回表专题

贝壳面试:什么是回表?什么是索引下推?
尼恩说在前面 在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: 1.谈谈你对MySQL 索引下推 的认识? 2.在MySQL中,索引下推 是如何实现的?请简述其工作原理。 3、说说什么是 回表,什么是 索引下推 ? 最近有小伙伴在面试 贝壳、soul,又遇到了相关的

openGauss 之索引回表
一. 前言 在openGauss中如果表有索引信息,查询的谓词条件中又包含索引列,openGauss支持通过索引信息快速拿到需要访问元组的位置信息,然后直接到该位置上取出元组数据,称之为回表查询。如下所示,利用索引索引列id=55快速找到t111上对应元组的位置信息,然后通过位置信息拿到id为55的元组中所有列的数据。 本文通过走读openGauss的代码了解ope

MySQL中的回表查询、索引覆盖、索引下推
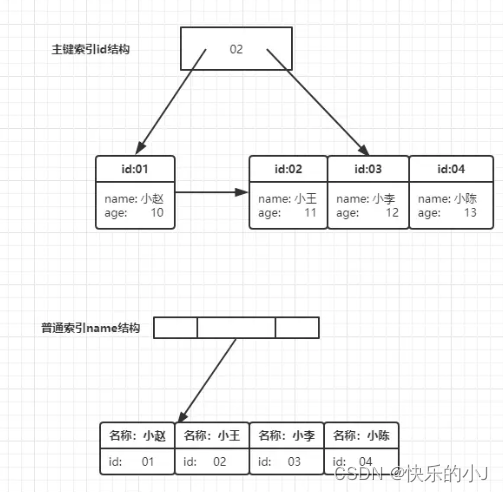
本文重点介绍索引中的常见概念:回表查询、索引覆盖、索引下推 一、回表查询 我们首先理解:在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种: 分类含义特点聚集索引 (Clustered Index)将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据必须有,而且只有一个二级索引 (Secondary Index)将数据与索引分开存储,索引结构的叶子节点关联的是对应的主
sql优化之利用聚簇索引减少回表次数:limit 100000,10
1. 问题描述 产品:我要对订单列表页做一个分页功能,每页10条数据,商家可以根据金额过滤订单 技术:好的,我写一个sql实现分页,x表示偏移页数,自测limit 10,10耗时200ms: SELECT * FROM `order` WHERE `amount` > 0 limit x,10; 功能演示时,产品点击第1000万页,页面因为接口超时空白,查看sql耗时10000ms 技术
回表的原理竟然这么简单
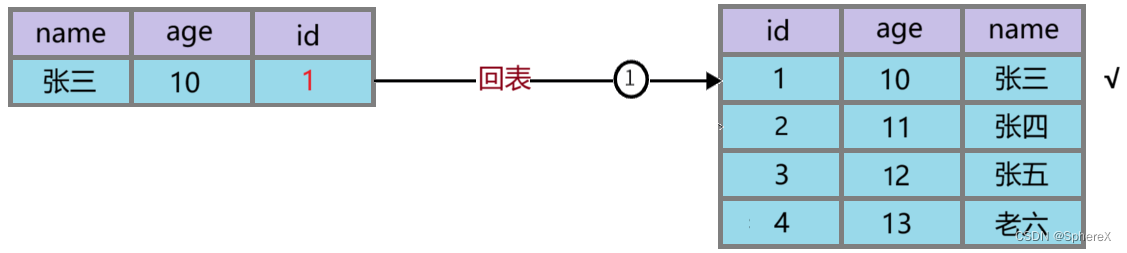
“回表” 是指在使用辅助索引(非聚簇索引)作为条件进行查询时,由于辅助索引中只存储了索引字段的值和对应的主键(聚簇索引)键值,因此需要根据主键(聚簇索引)中的键值去查找实际的数据行,这个过程被称为回表。 举个例子:select * from user where age = 20; 1)根据辅助索引(age)找到 age=20 的 主键键值: 2)再根据主键去查找整行的数据:
数据库索引回表困难?揭秘PolarDB存储引擎优化技术
引言 数据库系统为了高效地存储、检索和维护数据,采用了多种不同的数据组织结构。不同的组织结构有其特定的用途和优化点,比如提高查询速度、优化写入性能、减少存储空间等。常见的数据库记录组织结构有: B-Tree B-Tree是一种平衡的多路搜索树,特别适合存储在外部存储器(如硬盘)中。它通过减少访问磁盘的次数来优化读写操作。B-Tree广泛应用于数据库管理系统和文件系统中,用于存储索引和数据

回表 table access by index rowid
111 回表:在数据中,当查询数据的时候,在索引中查找索引后,获得该行的rowid,根据rowid再查询表中数据,就是回表。 --创建一个表, 索引只建立在object_id上 SQL> create table ml_1 as 2 select * from dba_objects 3 ; Table created SQL> create index id

索引使用规则4——覆盖索引回表查询
覆盖索引:查询使用了索引,并且需要返回的列,在索引里面都可以找到,减少select*的使用 1、using index condition Extra 为using index condition 表明查找使用了索引,但是需要回表查询(也就是先二级索引,拿到id,在返回表里面,进行聚集索引,得到一行的数据,耗时耗内存) 举个例子 explain select * from tb_user

走索引+回表还是走主键扫描?
走索引+回表还是走主键扫描? 一个非索引覆盖类型的查询,走主键还是走索引回表?MySQL可能会在这个问题上选择错误。 比如说一张表t1,表结构如下 mysql> show create table t1\G*************************** 1. row ***************************Table: t1Create Table: CREATE

MySQL数据库-索引概念及其数据结构、覆盖索引与回表查询关联、超大分页解决思路
索引是帮助mysql高效获取数据的数据结构,主要用来提高检索的效率,降低数据库的IO成本(输入输出成本(Input-Output Cost)),同时通过索引对数据进行排序也能降低数据排序的成本,降低了CPU的消耗。 Mysql的默认存储引擎InnoDB,InnoDB采用的B+树的数据结构来存储索引。B+树所有数据都出现在叶子节点,而相比较而言B树非叶子节点和叶子节点都存放数据,因此B+树内部节点
聚簇索引、非聚簇索引、回表、索引下推、覆盖索引
聚簇索引(主键索引) 非叶子节点上存储的是索引值,叶子节点上存储的是整行记录。 非聚簇索引(非主键索引、二级索引) 非叶子节点上存储的都是索引值,叶子节点上存储的是主键的值。非聚簇索引需要回表,IO消耗。 回表 非聚簇索引先执行一次主键查询,再通过适配的主键的值之后,再进行一次二级索引,这个过程就是回表。 覆盖索引 一次索引就可以得到数据,无需回表。覆盖索引发生在联合索引,where

聚簇索引、回表与覆盖索引
聚簇索引一般指的是主键索引(如果存在主键索引的话)。 作为一个正常开发,建表时主键肯定是必须的。 而即使如果表中没有定义主键,InnoDB 会隐式选择一个唯一的非空索引代替。 所以我们就直接含糊点说: 聚簇索引就是主键索引!其余的都是非聚簇索引。 那到底什么是聚簇索引,什么是非聚簇索引? 聚簇就是扎一堆儿。 聚簇索引就是将数据存储与索引放到了一块,找到索引也就找到了数据。 在

快速理解 Mysql 回表 索引覆盖 索引下推
快速理解 Mysql 回表 索引覆盖 索引下推 回表操作索引覆盖索引下推 回表操作 Mysql 每页大小为16K(B+树结构,所以16K足以),关于主键索引和辅助索引的结构这里简单说一下。 InnoDB 主键(聚簇索引):仅在叶子节点存储数据,且是整行数据。 InnoDB 普通索引(辅助索引):仅在叶子节点存储对应的主键。 比如: 有一张account表,其中id为主
MySQL - 聚簇索引和非聚簇索引,回表查询,索引覆盖,索引下推,最左匹配原则
聚簇索引和非聚簇索引 聚簇索引和非聚簇索引是 InnoDB 里面的叫法 一张表它一定有聚簇索引,一张表只有一个聚簇索引在物理上也是连续存储的 它产生的过程如下: 表中有无有主键索引,如果有,则使用主键索引作为聚簇索引;如果没有主键索引,则看表中有无唯一索引,那么使用第一个唯一索引;如果以上两个条件都不满足,InnoDB 则会生成隐藏聚簇索引。 聚簇索引 聚簇索引一般是主键索引, 例
如何避免回表查询?什么是索引覆盖? | 1分钟MySQL优化系列
《迅猛定位低效SQL?》留了一个尾巴: select id,name where name='shenjian' select id,name,sex where name='shenjian' 多查询了一个属性,为何检索过程完全不同? 什么是回表查询? 什么是索引覆盖? 如何实现索引覆盖? 哪些场景,可以利用索引覆盖来优化SQL? 这些,这是今天要分享的内容。 画外音:本文试验基于My
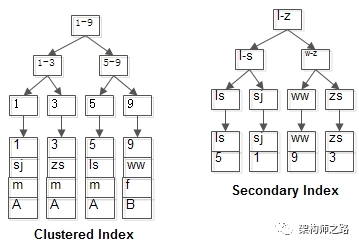
mysql覆盖索引与回表
select id,name where name='shenjian' select id,name,sex* where name='shenjian'* 多查询了一个属性,为何检索过程完全不同? 什么是回表查询? 什么是索引覆盖? 如何实现索引覆盖? 哪些场景,可以利用索引覆盖来优化SQL? 这些,这是今天要分享的内容。 画外音:本文试验基于MySQL5.6-InnoDB。
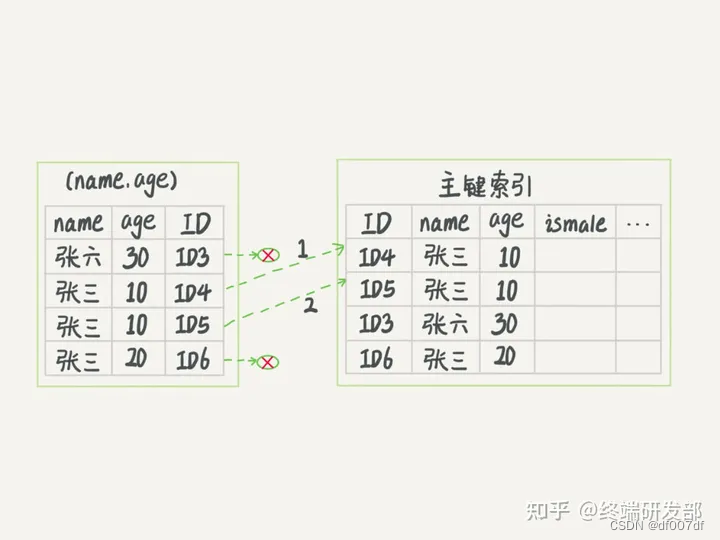
在Mysql中,什么是回表,什么是覆盖索引,索引下推?
一、什么是回表查询? 通俗的讲就是,如果索引的列在 select 所需获得的列中(因为在 mysql 中索引是根据索引列的值进行排序的,所以索引节点中存在该列中的部分值)或者根据一次索引查询就能获得记录就不需要回表,如果 select 所需获得列中有大量的非索引列,索引就需要到表中找到相应的列的信息,这就叫回表。 InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一
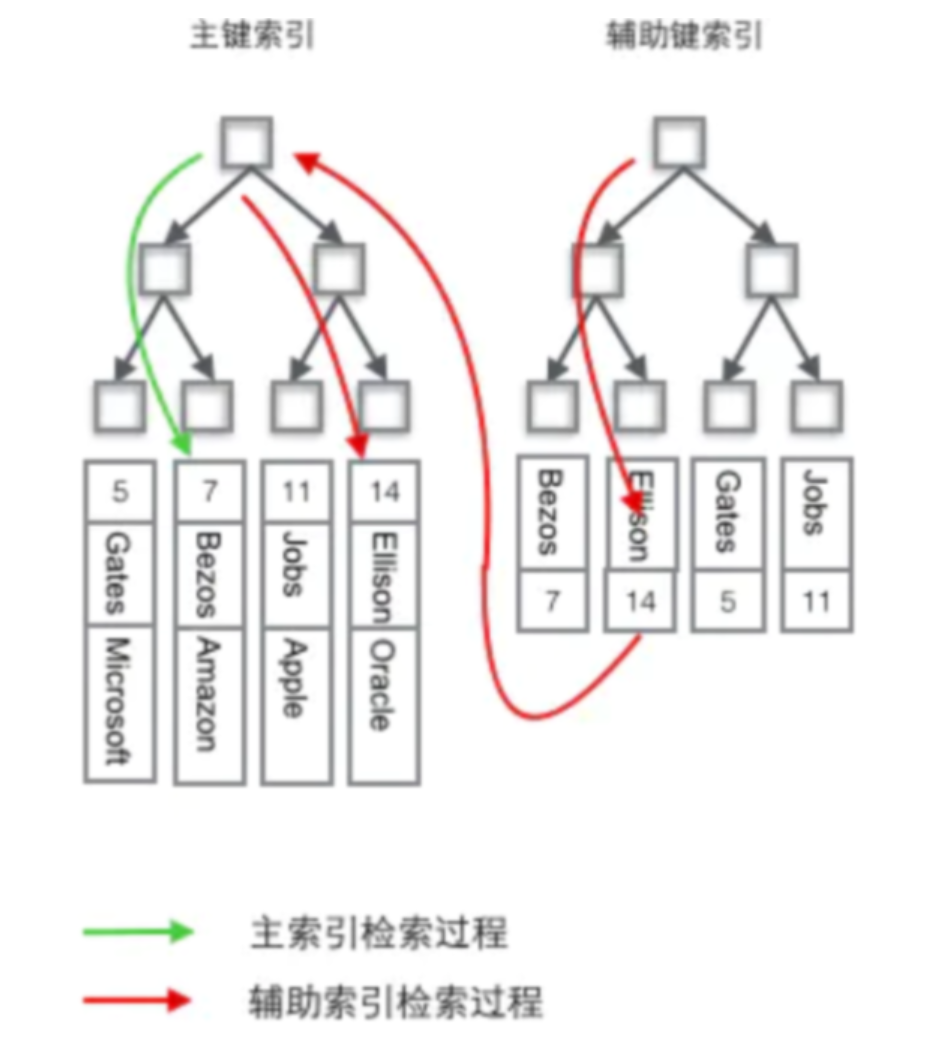
聚簇索引和非聚簇索引的区别;什么是回表
聚簇索引和非聚簇索引的区别 什么是聚簇索引?(重点) 聚簇索引就是将数据(一行一行的数据)跟索引结构放到一块,InnoDB存储引擎使用的就是聚簇索引; 注意点: 1、InnoDB使用的是聚簇索引(聚簇索引默认使用主键作为其索引),将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之
mysql索引分为哪几类,聚簇索引和非聚簇索引的区别,MySQL索引失效的情况有哪几种情况,MySQL索引优化的手段,MySQL回表
文章目录 索引分为哪几类?聚簇索引和非聚簇索引的区别什么是[聚簇索引](https://so.csdn.net/so/search?q=聚簇索引&spm=1001.2101.3001.7020)?(重点)非聚簇索引 聚簇索引和非聚簇索引的区别主要有以下几个:什么叫回表?(重点) MySQL索引失效的几种情况(重点)MySQL索引优化手段有哪些?什么叫回表?(重点)什么叫索引覆盖?(重点)

MySQL6:索引使用原则,联合索引,联合主键/复合主键,覆盖索引、什么是回表?索引条件下推,索引的创建与使用,索引的创建与使用,索引失效
MySQL6:索引使用原则,联合索引,联合主键/复合主键,覆盖索引、什么是回表?索引条件下推,索引的创建与使用,索引的创建与使用,索引失效 索引使用原则列的离散(sdn)度 联合索引创建联合索引联合索引最左匹配建立联合索引之后,联合索引的最左字段还要再建普通索引吗? 联合索引使用场景什么时候能用到联合索引 联合主键/复合主键覆盖索引什么是回表?什么是覆盖索引?如何判断是覆盖索引 索引条件下推

MySQL调优思路(回表、LRU算法、索引下推、预读取失效、缓冲区污染、刷脏、sql执行流程、redo、undo、bin log)
回表、避免回表、索引下推、刷脏、LRU算法、索引覆盖、预读取失效、缓冲区污染、rodo Log、undo Log、bin Log、sql执行流程 文章目录 前言一、一条Sql在MySQL的执行流程?1、总体流程:1.1、查询操作流程(query):1.1.1、具体介绍每个节点 1.2、更新操作流程(update):1.3、相关概念1.3.1、redo Log & undo Log & bi