本文主要是介绍数据库索引回表困难?揭秘PolarDB存储引擎优化技术,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
数据库系统为了高效地存储、检索和维护数据,采用了多种不同的数据组织结构。不同的组织结构有其特定的用途和优化点,比如提高查询速度、优化写入性能、减少存储空间等。常见的数据库记录组织结构有:
- B-Tree
B-Tree是一种平衡的多路搜索树,特别适合存储在外部存储器(如硬盘)中。它通过减少访问磁盘的次数来优化读写操作。B-Tree广泛应用于数据库管理系统和文件系统中,用于存储索引和数据。典型的代表有MySQL。
- LSM Tree
LSM Tree是一种适合写入密集型场景的数据结构,通常用于NoSQL数据库中。它将数据更新操作写入内存中的结构,然后定期合并到磁盘上。这种设计充分利用了顺序写能力,大幅度优化了写入性能。使用LSM Tree的佼佼者有LevelDB、HBase等。
- Heap Table
Heap Table是一种简单的数据记录组织方式。Heap Table的记录以任意顺序插入到表中,数据的写入性能几乎能达到磁盘写入的上限。但是由于其无序性,数据查询效率不如索引表。为了改进查询性能,Heap Table通常还会搭配如B-Tree这样的索引结构使用。典型的数据库有PostgreSQL。
- Skip List跳表
跳表是一种概率性结构,它通过在多层链表上添加“快速通道”的方式来实现快速搜索,实现了平均复杂度为O(log n)的插入、删除和查找操作。同样用于某些版本的 NoSQL数据库中,被用作内存索引的一种有效结构。
每种数据组织结构都有其优势和应用场景。关系型数据库OLTP业务对并发读写、MVCC、空间利用率、高效查找和范围查询、优化磁盘I/O、平衡性等等都要有均衡的诉求,目前PolarDB分布式版采用了B-Tree的索引组织结构。
B-Tree索引中最常用到的是聚簇索引(即主键索引)。通过聚簇索引,查询能够直接找到对应数据行的所有数据。值得注意的是,阿里云瑶池旗下的云原生数据库PolarDB分布式版(PolarDB for Xscale,简称PolarDB-X)存储引擎在聚簇索引上还放入数据行的版本信息。当查询进行时,PolarDB分布式版需要通过比对查询的视图信息以及聚簇索引上行记录的版本信息,来确定查询需要查找的版本记录。当聚簇索引上的当前版本并不满足要求时,需要通过Undo日志把对应记录的历史版本构建出来。
聚簇索引对于主键查询非常有效,然而如果查询的条件并不由主键来决定时,查询需要回退到全量扫描。为了解决这个问题,非聚簇索引被引入。非聚簇索引与聚簇索引很相似,但非聚簇索引有一个重要的区别:
非聚簇索引没有版本信息,即通过非聚簇索引只能查找最新版本。当查找非聚簇索引时,需要首先确认该版本是否为本查询所需要的版本。但由于非聚簇索引上没有版本信息,所以进一步需要通过主键信息查找聚簇索引,以获得版本信息。
通过非聚簇索引查找对应的聚簇索引记录,这个过程通常被称为回表。
下面展示了一个典型的非聚簇索引的使用案例:
年级成绩表(聚簇索引):
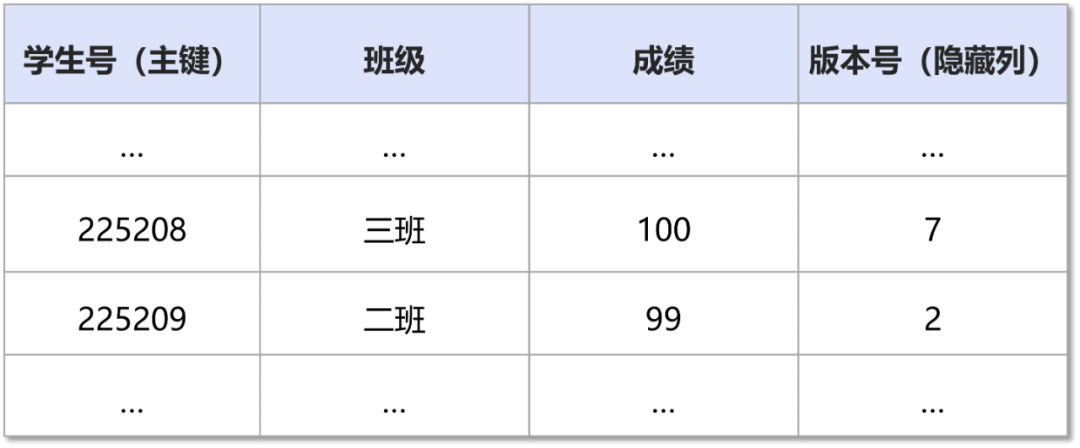
班级-学生号索引(非聚簇索引):
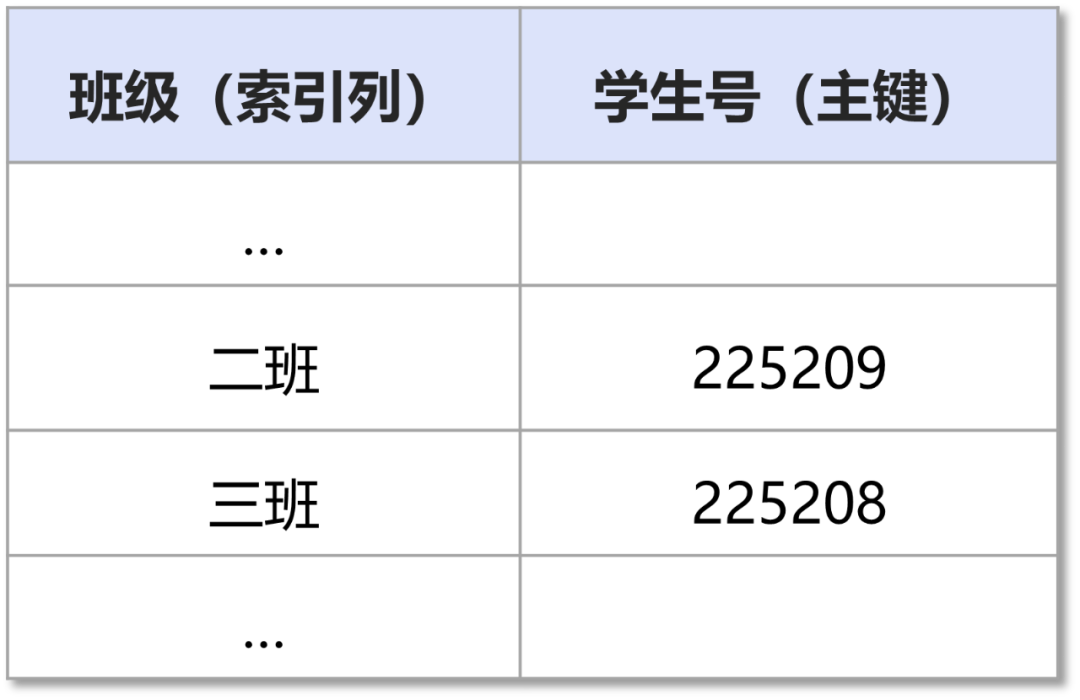
当查询二班的所有学生号时,虽然只需要查找非聚簇索引即可,但是由于不能确定是否可见,还需要回查聚簇索引上对应的主键记录,确定其真实的版本号信息。
非聚簇索引回表代价
一条SQL语句回表代价取决于回表的频次以及回表本身的开销。
回表本身开销在于B-Tree查找,即一次非聚簇索引记录的查询,需要一次聚簇索引的查询。
回表的频次则取决于SQL语句的类型。特别是对于Range查询:
SELECT sec FROM t1 WHERE sec BETWEEN ? AND ?当PolarDB分布式版DN存储引擎执行一条SQL时,需要经历开表、B-Tree查找等等阶段,Range查询会显著地增大回表开销的占比,如果每一行记录都需要回表,则会造成严重的性能问题。
在我们的测试数据中发现,全回表相比于不回表,性能有10倍以上的差距。
索引回表操作还会对Buffer Pool造成冲击,特别是当Buffer Pool资源紧张时,大量的回表操作会占用了Buffer Pool的空闲页,导致数据库雪崩。
考虑极端情况,如果一张表上几乎没有修改,则因为要判断可见性而带来的回表操作几乎是没有意义的。
通过上面分析可以发现,因为判断可见性而带来的回表,代价是昂贵,且大多数情况下是无必要的。目前单机数据库如MySQL通过引入最小活跃事务号,辅助非聚簇索引的可见性判断,大幅度降低了因为可见性判断而带来的回表问题。
但是,对于PolarDB-X这样的分布式数据库,情况会变得更复杂,这个方案将不再适用。为了解决这个问题,PolarDB分布式版DN存储引擎提出了CSM(Commit Snapshot Manager)方案。
下面会介绍单机数据库MySQL的解决方案,并引申到PolarDB分布式版针对分布式场景设计的CSM方案。
单机MySQL非聚簇索引回表优化
为了解决这个问题,MySQL通过引入最小活跃事务号,辅助非聚簇索引的可见性判断,大幅度避免了回表查询的次数,大大降低了查找代价。
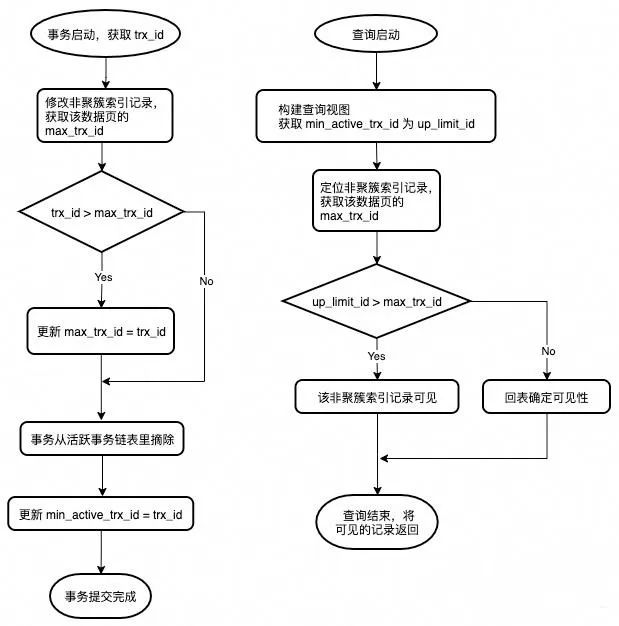
事务ID号唯一标识了一个事务。MySQL会维护一个事务ID号生成器。该事务ID号生成器会生成全局唯一单调递增的事务ID号。当事务启动时,都需要从该事务ID号生成器里获取一个事务ID号作为自己的事务标识。
同时,MySQL还维护了一个全局的状态变量:min_active_trx_id。
min_active_trx_id表示所有活跃事务里最小的事务ID号。这意味着,所有事务ID号比min_active_trx_id小的事务都已提交。
除此之外,还会在非聚簇索引的每一个数据页上维护一个特殊的持久化信息:max_trx_id。max_trx_id表示本数据页内所有修改过该数据页的事务里最大的事务ID号。
当查询发起时,会构建一个视图,该视图需要获取当前系统的min_active_trx_id作为视图的up_limit_id。当查找非聚簇索引时,可以通过up_limit_id与数据页的 max_trx_id做比较来确定可见性。相关流程图如下所示:
分布式数据库的索引回表困境
对于分布式数据库,回表问题会被进一步放大。PolarDB分布式版,分布式查询采用基于全局时间戳TSO的MVCC多版本查询。即分布式查询视图的版本号GCN是由外部的全局授时服务生成的TSO来指定,而并非从数据库管理系统里的本地事务系统最新状态获取。
由于网络、系统调度等原因,当分布式查询真正发起时,节点内的事务系统状态可能已经发生过多次变化,事务系统状态最新的min_active_trx_id信息已经不再适用于本次分布式查询GCN视图的构建。
以下面例子为例:
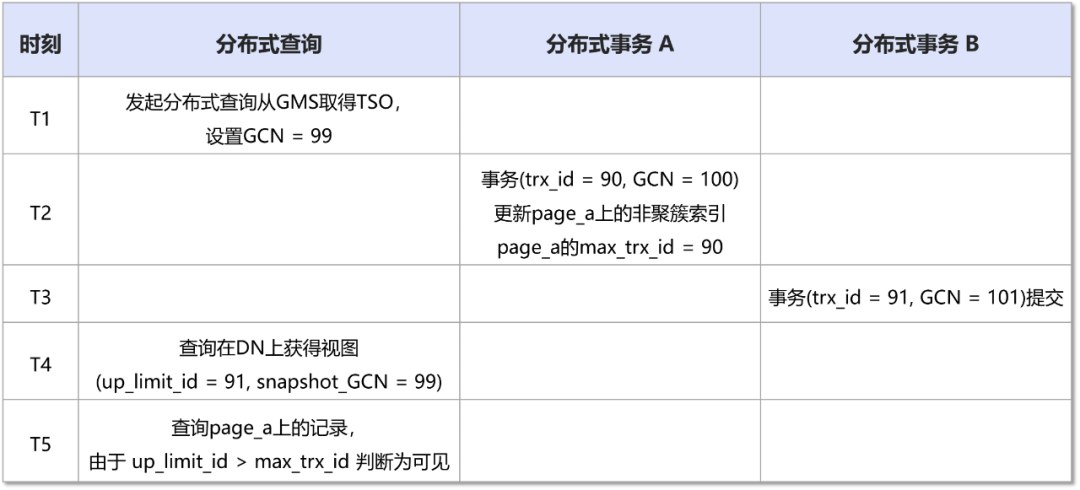
对于上述发起的分布式查询,实际上由于(snapshot_GCN = 99)<(rec_GCN = 100),所以该记录对于该视图应该是不可见的。
之所以出现上述问题,其核心原因在于,所有的分布式事务的提交顺序并非由本地生成,而是由外部全局协调器统一生成。即多个分布式事务的分支事务在各个节点上的实际提交顺序可能是不同的。
这导致分布式查询的可见性要远比本地单机查询复杂,目前业界内基于单机查询设计的非聚簇索引优化理论,在分布式查询上不再有效。
如何在分布式数据库管理系统里,降低非聚簇索引因为查找版本信息而带来的额外回表代价,是分布式数据库管理系统设计里最关键的问题之一。
Commit Snapshot Manager方案
单机数据库管理系统上非聚簇索引的优化方案,在分布式场景下不再适用的原因是:分布式查询需要的是“彼时彼刻”的min_active_trx_id,但数据库现有的设计只能提供“此时此刻”的min_active_trx_id。
上述说的“时刻”并不是物理时间上的时刻,而是GCN这样的逻辑“时刻”。即:
对于snapshot_GCN = 99的分布式查询,它需要的是DN节点处于GCN = 99时事务系统对应的min_active_trx_id。
一个直观的设想是,如果事务系统维护了过去所有时间点的事务系统状态信息,并且提供能力回查当时时刻的min_active_trx_id状态,则可以解决分布式场景下非聚簇索引因为无法判断可见性而需要回表的问题。
当然这个代价是巨大的,以10万TPS为例,每分钟需要产生至少90 MB的数据。
PolarDB分布式版存储引擎采用了CSM方案来均衡了资源开销与可用性,以极低的代价维护过去时间点的近似min_active_trx_id状态,彻底解决了分布式场景下非聚簇索引频繁回表的问题。CSM是一个环形队列,每间隔一定时间(如 1 秒)则会产生一个Commit Snapshot。更具体地说:
- CSM收集开始;
- 获取系统当下的min_active_trx_id作为up_limit_id;
- 获取系统当下的sys_GCN, sys_SCN为csm_GCN以及csm_SCN;
- 将 (up_limit_id, csm_GCN, csm_SCN) 作为一个Commit Snapshot,插入到CSM。
其中,sys_GCN是PolarDB分布式版存储引擎维护的本节点上的最大GCN号。其更新时机为:
- 分布式查询由外部协调者指定了snapshot_GCN作为分布式查询视图的GCN,sys_GCN = max { sys_GCN, snapshot_GCN }。
- 分布式事务提交由外部协调者指定了commit_GCN作为分布式事务的提交号 GCN,sys_GCN = max { sys_GCN, commit_GCN }。
显然,sys_GCN,min_active_trx_id均满足单调递增永不回退。这意味着:在CSM 环形队列上,csm_GCN、up_limit_id总是有序的。
当分布式查询发起时,根据视图的snapshot_GCN,从CSM尾部开始查找,直到找到 csm_GCN刚好不大于snapshot_GCN的CSM元素,取该元素的up_limit_id作为视图的up_limit_id——我们就得到了我们想要的“彼时彼刻”的up_limit_id。值得注意的是,由于有序性的保证,上述查找可通过二分查找完成。
显然,这个up_limit_id只是“彼时彼刻”真正的up_limit_id的近似值。但通过上述步骤,我们总是能够拿到一个比真实值要小的近似值。幸运的是,当我们拿一个更小的up_limit_id去做可见性判断时,并不会导致误判。
可以看见,上述CSM中的Commit Snapshot还包括了csm_SCN。这是因为PolarDB分布式版标准版还支持了闪回查询AS OF语法。通过闪回查询,可以轻松完成游戏回档、业务回滚、数据误删恢复等特性。有关PolarDB分布式版DN存储引擎的事务系统的设计,可参考过往文章《PolarDB分布式版存储引擎核心技术|Lizard分布式事务系统》。
SELECT sec FROM t1 AS OF SCN $SCN WHERE sec BETWEEN ? AND ?
SELECT sec FROM t1 AS OF TIMESTAMP $time WHERE sec BETWEEN ? AND ?测试结果显示,对于分布式事务的一致性查询,开启CSM(32KB内存资源 + 少量计算开销)具有显著的性能提升:
# 压测SQL,模拟命中sec列的索引
SELECT sec FROM t1 WHERE sec BETWEEN ? AND ?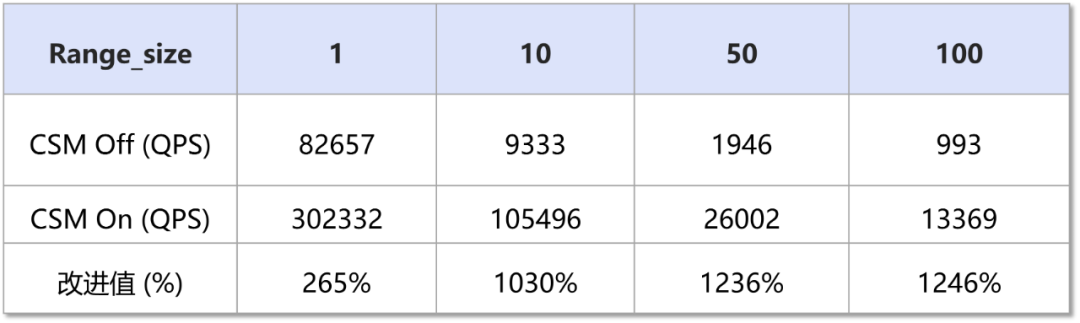
🎉 云原生数据库PolarDB分布式版(PolarDB for Xscale,简称PolarDB-X)价格下调40%,最低至0.75元/小时,点击👉「产品」即可了解详情
这篇关于数据库索引回表困难?揭秘PolarDB存储引擎优化技术的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








