增量专题

PMP–一、二、三模–分类–14.敏捷–技巧–帮助团队交付价值的执行实践迭代和增量如何帮助交付工作产品
文章目录 技巧一模14.敏捷--实践--帮助团队交付价值的执行实践--持续集成--在不同层面测试、验收测试驱动开发 (ATDD) 、测试驱动开发和行为驱动开发、刺探 。90、 [单选] 敏捷项目的第一次迭代即将开始。发起人召集团队、Scrum主管、产品负责人和其他项目干系人参加启动会议。发起人强调需要在项目尽可能早的时候以最小的成本识别和应对项目风险。与会者实现发起人要求的最佳方式是什么?

SpringBoot 增量部署发布
一、背景介绍 由于项目依赖的jar越来越多,Springboot默认的打包方式是将整个项目打包成一个jar包,每次发布时,打包后的jar越来越大,更新一个很小的功能,需要将整个jar上传运行。这样效率太低了,考虑实现每次发布时,只发布修改了的部分,实现增量发布。 二、实现思路 1.将整体打包的jar进行拆分: 拆为引用的lib和resource(静态资源)两部分(准确说是三部分,还包

SEO如何提高原创内容输出增量?
对于任何一个网站建设运营而言,我们在一个长周期的运营过程中,在某一个时间点,总会遇到发展瓶颈,比如: 流量停止不前。 百度权重,没有明显变化。 特定关键词排名,长期稳定,不升不降。 这个时候我们就需要思考一个问题,我们该如何推动网站继续前进,是增加品牌影响力,还是持续的拓展更多相关性的栏目,从SEO的角度来讲,我们通常会推荐从横行拓展相关性内容来入手,毕竟这样的运营成本相对是非常低的。

后起之秀 | MySQL Binlog增量同步工具go-mysql-transfer实现详解
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 一、 概述 工作需要研究了下阿里开源的MySQL Binlog增量订阅消费组件canal,其功能强大、运行稳定,但是有些方面不是太符合需求,主要有如下三点: 需要自己编写客户端来消费canal解析到的数据server-client模式,需要同时部署server和client两个组件,我们的项目中有6个业务数据库要实时同步到redis

Flink实战案例(二十三):自定义时间和窗口的操作符(四)window functions之增量聚合函数(一)ReduceFunction
实例一 例子: 计算每个传感器15s窗口中的温度最小值 val minTempPerWindow = sensorData.map(r => (r.id, r.temperature)).keyBy(_._1).timeWindow(Time.seconds(15)).reduce((r1, r2) => (r1._1, r1._2.min(r2._2))) 实例二 ReduceFun

【大数据】Canal实现MySQL数据增量同步至Kafka:原理与配置解析
文章目录 一、引言:Canal简介二、数据提取原理:Binlog与Canal的协同工作1. Binlog简介2. Canal工作原理 三、Canal配置解析:搭建MySQL到Kafka的数据桥梁1. MySQL配置(1)开启Binlog:(2)创建Canal用户并授权: 2. Canal配置(1)下载Canal:(2)解压并修改配置文件:(3)启动Canal: 3. Kafka配置(1)下载

增量式数字PID算法的Matlab实现
PID微分方程 基本的PID控制器的微分方程是: (1) 增量式PID 随着计算机的出现,我们需要把模拟的PID离散化,以便能在计算机中处理,公式(1)中的积分项和微分项不能使用,必须经过离散化处理,我们假设:T---采样周期,K--采样的序列,则可以用离散的 KT 代替 连续时间 t 。我们可以得到如下公式: 最后我们得到离散式PID公式如下: 增量

Datax 支持增量 oracle writeMode update
Datax 支持增量 oracle update datax介绍支持增量 oracle update修改 OracleWriter.java修改WriterUtil.java修改CommonRdbmsWriter.java效果源码 datax介绍 DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgr

Datax 支持增量 postgresql writeMode update
Datax 支持 postgresql update datax介绍支持增量 postgresql update修改 PostgresqlWriter.java修改WriterUtil.java效果源码 datax介绍 DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、AD

【sphinx】 配置文件之增量数据源
来看段代码 #增量数据源source incrementtest: test{sql_ranged_throttle = 100sql_query_pre = insert into t values ('')sql_query = inse

告别数据孤岛:数据增量同步方案助力企业数据整合
为了更高效、更经济地管理和传输数据,特别是在数据量大、更新频繁的环境中,企业需要通过数据增量同步方案来解决。 数据增量同步方案是一种数据同步技术,只同步自上次同步以来发生变化的部分数据,而不是同步整个数据集。具有以下作用: 1.减少数据传输量:在文件同步过程中,如果只同步发生变化的部分,可以显著减少数据传输量,这对于带宽有限或成本敏感的环境尤为重要。 2.提高同步效率:增量同步仅更新变化
数据库中自增量字段和Guid字段的比较
据库中使用自增量字段与Guid字段主键的性能对比 1.概述: 在我们的数据库设计中,数据库的主键是必不可少的,主键的设计对整个数据库的设计影响很大.我就对自动增量字段与Guid字段的性能作一下对比,欢迎大家讨论. 2.简介: 1.自增量字段 自增量字段每次都会按顺序递增,可以保证在一个表里的主键不重复。除非超出了自增字段类型的最大值并从头递增,但这几乎不可
maven 增量编译遇到的坑
问题:在打包一个通用的JAR包时,我引用了其他模块的代码,但这些引用模块的代码在打包前发生了修改,结果在使用这个JAR包时总是出现错误。 解决方法:可以选择从项目根目录进行打包,这样整个项目会重新编译,所有模块的修改都会更新到JAR包中。或者,先单独重新编译并安装被引用的模块,然后在打包时重新引用更新后的模块。
js增量更新算法研究
原文链接:https://caelumtian.github.io/2017/09/18/js增量更新算法研究/ serviceWorker 方案 - js增量更新算法研究 调研背景 根据之前 serviceWorker 的调研,当服务端文件更新后,serviceWorker 会做对比,并请求这些新的文件。所有发生变化的文件都会被更新。现在 new-mini 内嵌页面,js 都被压缩成了一个文

建模杂谈系列249 增量数据的正态分布拟合
说明 从分布开始,分布又要从正态开始 假设有一批数据,只有通过在线的方式增量获得。 内容 1 生成 先通过numpy生成一堆随机数据,从3个正态分布生成,然后拼接起来。 import numpy as npimport matplotlib.pyplot as pltfrom sklearn.mixture import GaussianMixture# 生成示例数据np.

数据仓库系列13:增量更新和全量更新有什么区别,如何选择?
你是否曾经在深夜加班时,面对着庞大的数据仓库,思考过这样一个问题:“我应该选择增量更新还是全量更新?” 这个看似简单的选择,却可能影响整个数据处理的效率和准确性。今天,让我们深入探讨这个数据仓库领域的核心问题,揭示增量更新和全量更新的秘密,帮助你在实际工作中做出明智的选择。 目录 引言:数据更新的重要性增量更新vs全量更新:基本概念增量更新的优势与挑战优势挑战示例:增量更新实现 全量更新的

<PLC><编码器>汇川Eazy521系列PLC与欧姆龙增量编码器E6HZ-CWZ6C连接及读取实例
前言 本系列是关于PLC相关的博文,包括PLC编程、PLC与上位机通讯、PLC与下位驱动、仪器仪表等通讯、PLC指令解析等相关内容。 PLC品牌包括但不限于西门子、三菱等国外品牌,汇川、信捷等国内品牌。 除了PLC为主要内容外,PLC相关元器件如触摸屏(HMI)、交换机等工控产品,如果有值得记录的内容,也会添加进来。 环境配置 系统:windows 软件:PLC编程软件(依品牌而定,如博图)
机器学习概述,深度学习,人工智能,无监督学习,有监督学习,增量学习,预处理,回归问题,分类问题
一、人工智能课程概述 1. 什么是人工智能 人工智能( Artificial Intelligence )是计算机科学的一个分支学科,主要研究用计算机模拟人的思考方式 和行为方式,从而在某些领域代替人进行工作 . 2. 人工智能的学科体系 以下是人工智能学科体系图: 机器学习( Machine Learning ):人工智能的一个子

数据仓库中的表设计模式:全量表、增量表与拉链表
在现代数据仓库中,管理和分析海量数据需要高效且灵活的数据存储策略。全量表、增量表和拉链表是三种常见的数据存储模式,各自针对不同的数据管理需求提供了解决方案。全量表通过保存完整的数据快照确保数据的一致性,增量表则通过记录数据的变化部分优化性能和存储效率,而拉链表则通过维护数据的历史版本满足复杂的分析和审计需求。了解这三种表的特点和应用有助于设计更为高效和可靠的数据仓库系统。 全量表(Full

使用canal增量同步ES索引库数据
Canal增量数据同步利器 Canal介绍 canal主要用途是基于 MySQL 数据库增量日志解析,并能提供增量数据订阅和消费,应用场景十分丰富。 github地址:https://github.com/alibaba/canal 版本下载地址:https://github.com/alibaba/canal/releases 文档地址:https://github.com/aliba

CV-Paper-增量学习-Large Scale Incremental Learning
目录 0 简介1 什么是偏差2 网络3 loss4 偏差矫正层 0 简介 就简单的说明一下好了,首先是使用蒸馏学习,然后再利用验证集来学习一个简单的线性变换 ax + b 来减少偏差。 这里是把验证集也拿过来训练了,虽然只是学习一个简单的线性变换,因为这个线性变换只有两个参数,所以需要的数据量非常少,虽然这个变换很简单,但是非常有效的提高精度。 文章中说的偏差指的是增量学习
CV-笔记-增量学习incremental learning
又是一种深度学习的学习策略。 自然学习(Natural learning)系统本质上是渐进的,新知识是随着时间的推移而不断学习的,而现有的知识是保持不变的。现实世界中的许多计算机视觉应用程序都需要增量学习能力。例如,人脸识别系统应该能够在不忘记已学过的面孔的情况下添加新面孔。然而,大多数深度学习方法都存在灾难性的遗忘——当无法获得过去的数据时,性能会显著下降。 旧类数据的缺失带来了两个挑战:(

「数组」希尔排序 / 区间增量优化(C++)
目录 概述 思路 核心概念:增量d 算法过程 流程 Code 优化方案 区间增量优化 Code(pro) 复杂度 概述 我们在「数组」冒泡排序|选择排序|插入排序 / 及优化方案(C++)中讲解了插入排序。 它有这么两个特点: ①待排序元素较少时效率高。 ②待排序元素较有序时效率高。 正如同快速排序时冒泡排序的究极promax进化版,希尔排序则是充分利用了这两个

datax关于postsql数据增量迁移的问题
看官方文档是不支持的 数据源及同步方案_大数据开发治理平台 DataWorks(DataWorks)-阿里云帮助中心 (aliyun.com) 看了下源码有个postsqlwriter 看了下也就拼接sql 将 PostgresqlWriter中的不允许更新先注释了 让他过去先 然后看到 WriterUtil中的对应方法 getWriteTemplate 确实只有对应mysq
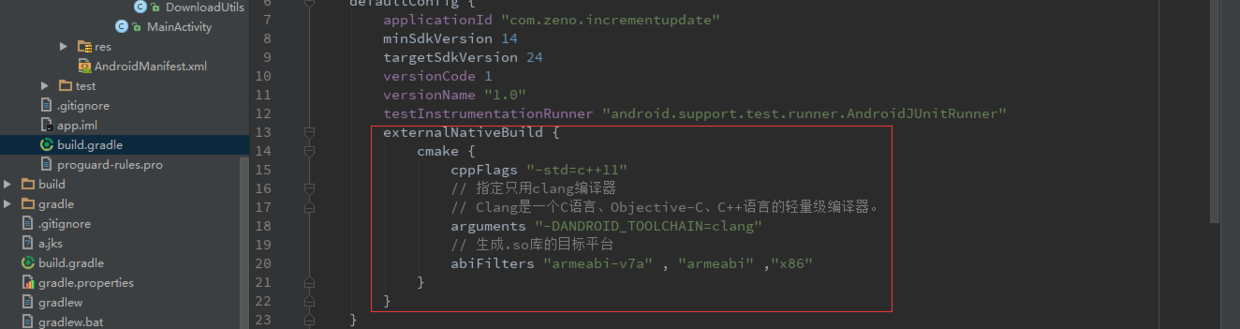
手把手带你实现Android增量更新
Android增量更新技术在很多公司都在使用,网上也有一些相关的文章,但大家可能未必完全理解实现的方式,本篇博客,我将一步步的带大家实现增量更新。 为什么需要增量更新? 当我们开发完一个项目之后,上线维护 , 增加新功能 , 添加第三方库 , APK大小从4 - 5M , 增长到10+M , 用户由原来的几十秒下载 , 到现在几分钟以上的下载 , 网络情况不好的时候 , 或许就是十分钟不等。每