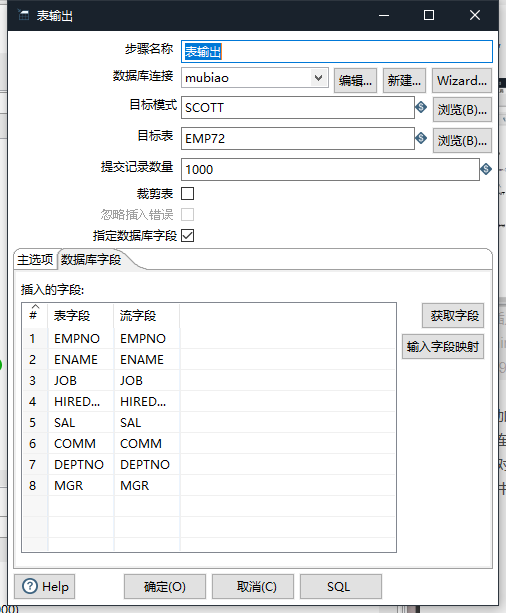
添加完之后点击开始即可抽取数据到目标中。
这就完成了数据的E L 即抽取,加载
转换
都是对应的SQL语句,自己脑海里对应一下
concat fields 合并列
将empname,job合并 添加到目标表中
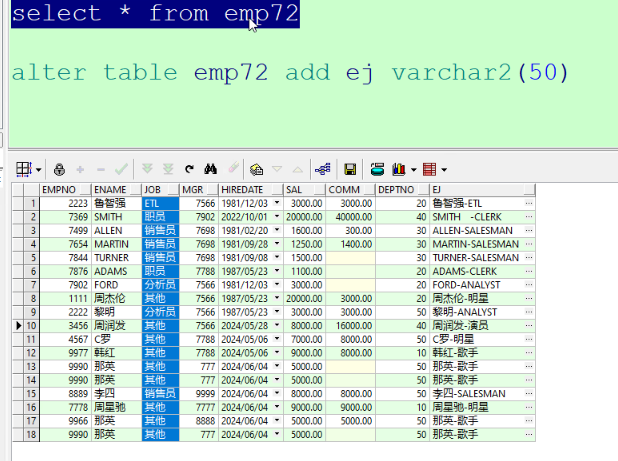
1.首先修改目标表结构
alter table emp72 add ej varchar2(50)
通过Kettle将数据插入
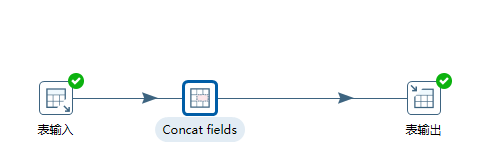
将concat fields添加到线中
双击
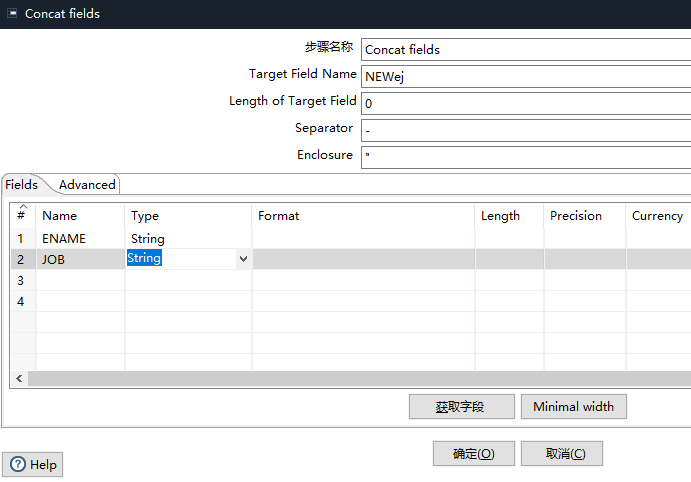
添加如下
运行即可
值映射
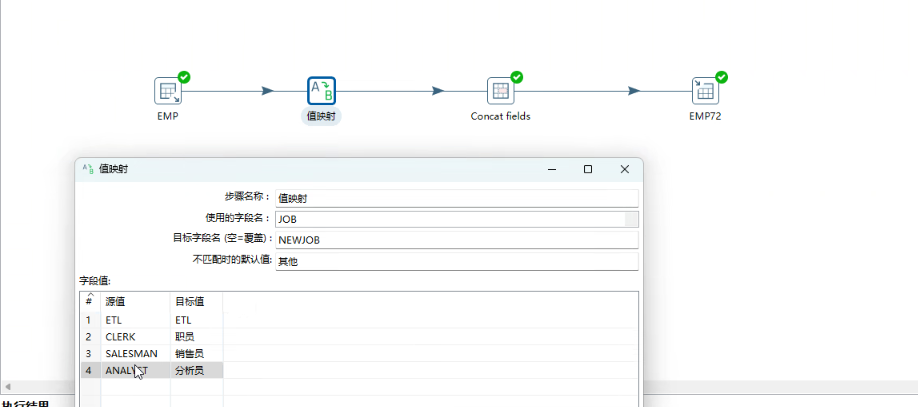
得到结果如下
去重
如果使用去除重复记录按钮去重,需要先排序,不然会出错
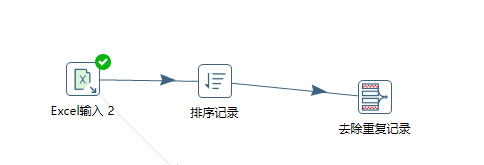
去重完的结果是排序后的
还可以使用唯一行去重,去重的结果是未排序的,但这个去重方法效率更高,如下图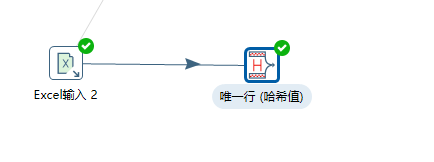
列转行
同样,需要先将表进行排序
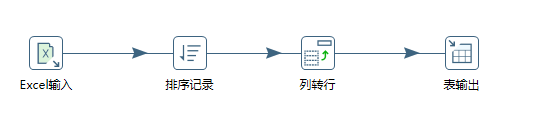
双击列转行
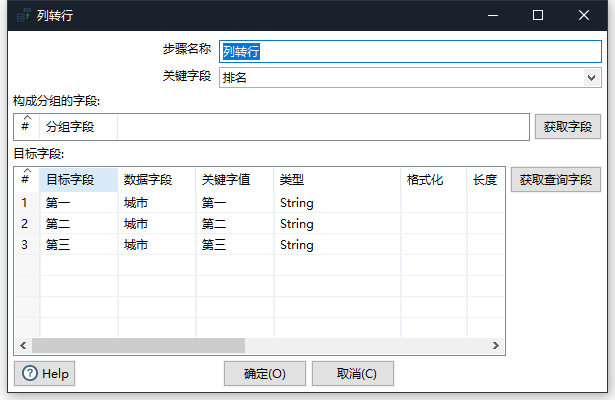
将
需要转行的字段值写进目标字段
将
内容写进数据字段
再
起别名(关键字值)
列拆分多行
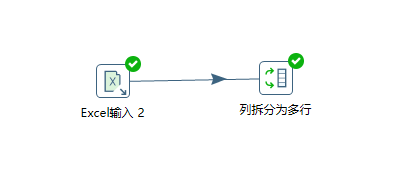
双击列拆分多行,选择要拆分的字段,设置分割符,设置新字段名称
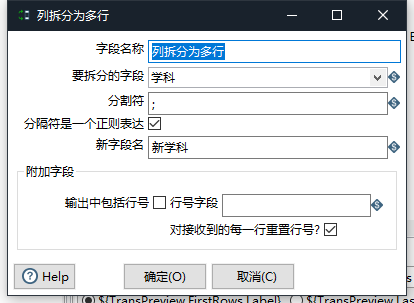
各个组件的用法都跟上面的差不多
注意输入输出后,该组件后面的步骤都需要改变输入字段。(手动匹配中删除之前的对应关系,把新的字段名将其对应)
这篇关于银行数仓项目实战(二)--数据采集(Kettle的抽取(E)转换(T)加载(L))的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








