大批量专题

Redis KEYS查询大批量数据替代方案
《RedisKEYS查询大批量数据替代方案》在使用Redis时,KEYS命令虽然简单直接,但其全表扫描的特性在处理大规模数据时会导致性能问题,甚至可能阻塞Redis服务,本文将介绍SCAN命令、有序... 目录前言KEYS命令问题背景替代方案1.使用 SCAN 命令2. 使用有序集合(Sorted Set)

大批量替换oracle中字段
【背景】项目中有需求对特定表A中数据进行替换,其中匹配表B跟A表有主键对应,区别于传统的UPDATE操作,下面的这个方法速度极快 merge into program_test t using daiyu_shichang a on (t.programid = a.programid) when matched then update set t.duration = a.shichang
[240620] 英特尔将使用其 3纳米级工艺技术大批量投入生产 | 科学家开发新算法来发现人工智能的“幻觉”
目录 英特尔将使用其 3纳米级工艺技术大批量投入生产科学家开发新算法来发现人工智能的“幻觉” 英特尔将使用其 3纳米级工艺技术大批量投入生产 英特尔周三表示,其名为 Intel 3 的 3纳米级工艺技术已经在两个生产基地进入大规模生产 新工艺不仅提升了性能和晶体管密度,还支持用于超高性能应用的 1.2V 电压近期推出的英特尔至强 6 Sierra Forest 和 Grani
leaflet,canvas渲染目标,可加载大批量数据
基于Leaflet-CanvasMarker: 在Canvas上绘制Marker,而不是每个marker插件一个dom节点,极大地提高了渲染效率。主要代码参考自 https://github.com/eJuke/Leaflet.Canvas-Markers,不过此插件有些Bug,github国内不方便,作者也不维护了,所以在gitee上新建一个仓库进行维护。https://gitee.com/pa
MySQL插入大批量数据时报错“The total number of locks exceeds the lock table size”的解决办法
事情的原因是:我执行了一个load into语句的SQL将一个很大的文件导入到我的MySQL数据库中,执行了一段时间后报错“The total number of locks exceeds the lock table size”。 首先使用命令 show variables like '%storage_engine%' 查看MySQL的存储引擎: mysql> show variab

mysql大批量删除(修改)The total number of locks exceeds the lock table size 错误的解决办法
一、问题描述 开发中对一张大表进行批量的更新或者删除的时候 会报以下错误: The total number of locks exceeds the lock table size 从字面上理解,就是当前操作锁住的总行数已经超过设置的锁表的大小。 二、解决办法 解决方案一:分批进行更新或者删除 如给delete 语句后面加上limit ,一次 1w条 delete fr
ES大批量写入提高性能的策略
1、用bulk批量写入 你如果要往es里面灌入数据的话,那么根据你的业务场景来,如果你的业务场景可以支持让你将一批数据聚合起来,一次性写入es,那么就尽量采用bulk的方式,每次批量写个几百条这样子。 bulk批量写入的性能比你一条一条写入大量的document的性能要好很多。但是如果要知道一个bulk请求最佳的大小,需要对单个es node的单个shard做压测。先bulk写入100个doc
大批量到处excel,防止内存溢出
最近在做项目功能时 ,发现有20万以上的数据。要求导出时直接导出成压缩包。原来的逻辑是使用poi导出到excel,他是操作对象集合然后将结果写到excel中。 使用poi等导出时,没有考虑数据量的问题,大数据量无法满足,有个几千行jvm就哭了。更别提几万行几百万行数据了。 经过一天的研究发现一种不会消耗过多内存的方法: 导出成csv格式 大数据量的导出成csv格式分为以下几步: 1.首先
MySQL删除大批量表的数据
先删表后建表 -- 删除表DROP TABLE table_name;-- 创建表CREATE TABLE table_name (...); 使用DROP TABLE:这种方式删除数据也比较快,直接删除整个表结构和数据。但是,这个操作不能回滚,约束和索引会释放,需要重新创建表结构。 清空表 TRUNCATE TABLE table_name; 使用TRUNCATE TABL

testbench测试大批量数据
源代码: module example_1(input clk,input [7:0] a_in,output [7:0] b_out);reg [7:0]b_out;reg [7:0]c;always @(posedge clk)beginc<=a_in;b_out<=c; endendmodule 激励文件: module example_1tb();reg clk;reg [7:0
Windows使用MySQL命令行导入大批量sql文件
现在有一个509MB的SQL文件,需要导入到MySQL数据库中 1. Navicat导入失败 一开始当然是准备用Navicat去尝试,结果发现报错MySQL has gone away,于是选择MySQL命令行 2. MySQL命令行导入 确认如下MySQL命令可以成功运行 C:\Program Files\MySQL\MySQL Server 5.7\bin>mysql --versi
Hana中的大批量随机数据生成
微信公众号:数据库杂记 个人微信: _iihero我是iihero. 也可以叫我Sean.iihero@CSDN(https://blog.csdn.net/iihero) Sean@墨天轮 (https://www.modb.pro/u/16258)iihero@zhihu (https://www.zhihu.com/people/iihero)数据库领域的资深爱好者一枚。SAP
Loader大批量加载时,有些loader不会触发COMPLETE事件
症状: 当用下面的形式加载文件时,OnComplete事件并不响应1000次。有时可能1次都不响应 for( var i:int = 0; i < 1000; i++) { var loader:Loader = new Loader(); loader.contentLoaderInfo.addEventListener(Event.COMPLETE, OnComplete); lo
phpspreadsheet读取大批量数据时内存溢出解决办法
需求:一次性读取几万条excel数据并保存到数据库中 问题:当excel超过五万条时内存溢出,程序直接停止 解决办法:将表格切割成多个csv文件,每次只读取一部分数据,大大缓解服务器内存压力,缺点是处理时间会变长,适用于对时间要求不是很高的场景。 建议:小于两万五千条时phpspreadsheet直接读取,大于时采取分割法,下边只附分割法的代码 /*** 预读过滤类* @author wa

全域电商数据实现高效稳定大批量采集♀
全域电商,是近几年的新趋势,几乎所有商家都在布局全域,追求全域增长。但商家发现,随着投入成本的上涨,利润却没有增加。 其中最为突出的是——商家为保证全域数据的及时更新,通过堆人头的方式完成每日取数任务时,产生的人力、时间成本和潜在的人工取数易出错、账号被封成本。 这里我们可以通过封装的电商API接口数据采集的方式,实现高效稳定大批量的电商商品数据采集。 第一步 【查看演示】 ◐◐◐

服务器提交任务和直接运行,服务器端大批量提交计算任务的方法
引言服务器端批量提交任务 引言 许多科研活动涉及大量繁重的计算任务,如分子模拟,量化计算,数据分析等等。往往这些计算都由服务器来完成。大致的流程如下: 通常科学计算用服务器安装的都是linux等系统,且受限于网络速度,与用户的交互界面也是命令行式的(还记得dos吧)。在linux下,任何东西都是文件,任何事情都可以通过操作文件来实现。这是非常灵活的设计,方便我们定制一些特殊功能,利用好这些特性

curl多线程大批量分片下载大文件源码示例
这段时间,一直在探索使用curl多线程来下载一系列的大文件的可行性方法。下面是我探索的结果: 1.将大文件分为许多小片段,比如20M一个片段(当然这个值可以配置,比如100M一个片段,取决于你的业务需求),使用http range来下载这些片段; 2.使用预先生成的线程池来连续不间断地执行文件片段的下载,这个线程池也就是一个固定线程个数的普通线程池,使用互斥锁和信号量来保护任务队列,各work
Linux下rename命令的用法——适合大批量修改文件名
原文地址:http://blog.csdn.net/liyibo373/article/details/71747313 linux下rename命令的用法——适合大批量修改文件名 在看鸟哥私房菜的时候,遇到了mv这个可以修改文件名的命令。后面还有一个命令,叫rename。鸟哥让自己man帮助查询。结果自己一看,发现这个命令居然可以批量的修改文件名。首先,看下man帮助里面的说明: For
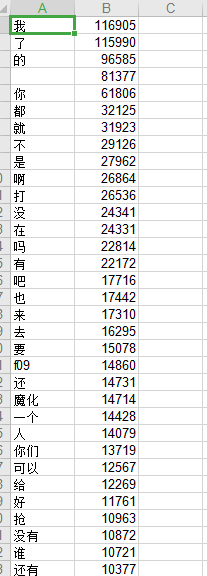
python 大批量文本分词 以及词频统计 (高效处理案例)
环境:python3.6 库:jieba,xlwt,xlwings,collections 前两天有个需求要对一张表里的中文语句进行分词,并统计每个词语出现的次数。 表格1231.xlsx大致内容如下: 由于表格内容过大,约有100W条数据,普通读取表格的方式效率非常慢,所以这次用的方法是xlwings, xlwings是目前看来操作excel最快速、做的比较完善的一个库,优化
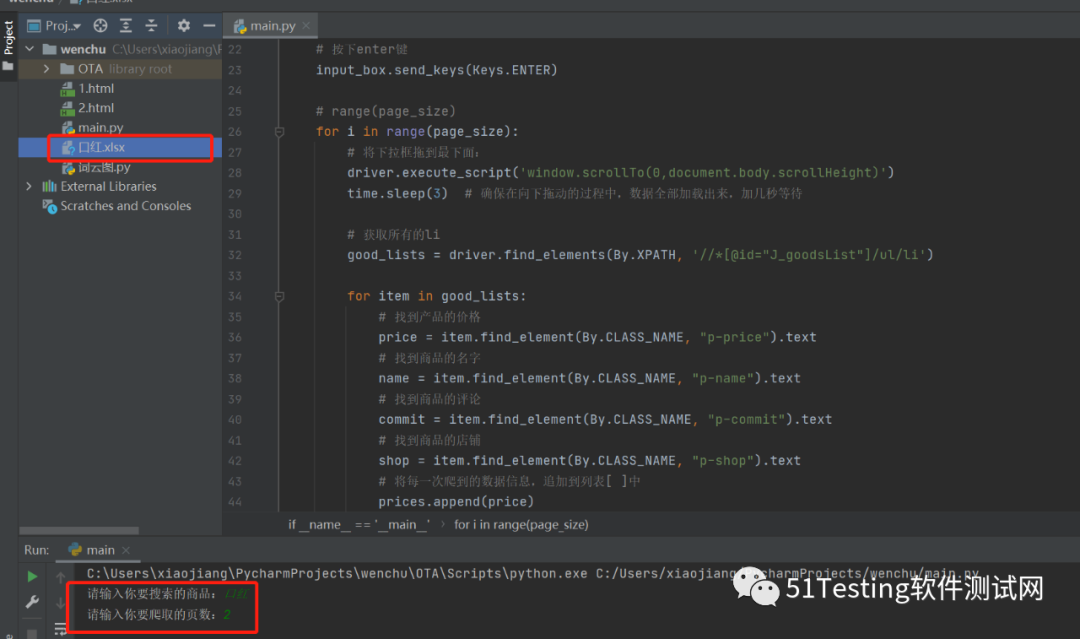
实例操作教你爬取京东的商品数据|实现大批量数据采集API接口
数据采集API接口可以实现搜索及商品详情数据的大批量稳定采集 提出问题 如何在京东商城爬取出各个商品的相关信息(价格、名称、评价、店铺名等等),比如,打开web京东网站,在搜索框输入关键字:口红。那么商品展示列表的所有商品的信息,怎么爬下来,怎么保存到表格中? 我们来看看怎么实现这个功能。 解决思路 1、打开网站,输入关键字,点击搜索按钮; 2、将右侧下

OCR技术3-大批量生成文字训练集
如果是想训练一个手写体识别的模型,用一些前人收集好的手写文字集就好了,比如中科院的这些数据集。但是如果我们只是想要训练一个专门用于识别印刷汉字的模型,那么我们就需要各种印刷字体的训练集,那怎么获取呢?借助强大的图像库,自己生成就行了! 先捋一捋思路,生成文字集需要什么步骤: 确定你要生成多少字体,生成一个记录着汉字与label的对应表。确定和收集需要用到的字体文件。生成字体图像,存储在规定的目
Elastic Search 大批量数据导入设置
1、大批量导入数据前,做一些配置,避免花费太多时间: put http://xxx.xxx.xxx.xxx:9200/index_xxx/_settings { "index.number_of_replicas": 0, # 备份分配数量 "index.refresh_interval" : "-1", # 从index-buffer刷新到filesystem cache
Elasticsearch索引数据大批量删除接口优化
Elaticsearch索引数据大批量删除接口优化 一、需求二、索引数据删除接口2.1使用到的elasticsearch核心接口2.2封装删除脚本2.3封装接口实现 三、Lucene分段处理的优化3.1、refersh3.2、flush3.3、合并策略3.4、存储限流3.5、存储3.6、使用postman设置索引级配置 四、删除接口运行效率统计分析五、继续优化 一、需求 每隔一段

快速复制文件目录下大批量的文件名
方法一:cmd的tree命令 1.CD到指定目录下: C:\Users\alex>e: E:\>cd test E:\test> 2.输入命令:tree /f >test.txt 即tree /f >文件名(此处文件名可是相对路径也可是绝对路径,若是相对路径则存于当前目录下,此文件可已存在也可不已存在于硬盘中,若不存在则此命令可自动创建) E:\test>tree /f >test
大批量快速导入导出数据[SqlServer+批处理]
用Nunit的单体测试时等,有很多时候,需要频繁导入导出数据,下面就以sql server为例介绍一下。 当然,方法有很多种,这里简单介绍自己认为比较高速的批处理[bcp]命令。 ------------------------正文

大批量查询1公里范围内的地标点方法
已知要查询某点经纬度1公里范围内的地标点,查询解决方法: 1、发布图层方法:使用arcgis,自己发布map服务图层,在根据点做一个1公里范围圆,跟发布的图层做相交判断,可以返回相交的一些地标点数据和相关属性值; 2、后台查询数据库方法: 1)大批量数据查询时,肯定不可以一条条的地标点数据进行匹配,这个时候需要加上条件限制,辟如经纬度的大小,约定好需要查询的地点范围进行筛选,会提高