本文主要是介绍Elasticsearch索引数据大批量删除接口优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Elaticsearch索引数据大批量删除接口优化
- 一、需求
- 二、索引数据删除接口
- 2.1使用到的elasticsearch核心接口
- 2.2封装删除脚本
- 2.3封装接口实现
- 三、Lucene分段处理的优化
- 3.1、refersh
- 3.2、flush
- 3.3、合并策略
- 3.4、存储限流
- 3.5、存储
- 3.6、使用postman设置索引级配置
- 四、删除接口运行效率统计分析
- 五、继续优化
一、需求
每隔一段时间,删除N天前的数据,索引只保留最近几天的数据(索引不是按照日期生成的,不能直接删除整个索引)。【elasticsearch-version-5.x】
二、索引数据删除接口
使用接口_delete_by_query,定期向集群提交批量删除任务,http请求不用等待删除任务完成才返回,而是在提交任务之后即时返回任务ID。使用_tasks接口定期检查删除任务的运行状态。这种方式解决了在删除大批量数据的时候Read timed out问题(_delete_by_query接口设置批量提交对于这个问题无解)。
在实际工程使用中,我们需要把elasticsearch的http接口全部封装为JavaWeb工程开发者易于使用和理解的依赖工程的形式。因此在下面的实现中保留此种方式,没有完全按照脚本的形式实现,而是通过jar+shell的形式实现这个功能,并且在封装的es接口包里面保留了这个删除接口。
2.1使用到的elasticsearch核心接口
# _delete_by_query接口
http://localhost:9210/indexName/indexType/_delete_by_query?refresh=true&scroll_size=1000&conflicts=proceed&wait_for_completion=false
# _tasks接口
http://localhost:9210/_tasks/EXlbuEGgRZK-IYKoOHmqWQ:990296121
2.2封装删除脚本
#!/usr/bin/env bashmyJarPath=./lib/xxx.jar# ---------------------------启动索引数据删除进程---------------------------# 索引类型
indexType="indexType"# 索引名称-多个索引名称使用逗号分隔
indexName="indexName"# IP和端口-使用冒号分隔
ipPort="localhost:9200"# 索引mapping中的时间字段
timeField="pubtime"# 每隔delayTime执行一次删除数据操作 - 延时执行-支持按天/小时/分钟(格式数字加d/h/m:1d/24h/60m/60s)
delayTime="2s"# 删除beforeDataTime以前的数据 - 行一次时删除多久以前的数据-支持按天/小时/分钟(格式数字加d/h/m:1d/24h/60m/60s)
beforeDataTime="2d"# 是否启动DEBUG模式
debug="true"#*****************************************************************
# 是否启用force merge(释放磁盘空间 - cpu/io消耗增加,缓存失效)
# 1、对于不再生成新分段的索引,建议打开此配置;2、如果索引在不断的产生新分段建议关闭此配置-通过修改集群段合并策略优化
#*****************************************************************
isForceMerge="false"nohup java -Xmx512m -cp ${myJarPath} casia.isi.delete.DeleteIndexData ${indexType} ${indexName} ${ipPort} ${timeField} ${delayTime} ${beforeDataTime} ${debug} ${isForceMerge} >>logs/delete.DeleteIndexData.log 2>&1 &
2.3封装接口实现
package casia.isi.elasticsearch.operation.delete.shell;
/*** ┏┓ ┏┓+ +* ┏┛┻━━━━━━━┛┻┓ + +* ┃ ┃* ┃ ━ ┃ ++ + + +* █████━█████ ┃+* ┃ ┃ +* ┃ ┻ ┃* ┃ ┃ + +* ┗━━┓ ┏━┛* ┃ ┃* ┃ ┃ + + + +* ┃ ┃ Code is far away from bug with the animal protecting* ┃ ┃ +* ┃ ┃* ┃ ┃ +* ┃ ┗━━━┓ + +* ┃ ┣┓* ┃ ┏┛* ┗┓┓┏━━━┳┓┏┛ + + + +* ┃┫┫ ┃┫┫* ┗┻┛ ┗┻┛+ + + +*/import casia.isi.elasticsearch.common.FieldOccurs;
import casia.isi.elasticsearch.common.RangeOccurs;
import casia.isi.elasticsearch.operation.delete.EsIndexDelete;
import casia.isi.elasticsearch.util.DateUtil;
import casia.isi.elasticsearch.util.StringUtil;
import com.alibaba.fastjson.JSONObject;/*** @Description: TODO(监控删除索引数据)* @date 2019/5/30 15:27*/
public final class DeleteDataByShell {private static EsIndexDelete esIndexDataDelete;private static String indexType;private static String indexName;private static String ipPort;private static String timeField;private static String delayTime;private static String beforeDataTime;private static boolean isForceMerge = false;// DELETE WORK TASK IDprivate static String lastTaskId;public static boolean debug = false;/*** @param indexType:索引类型* @param indexName:索引名称-多个索引名称使用逗号分隔* @param ipPort:IP和端口-使用冒号分隔* @param timeField:索引mapping中的时间字段* @param delayTime:延时执行-支持按天/小时/分钟(格式数字加d/h/m:1d/24h/60m/60s)* @param beforeDataTime:执行一次时删除多久以前的数据-支持按天/小时/分钟(格式数字加d/h/m:1d/24h/60m/60s)* @param isForceMerge:true启用force-merge* @return* @Description: TODO(为监控程序创建一个索引数据删除对象)*/public DeleteDataByShell(String indexType, String indexName, String ipPort, String timeField,String delayTime, String beforeDataTime, boolean isForceMerge) {this.esIndexDataDelete = new EsIndexDelete(ipPort, indexName, indexType);this.indexType = indexType;this.indexName = indexName;this.ipPort = ipPort;this.timeField = timeField;this.delayTime = delayTime;this.beforeDataTime = beforeDataTime;this.isForceMerge = isForceMerge;}/*** @return* @Description: TODO(启动监控删除)*/public void run() {boolean isExcute = check();while (isExcute) {try {// 执行删除executeDelete();// 延时执行sleep();} catch (Exception e) {System.out.println("Delete data exception,please check your parameters!");System.out.println("indexType:" + indexType);System.out.println("indexName:" + indexName);System.out.println("ipPort:" + ipPort);System.out.println("timeField:" + timeField);System.out.println("delayTime:" + delayTime);System.out.println("beforeDataTime:" + beforeDataTime);esIndexDataDelete.reset();}}}private boolean check() {if (this.timeField != null && this.delayTime != null && this.beforeDataTime != null) {return true;}return false;}private void sleep() throws InterruptedException {Thread.sleep(dhmToMill(delayTime));}private void outputResult() {System.out.println("Delay time:" + delayTime);System.out.println("Delete data from " + beforeDataTime + " ago.Current system time:" + DateUtil.millToTimeStr(System.currentTimeMillis()));if (debug) {System.out.println("Query url:" + esIndexDataDelete.getQueryUrl());System.out.println("Query json:" + esIndexDataDelete.getQueryString());System.out.println("Query result json:" + esIndexDataDelete.getQueryReslut());}lastTaskId = setTaskId(esIndexDataDelete.getQueryReslut());}/*** @param { "task": "EXlbuEGgRZK-IYKoOHmqWQ:xxxxxxx"* }* @return* @Description: TODO(设置taskID)*/private String setTaskId(String queryReslut) {JSONObject object = JSONObject.parseObject(queryReslut);return object.getString("task");}private void executeDelete() {// 输出上一个task的信息System.out.println("===========================================EXECUTE DELETE TASK===========================================");if (lastTaskId != null && !"".equals(lastTaskId)) {System.out.println(esIndexDataDelete.outputLastTaskInfo(lastTaskId));}String currentThreadTime = getCurrentThreadTime();esIndexDataDelete.addRangeTerms(timeField, currentThreadTime, FieldOccurs.MUST, RangeOccurs.LTE);esIndexDataDelete.setRefresh(true);esIndexDataDelete.setScrollSize(1000);esIndexDataDelete.conflictsProceed("proceed");esIndexDataDelete.setWaitForCompletion(false);esIndexDataDelete.execute();// 输出删除统计结果outputResult();// 释放磁盘空间(执行段合并操作)- CPU/IO消耗增加,缓存失效if (isForceMerge) {System.out.println(esIndexDataDelete.forceMerge());}esIndexDataDelete.reset();}private String getCurrentThreadTime() {long mill = System.currentTimeMillis() - dhmToMill(beforeDataTime);return DateUtil.millToTimeStr(mill);}private long dhmToMill(String dhmStr) {if (dhmStr != null && !"".equals(dhmStr)) {int number = Integer.valueOf(StringUtil.cutNumber(dhmStr));if (dhmStr.contains("d")) {return number * 86400000;} else if (dhmStr.contains("h")) {return number * 3600000;} else if (dhmStr.contains("m")) {return number * 60000;} else if (dhmStr.contains("s")) {return number * 1000;}}return 0;}/*** @param* @return* @Description: TODO(Delete thread main entrance)*/public static void main(String[] args) {String indexType = args[0];String indexName = args[1];String ipPort = args[2];String timeField = args[3];String delayTime = args[4];String beforeDataTime = args[5];DeleteDataByShell.debug = Boolean.valueOf(args[6]);String isForceMerge = args[7];new DeleteDataByShell(indexType, indexName, ipPort, timeField, delayTime, beforeDataTime, Boolean.valueOf(isForceMerge)).run();}}
三、Lucene分段处理的优化
经过以上操作索引中的数据可以被正确的标记为删除,并且及时刷新查询显示。但是标记刷新之后,索引分段数据并没有将磁盘空间及时释放,还依赖于lucene分段合并的处理。
使用forcemerge可以及时释放磁盘空间,但是会带来cpu/io消耗增加,缓存失效等问题。这种问题对查询性能带来影响。但是可以按照具体的使用场景来采取措施:1、对于不再生成新分段的索引(不再有数据被索引和更新),可以考虑人工启动分段merge操作;2、如果索引在不断的产生新分段(数据被索引),通过修改集群段合并策略优化。在我们的需求中则必须采用第二种方式,线上系统人工_forcemerge带来的性能问题是不可接受的。
3.1、refersh
es默认每秒进行自动刷新,这带来的好处是新索引的数据可以及时对搜索可见。随之带来的问题是影响性能:某些缓存将会失效,拖慢搜索请求,而且重新打开索引的过程本身也需要一些处理能力,拖慢了索引的建立。
// 索引级setting
"index.refresh_interval": "5s",
3.2、flush
flush操作是将内存数据冲刷到磁盘。内存缓冲区已满、事务日志已满、时间间隔已到,都会触发flush操作。具体策略请查阅相关文档。
// 集群配置elasticsearch.yml-内存缓冲区大小在elasticsearch.yml配置文件定义-可设置为JVM堆内存的百分比10%
"indices.memory.index_buffer_size":"3gb"// 索引级setting-触动冲刷得规模-可设置为JVM堆内存得百分比10%(默认512mb)
"index.translog.flush_threshold_size": "3gb"// 索引级setting-冲刷之间的时间间隔(默认是30m)
"index.translog.flush_threshold_period": "30m"
3.3、合并策略
使用lucene默认的分层合并策略。关于分层合并策略的介绍请移步es官网。
// 索引级setting-每层分段数(segments_per_tier设为与max_merge_at_once相等可减少合并次数)
"index.merge.policy.segments_per_tier":5// 索引级setting-每层合并的最大分段数(默认是10)
"index.merge.policy.max_merge_at_once": 5// 索引级setting-最大分段规模(默认是5g)
"index.merge.policy.max_merged_segment": "1gb"// 索引级setting-用于合并的最大线程数(设置为1可以让磁盘更好的运转)
// 要注意的是如果你是用HDD而非SSD的磁盘的话,最好是用单线程为妙。
"index.merge.scheduler.max_thread_count": 1
3.4、存储限流
存储限流和存储的优化可以有效提升I/O的吞吐量。
存储限流的原因:过度的合并会拖慢集群。由于I/O的等待,会导致CPU负载也会很高。
// 集群配置elasticsearch.yml存储限流设置默认20mb(SSD-增加到100~200MB)
"indices.store.throttle.max_bytes_per_sec":"20mb"// 集群配置elasticsearch.yml使存储限流的设置应用到所有的es操作
"indices.store.throttle.type":"all"
3.5、存储
存储使用默认存储,主要考虑调整存储限流的设置。
存储类型:1、mmapfs-通常用于大型文件。eg.词条字典;2、niofs-其它类型文件。eg.存储字段。详细优化手段请移步es官方参考文档。
3.6、使用postman设置索引级配置
// URL
PUT http://localhost:9210/indexName/_settings// PARAMETERS
{"index.refresh_interval": "5s","index.translog": {"flush_threshold_size": "3gb",},"index.merge": {"policy": {"segments_per_tier": 5,"max_merge_at_once": 5,"max_merged_segment": "1gb"},"scheduler.max_thread_count": 1}
}// RESPONSBODY
{"acknowledged": true
}// 使用GET接口查看setting
GET http://localhost:9210/indexName/_settings
{"indexName": {"settings": {"index": {"refresh_interval": "5s","number_of_shards": "5","translog": {"flush_threshold_size": "3gb"},"provided_name": "indexName","merge": {"scheduler": {"max_thread_count": "1"},"policy": {"segments_per_tier": "5","max_merge_at_once": "5","max_merged_segment": "1gb"}},"creation_date": "1559195227068","number_of_replicas": "0","uuid": "aDekoukTQL2HeB_aQy_HFA","version": {"created": "5060399"}}}}
}
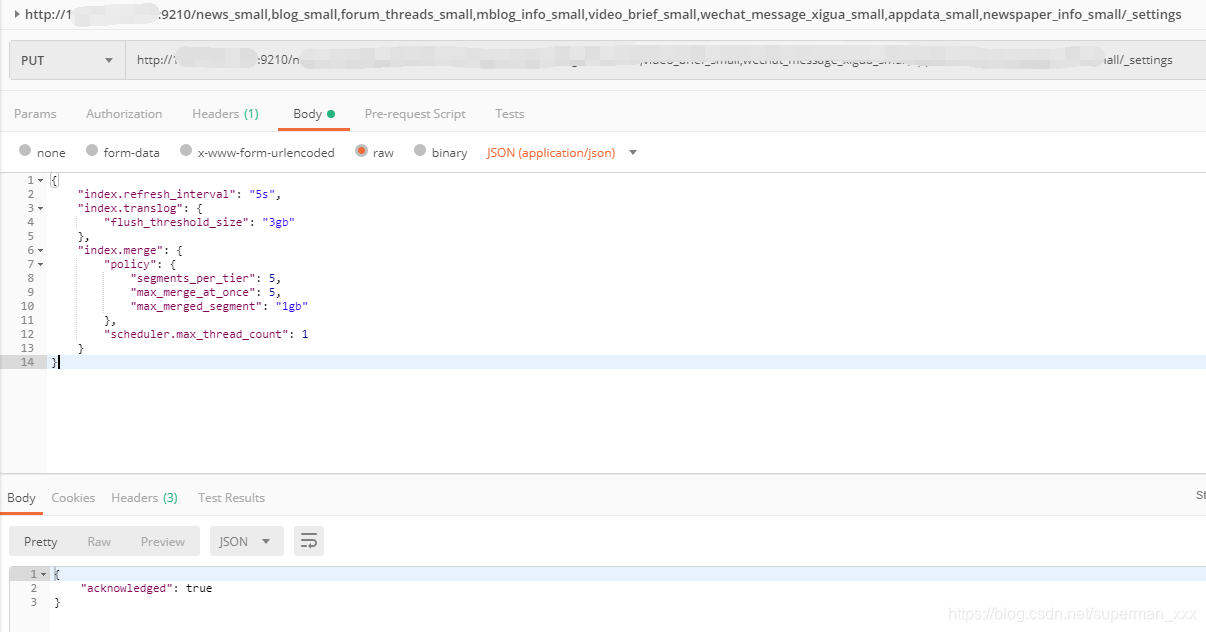
postman设置index的setting:
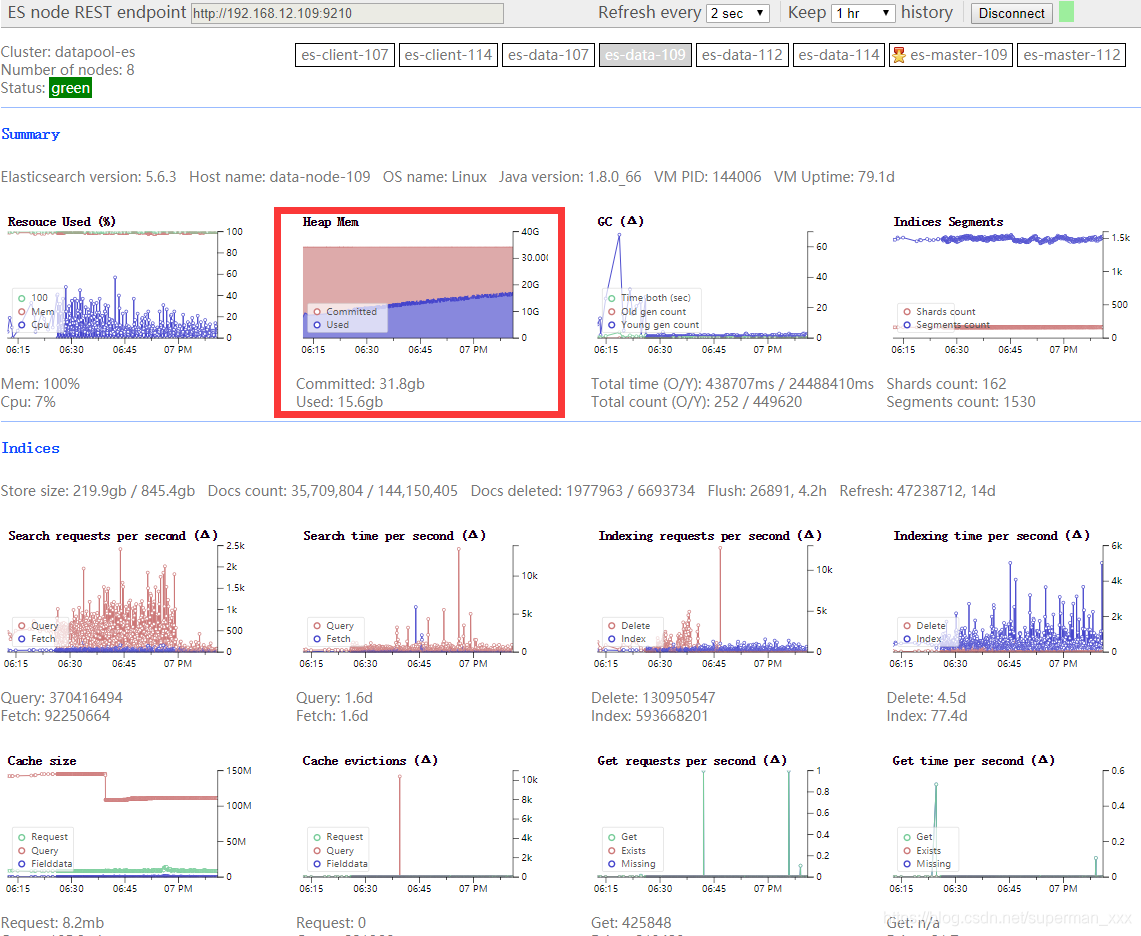
Lucene分段处理优化之后,很明显可以看到Heap Memory消耗下降了将近一般左右(之前的图有一个驼峰式的下降效果忘记截图了:)gg):
四、删除接口运行效率统计分析
使用_tasks接口,计算平均处理速率。
http://localhost:9210/_tasks/EXlbuEGgRZK-IYKoOHmqWQ:98453352X
{"completed": true,"task": {"node": "EXlbuEGgRZK-IYKoOHmqWQ","id": 984533525,"type": "transport","action": "indices:data/write/delete/byquery","status": {"total": 10399385,"updated": 0,"created": 0,"deleted": 4784168,"batches": 10400,"version_conflicts": 5615217,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0},"description": "delete-by-query [indexName]","start_time_in_millis": 1559727929590,"running_time_in_nanos": 3237112234217,"cancellable": true},"response": {"took": 3237112,"timed_out": false,"total": 10399385,"updated": 0,"created": 0,"deleted": 4784168,"batches": 10400,"version_conflicts": 5615217,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0,"failures": []}
}
类似上述结果,可以根据task的运行情况计算处理效率。使用running_time_in_nanos和deleted字段的数据计算平均处理速率。服务器配置:1、Intel® Xeon® CPU E5-2620 v4 @ 2.10GHz-32核,2、磁盘-HDD1.6T,3、内存-128G。
| 数据量/总耗时 | 速率 |
|---|---|
| 100万/792s/13分钟 | 1262t/s |
| 219万/1768s/29分钟 | 1238t/s |
| 480万/3237s/53分钟 | 1482t/s |
在如上的task统计结果中,可以看到有很多数据是标记为version_conflicts。在轮询的删除过程中需要被删除的数据最终都会被删除(每30分钟运行一次删除进程)。如果对于数据删除时效性要求比较高的话,需要解决这个问题。并且继续优化删除策略。
// 没有数据版本冲突的删除任务,返回的信息是这样的(version_conflicts=0)
{"completed": true,"task": {"node": "EXlbuEGgRZK-IYKoOHmqWQ","id": 990296121,"type": "transport","action": "indices:data/write/delete/byquery","status": {"total": 170733,"updated": 0,"created": 0,"deleted": 170733,"batches": 171,"version_conflicts": 0,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0},"description": "delete-by-query [news_small, blog_small, forum_threads_small, mblog_info_small, video_brief_small, wechat_message_xigua_small, appdata_small, newspaper_info_small][monitor_caiji_small]","start_time_in_millis": 1559731529771,"running_time_in_nanos": 71981947551,"cancellable": true},"response": {"took": 71981,"timed_out": false,"total": 170733,"updated": 0,"created": 0,"deleted": 170733,"batches": 171,"version_conflicts": 0,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0,"failures": []}
}
五、继续优化
在调用_delete_by_query接口时,设置参数refresh=wait_for。
refresh参数-true表示:立即刷新主分片和副分片;false:表示不刷新,不设置此条件默认不刷新;wait_for:使用集群自动刷新机制(默认1s,在索引级自定义5s或者其它值,根据业务决定。本次测试使用的5s)。
经过_tasks接口统计,发现优化这个参数之后,每秒的处理能力提升了3~4倍,1262t/s->4115t/s。
| 数据量/总耗时 | 速率 |
|---|---|
| 100万/243s/4分钟 | 4115t/s |
| 122万/297s/5分钟 | 4107t/s |
{"completed": true,"task": {"node": "EXlbuEGgRZK-IYKoOHmqWQ","id": 1111458358,"type": "transport","action": "indices:data/write/delete/byquery","status": {"total": 1215333,"updated": 0,"created": 0,"deleted": 1215333,"batches": 1216,"version_conflicts": 0,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0},"description": "delete-by-query [indexName]","start_time_in_millis": 1559802968421,"running_time_in_nanos": 297299330904,"cancellable": true},"response": {"took": 297299,"timed_out": false,"total": 1215333,"updated": 0,"created": 0,"deleted": 1215333,"batches": 1216,"version_conflicts": 0,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0,"failures": []}
}
这篇关于Elasticsearch索引数据大批量删除接口优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






