本文主要是介绍python 大批量文本分词 以及词频统计 (高效处理案例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境:python3.6
库:jieba,xlwt,xlwings,collections
前两天有个需求要对一张表里的中文语句进行分词,并统计每个词语出现的次数。
表格1231.xlsx大致内容如下:

由于表格内容过大,约有100W条数据,普通读取表格的方式效率非常慢,所以这次用的方法是xlwings,
xlwings是目前看来操作excel最快速、做的比较完善的一个库,优化很好,调用方式非常灵活。对读取大表格的有很高的效率
以下是完整的代码:
import jieba
import xlwt, xlrd
import xlwings as xw
from collections import Counter# 定义一个空列表
all_word_list = []# 分词
def trans_CN(text):# 接收分词的字符串word_list = jieba.cut(text)# 分词后在单独个体之间加上空格result = " ".join(word_list)# 转换成listresult = result.split(" ")return result# 判断词是否为中文
def is_Chinese(word):for ch in word:if '\u4e00' <= ch <= '\u9fff':return Truereturn Falsestart_row = 2 # 处理Excel文件开始行
end_row = 1000000 # 处理Excel结束行# 指定不显示地打开Excel,读取Excel文件
app = xw.App(visible=False, add_book=False)
wb = app.books.open(r"./1231.xlsx") # 打开Excel文件
sheet = wb.sheets[9] # 选择第0个表单# 读取Excel表单前1000000行的数据,读取Excel表单前1000000行的数据
for row in range(start_row, end_row):print(row)row_str = str(row)# 循环中引用Excel的sheet和range的对象,读取C列的每一行的值content_text = sheet.range('C' + row_str).value# print(content_text)if not content_text:continueif not isinstance(content_text, str):continue# 长度小于4的语句 过滤if len(content_text) > 3:word_list = trans_CN(content_text)print("分词后", word_list)# 判断列表元素是否为中文,将非中文词移除for s in word_list:if not is_Chinese(s):word_list.remove(s)all_word_list += word_list# 统计列表中元素出现的频率
counter = Counter(all_word_list)
print("统计频率完成")# 将列表中的元素按照频率大小排序
result_list = sorted(counter.items(), key=lambda x: x[1], reverse=True)# 将结果写入表格
print("开始写入表格")
myWorkbook = xlwt.Workbook()
mySheet = myWorkbook.add_sheet('Sheet1', cell_overwrite_ok=True)
rows = 0
for i in result_list:mySheet.write(rows, 0, i[0])mySheet.write(rows, 1, i[1])rows += 1
myWorkbook.save('result.xls')# 保存并关闭Excel文件
wb.save()
wb.close()
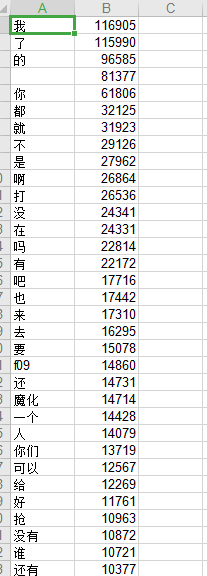
运行完成后,保存为result.xls,查看结果:
A列为分词,B列为该词出现的次数
这篇关于python 大批量文本分词 以及词频统计 (高效处理案例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





