本文主要是介绍MySQL6:索引使用原则,联合索引,联合主键/复合主键,覆盖索引、什么是回表?索引条件下推,索引的创建与使用,索引的创建与使用,索引失效,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MySQL6:索引使用原则,联合索引,联合主键/复合主键,覆盖索引、什么是回表?索引条件下推,索引的创建与使用,索引的创建与使用,索引失效
- 索引使用原则
- 列的离散(sdn)度
- 联合索引
- 创建联合索引
- 联合索引最左匹配
- 建立联合索引之后,联合索引的最左字段还要再建普通索引吗?
- 联合索引使用场景
- 什么时候能用到联合索引
- 联合主键/复合主键
- 覆盖索引
- 什么是回表?
- 什么是覆盖索引?
- 如何判断是覆盖索引
- 索引条件下推(Index Condition Pushdown)
- 判断使用索引条件下推
- 索引的创建与使用
- 索引的创建
- 索引失效
- MySQL合集
索引使用原则
我们容易有以一个误区,就是在经常使用的查询条件上都建立索引,索引越多越好,那到底是不是这样呢?
并不是越多越好,索引好占用磁盘空间的,你的表200M,你的索引可能就是4G,如果搞很多索引,磁盘空间浪费会很大,因此只在必要的字段上建立索引。那么什么样的字段适合建立索引呢,一般选择列的离散度高的列建立索引。
列的离散(sdn)度
列的离散度的公式:
## 列的全部不同值和所有数据行的比例
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name;
数据行数相同的情况下,分子越大,列的离散度就越高。简单来说,如果列的重复值越多,离散度就越低,重复值越少,离散度就越高。
如果在B+Tree里面的重复值太多(比如性别建立索引),MySQL的优化器发现走索引跟使用全表扫描差不了多少的时候,就算建了索引,也不一定会走索引。
联合索引
前面我们说的都是针对单列创建的索引,但有的时候我们的多条件査询的时候,也会建立联合索引。单列索引可以看成是特殊的联合索引。
创建联合索引
CREATE TABLE `stu_innodb` (`id` INT(11) NOT NULL,`name` VARCHAR(50) NOT NULL COLLATE 'utf8mb4_unicode_ci',`sex` INT(11) NULL DEFAULT NULL,`age` INT(11) NULL DEFAULT NULL,`card_id` VARCHAR(10) NOT NULL COLLATE 'utf8mb4_unicode_ci'
)
COLLATE='utf8mb4_unicode_ci'
ENGINE=InnoDB
;
比如我们在stu_innodb表上面,给card_id和name建立了一个联合索引。
## 删除索引
ALTER TABLE stu_innodb DROP INDEX idx_cardid_name;
## 创建联合索引
ALTER TABLE stu_innodb ADD INDEX idx_cardid_name (card_id,name);
## 查看索引
show index from stu_innodb;

联合索引最左匹配
联合索引在B+Tree中是复合的数据结构,它是按照索引的顺序从左到右的顺序来建立搜索树的,比如联合索引idx_cardid_name (card_id,name)就是card_id在左边,name在右边。
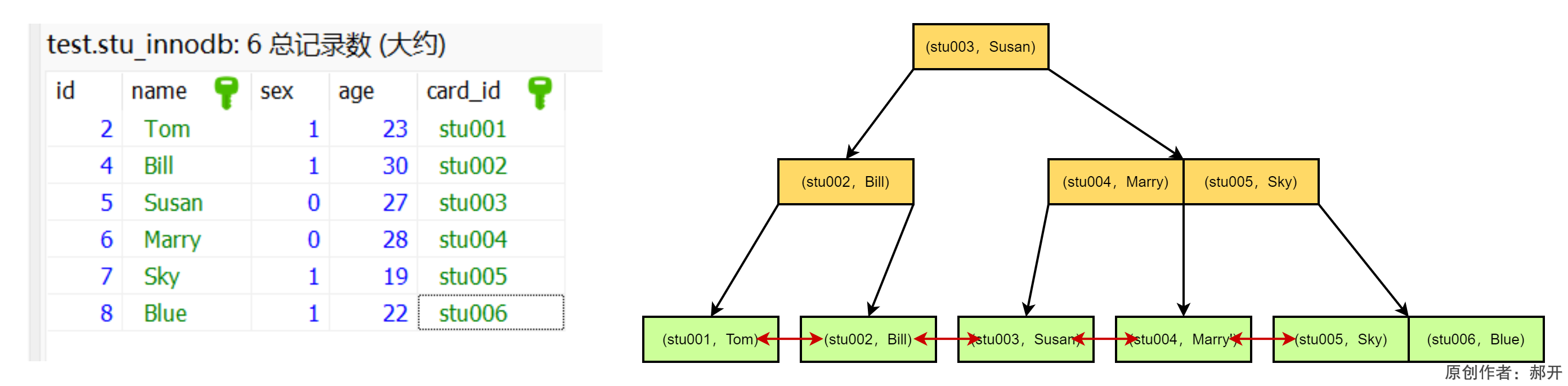
如图,card_id是有序的,name是无序的。当card_id相等的时候, name才是有序的。
这个时候我们使用where card_id='stu006' and name='Blue'去査询数据的时候,B+Tree会优先比较card_id来确定下一步应该搜索的方向,往左还是往右。如果card_id相同的时候再比较name,但是如果查询条件没有card_id,就不知道第一步应该查哪个节点,因为建立搜索树的时候card_id是第一个比较因子,所以用不到索引。
建立联合索引之后,联合索引的最左字段还要再建普通索引吗?
CREATE INDEX idx_cardid on user_innodb(card_id);
CREATE INDEX idx_cardid_name on user_innodb(card_id,name);
当我们创建一个联合索引的时候,按照最左匹配原则,用左边的字段card_id去査询的时候,也能用到索引,所以第一个索引完全没必要。因为联合索引(card_id,name)相当于建立了两个索引(card_id),(card_id,name)。
如果我们创建三个字段的索引index(a,b,c),相当于创建三个索引:
- index(a)
- index(a,b)
- index(a,b,c)
同理根据最左原则:
where a=?:可以where a=? and b=?:可以where a=? and b=? and c=?:可以where a=? and c=?:可以用到a的索引,不可以用到c的,因为中断(跳过)bwhere b=?:不可以where b=? and c=?:不可以
在不含最左的a的where条件中,是不能使用到联合索引的,且中断(跳过)不能使用到联合索引的。
联合索引使用场景
根据联合索引的特性,什么时候会用到联合索引呢?
那肯定是查询条件覆盖了联合索引的列。
比如查询高考成绩,必须输入考生姓名和学生的身份证号,那么这种场景,就可以对二者建立联合索引。
什么时候能用到联合索引
- 顺序使用两个字段,用到联合索引:
-
## 顺序使用两个字段,用到联合索引: explain select * from stu_innodb where card_id='stu006' and name='Blue';
-
- 乱序使两个字段,用到联合索引(查询优化器的功劳):
-
## 乱序使两个字段,用到联合索引: explain select * from stu_innodb where name='Blue' and card_id='stu006';
-
- 使用左边的索引字段,用到联合索引:
-
## 使用左边的索引字段,用到联合索引: explain select * from stu_innodb where card_id='stu006';
-
- 不使用左边的索引字段,无法使用索引,全表扫描:
-
## 不使用左边的索引字段,无法使用索引,全表扫描: explain select * from stu_innodb where name='Blue';
所以,我们在建立联合索引的时候,一定要把最常用的列放在最左边,查询条件必须由第一个索引字段开始,不能中断(跳过)。
-
联合主键/复合主键
主键有唯一的约束。当多个字段组合成唯一标识的时候,创建复合主键。
比如一个学生表中,学生卡号、姓名、学院是一条记录的唯一标识,那么就可以建立复合主键,通过定义复合主键,减少了表的数量,不是一个college(学院)一张表。
CREATE TABLE `stu_innodb` (`name` VARCHAR(50) NOT NULL COLLATE 'utf8mb4_unicode_ci',`sex` INT(11) NULL DEFAULT NULL,`age` INT(11) NULL DEFAULT NULL,`card_id` VARCHAR(10) NOT NULL COLLATE 'utf8mb4_unicode_ci',`college` VARCHAR(10) NOT NULL COLLATE 'utf8mb4_unicode_ci',PRIMARY KEY (`card_id`, `name`, `college`) USING BTREE
)
COLLATE='utf8mb4_unicode_ci'
ENGINE=InnoDB
;
复合主键的特点:
- 因为复合主键需要存储多个字段的值,相对于单列主键来说要消耗更多的存储空间
- 联合主键包含多个列的时候,不允许所有的字段都相同。因为判断是否重复更复杂(代码中重写hashCode和equals也是)
- 举例:一张表有a、b、c三个字段,不允许a、b、c三个字段的值都相同,可以有部分的值都相同,例如
- record1:1 2 3
- record1:2 3 4
- record1:1 1 3
- record1:1 1 3 不允许
- 举例:一张表有a、b、c三个字段,不允许a、b、c三个字段的值都相同,可以有部分的值都相同,例如
- 表结构修改或者数据迁移会更加困难
- 如果目的是限制唯一性,可以直接拼接两个字段的内容,比如CAIJING1001,CHUANMEI1001,或者用唯一索引UNIQUE KEY也可以实现
- 如果目的不是为了限制唯一性,或者有其它检查唯一性的方法,用自增ID之类的无业务意义的字段作为主键更合适。自增ID在插入数据时,引起的页分裂和合并更少
MBG(MyBatis Generator,MBG 在配置中为每个表简单的CRUD操作生成 SQL)对复合主键,会生成两个实体类
覆盖索引
什么是回表?
回表:非主键索引,我们先通过索引找到主键索引的键值,再通过主键值查出索引里面没有的数据,它比基于主键索引的查询多扫描了一棵索引树,这个过程就叫回表。
当我们用name索引查询一条记录,它会在二级索引的叶子节点找到name=Susan,拿到主键值,也就是id = 3,然后再到主键索引的叶子节点拿到数据。
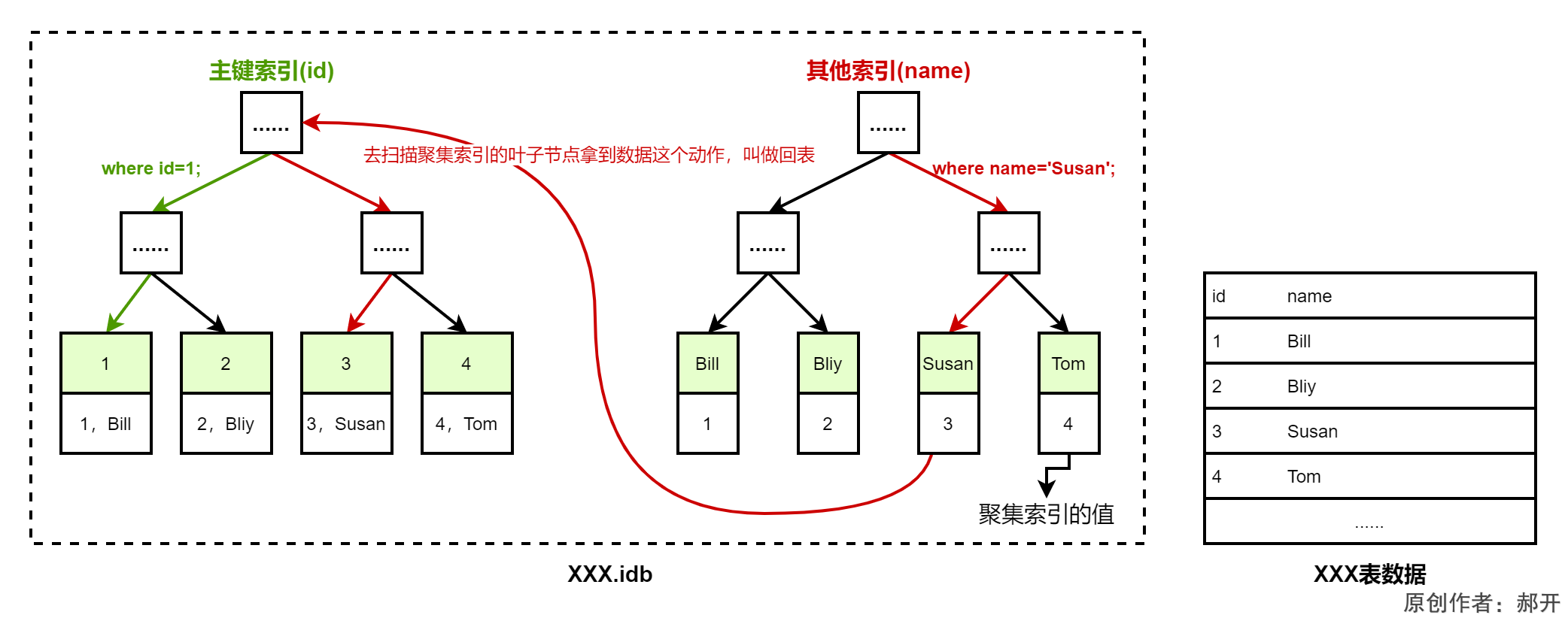
什么是覆盖索引?
覆盖索引:在二级索引里面,不管是单列索引还是联合索引,如果select的数据列只用从索引中就能够取得,不必从数据区中读取,这时候使用的索引就叫做覆盖索索引,这样就避免了回表。。比如上图select name from tbl_xxx where name=? ,因为二级索引的叶子节点上就已经存储了name的数据,因此不需要回表,性能就会高点。
如何判断是覆盖索引
覆盖索引并不是索引的一种类型,而是使用索引产生的一种情况。Explain中的Extra列里面值为'Using index'代表属于覆盖索引的情况。
在联合索引idx_cardid_name (card_id,name)中
这三个查询语句属于覆盖索引:
- ①使用联合索引②select的所有列已经包含在了用到的索引中:
-
属于覆盖索引explain select name,card_id from stu_innodb where card_id='stu006' and name='Blue';
-
- ①使用联合索引②select的所有列已经包含在了用到的索引中:
-
用到了索引,属于覆盖索引,因为联合索引的创建,使得当前的B+Tree存储了explain select name from stu_innodb where card_id='stu006';card_id,name的数据,因此不需要回表

-
- ①不使用联合索引②select的所有列已经包含在了用到的索引中:
-
还是用到了索引,并且属于覆盖索引,查询优化器优化了,优化器觉得用索引更快,所以还是用到了索引explain select name from stu_innodb where name='Blue';
-
覆盖索引减少了I/O次数,减少了数据的访问量,可以大大地提升查询效率。
索引条件下推(Index Condition Pushdown)
MySQL架构是分层的,可以分为连接层、服务层、存储引擎层。
不同的索引是在存储引擎层中实现的。如果where条件包含索引,那么是可以在存储引擎层完成数据过滤的。如果用不到索引过滤数据,就需要去Server层。那么如何优化呢?
如果返回了一大堆数据都不是就客户端需要的,那么能不能把这个过滤的动作先在存储引擎层做完,即使查询条件用不到索引,也先在存储引擎中过滤一遍,这个动作,就叫做索引条件下推。
索引条件下推(Index Condition Pushdown),5.6以后完善的功能,不需要我们开启,是InnoDB自动开启,自动优化的。只适用于二级索引。ICP的目标是减少访问表的完整行的读数量从而减少I/O操作。这里说的下推,其实是意思是把过滤的动作在存储引擎做完,而不需要到Server层过滤,把原来存储引擎无法使用的过滤条件,还是先让他在存储引擎中先过滤。
我们建个表来深入理解一下,idx_college_cardid作为二级联合索引
-- 导出 表 test.stu_innodb 结构
-- 导出 表 test.stu_innodb 结构
CREATE TABLE IF NOT EXISTS `stu_innodb` (`id` int(11) NOT NULL,`name` varchar(50) COLLATE utf8mb4_unicode_ci NOT NULL,`sex` int(11) DEFAULT NULL,`age` int(11) DEFAULT NULL,`card_id` varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL,`college` varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL,PRIMARY KEY (`id`) USING BTREE,KEY `idx_college_cardid` (`college`,`card_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;-- 正在导出表 test.stu_innodb 的数据:~12 rows (大约)
INSERT INTO `stu_innodb` (`id`, `name`, `sex`, `age`, `card_id`, `college`) VALUES(2, 'Tom', 1, 23, 'stu001', '财经'),(4, 'Bill', 1, 30, 'stu002', '财经'),(5, 'Susan', 0, 27, 'stu003', '财经'),(6, 'Marry', 0, 28, 'stu004', '财经'),(7, 'Sky', 1, 19, 'stu005', '财经'),(8, 'Blue', 1, 22, 'stu006', '财经'),(12, 'Tom', 1, 23, 'stu001', '金融'),(14, 'Bill', 1, 30, 'stu002', '金融'),(15, 'Susan', 0, 27, 'stu003', '金融'),(16, 'Marry', 0, 28, 'stu004', '金融'),(17, 'Sky', 1, 19, 'stu005', '金融'),(18, 'Blue', 1, 22, 'stu006', '金融');
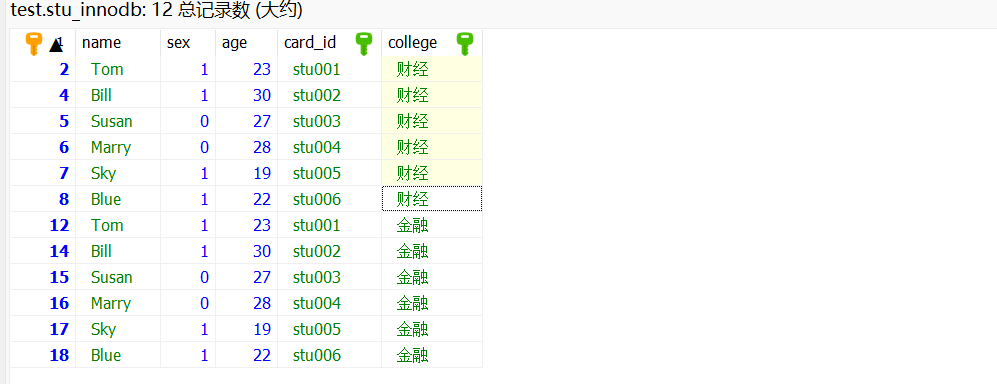
当我们执行SQL语句SELECT * FROM stu_innodb where college='金融' AND card_id LIKE '%stu002';,正常情况来说(也就是不适用索引条件下推的情况),因为字符是从左往右排序的,当你把%加在前面的时候,是不能基于索引去比较的,所以只有college这个字段能够用于索引比较和过滤。
按有没有使用索引条件下推,查询过程分为两种情况:

-
没有索引下推,查询过程是这样的:
- ① 根据联合索引查出所有
college='金融'的二级索引数据,在其叶子节点上得到对应的主键索引值(12,14,15,16,17,18) - ② 回表,到主键索引上查询全部复合条件的数据,6条数据
- ③ 把这6条数据返回给Server层,在Server层对这6条数据,进行符合
card_id LIKE '%stu002'条件的过滤
注意:索引的比较是在存储引擎层进行的,数据记录的比较,是在Server层进行的。而当
card_id LIKE '%stu002'条件不能用于索引过滤时,Server层不会把card_id LIKE '%stu002'条件传递给存储引擎,所以读取很多条没有必要的记录(Server层并不需要)。
这时候,如果满足college='金融'的记录有10万条,就会有99999条没有必要读取的记录,而且都还要返回给Server层。所以,根据college字段过滤的动作,能不能在存储引擎层完成呢?就是下面的查询方法。 - ① 根据联合索引查出所有
-
使用索引下推,查询过程是这样的:
- ① 根据联合索引查出所有
college='金融'的二级索引数据,在其叶子节点上得到对应的主键索引值(12,14,15,16,17,18) - ② 然后从二级索引中筛选出
card_id LIKE '%stu002'条件的索引,这下就只有一个了,(14) - ③ 回表,到逐渐索引上查询全部符合条件的数据(1条数据),返回Server层
先用
college='金融'条件进行二级索引范围扫描,读取数据表记录;然后进行比较,检查是否符合card_id LIKE '%stu002'的条件。此时6条中只有1条符合条件。 - ① 根据联合索引查出所有
判断使用索引条件下推
Extra是Using index condition就代表使用索引条件下推,全称其实就是Using index condition push down。
查询是否开启索引条件下推
show variables LIKE 'optimizer_switch';
可以看到,index_condition_pushdown=on,InnoDB中,默认开启索引条件下推
index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on
我们先把索引条件下推关闭
set optimizer_switch='index_condition_pushdown=off';
关闭之后,查看SQL执行计划,会发现Extra是Using where
explain SELECT * FROM stu_innodb where college='金融' AND card_id LIKE '%stu002';

Extra返回Using where,表示存储引擎返回的数据不全是Server层需要的,需要在Server层再做过滤
启用索引条件下推之后,再次查看SQL执行计划
set optimizer_switch='index_condition_pushdown=on';
explain SELECT * FROM stu_innodb where college='金融' AND card_id LIKE '%stu002';
会发现Extra变成了Using index condition,全称其实就是Using index condition push down。

索引的创建与使用
因为索引对于改善查询性能的作用是巨大的,所以我们的目标是尽量使用索弓I。
索引的创建
-
在用于where判断order排序和join的(on)、group by的字段上创建索引。
-
索引的个数不要过多。——浪费空间,更新变慢。
-
过长的字段,但是匹配只需要前面的内容(具体是几个字符在建立索引时指定),建立前缀索引。
alter table 表名 add index 索引名(列名(长度));注意:在前缀索引中B+Tree里保存的就不是完整的该字段的值,必须要回表才能拿到需要的数据。所以,用了前缀索引,就用不了覆盖索引了。
-
区分度低的字段,例如性别,不要建索引。——离散度太低,导致扫描行数过多。
-
频繁更新的值,不要作为主键或者索引。——造成页分裂和合并,引起B+Tree的结构调整,会浪费很大的性能
-
随机无序的值,不建议作为索引(例如身份证、UUID)。——无序,分裂
-
联合索引把散列性高(区分度高)的值放在前面。
-
创建复合索引,而不是修改单列索引。
索引失效
-- 导出 表 test.stu_innodb 结构
CREATE TABLE IF NOT EXISTS `stu_innodb` (`id` int(11) NOT NULL,`name` varchar(50) COLLATE utf8mb4_unicode_ci NOT NULL,`sex` int(11) DEFAULT NULL,`age` int(11) DEFAULT NULL,`card_id` varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL,`college` varchar(10) COLLATE utf8mb4_unicode_ci NOT NULL,PRIMARY KEY (`card_id`,`name`,`college`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;-- 正在导出表 test.stu_innodb 的数据:~6 rows (大约)
INSERT INTO `stu_innodb` (`id`, `name`, `sex`, `age`, `card_id`, `college`) VALUES(2, 'Tom', 1, 23, 'stu001', ''),(4, 'Bill', 1, 30, 'stu002', ''),(5, 'Susan', 0, 27, 'stu003', ''),(6, 'Marry', 0, 28, 'stu004', ''),(7, 'Sky', 1, 19, 'stu005', ''),(8, 'Blue', 1, 22, 'stu006', '');
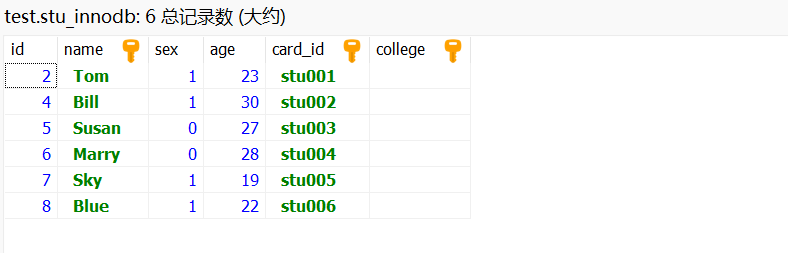
以这个表为例,建立了复合主键

-
索引列上使用函数(
replace\SUBSTR\CONCAT\sum count avg)、表达式计算('+'、'-'、'×'、'÷')。因为会得到一个不确定的结果,所以无法使用索引,宁愿计算出它的结果放在表达式的右边,都比函数计算要好explain SELECT * FROM stu_innodb where id+1 = 4;
-
字符串不加引号,出现隐式转换
explain SELECT * FROM stu_innodb where card_id = 11;
-
索引的最左前缀原则,like条件中前面带%。where条件中
LIKE '%001%'、LIKE '001%'、'%001'都用不到索引,为什么?explain SELECT * FROM stu_innodb where card_id LIKE '%001%'; explain SELECT * FROM stu_innodb where card_id LIKE '001%'; explain SELECT * FROM stu_innodb where card_id LIKE '%001';
过滤的开销太大。这个时候可以用全文索引。 -
负向查询:
NOT LIKE不能:explain SELECT * FROM stu_innodb where card_id NOT LIKE '001%';
<>和NOT IN在某些情况下可以:explain SELECT * FROM stu_innodb where card_id <> 'stu001';
explain SELECT * FROM stu_innodb where card_id NOT LIKE '001%';
其实,InnoDB到底用不用索引,最终都是优化器说了算。
优化器是基于什么的优化器?
基于cost开销(Cost Base Optimizer),也叫基于成本的优化器,成本包括两方面,I/O,CPU。它不是基于规则(Rule-Based Optimizer)的优化器,也不是基于语义。怎么样开销小就怎么来。
比如你回家的路线有三条,那么两个优化器会怎么做:
- 基于规则(Rule-Based Optimizer)的优化器:每次固定选择A路线
- 基于成本(Cost Base Optimizer)的优化器:会看当前哪条路到家最快(基于成本考虑),然后选择一条最合适的路线
也就是说,使用索引有基本原则,但是没有具体细则,没有什么情况一定用索引,什么情况一定不用索引的规则。
MySQL合集
MySQL1:MySQL发展史,MySQL流行分支及其对应存储引擎
MySQL2:MySQL中一条查询SQL是如何执行的?
MySQL3:MySQL中一条更新SQL是如何执行的?
MySQL4:索引是什么;索引类型;索引存储模型发展:1.二分查找,2.二叉查找树,3.平衡二叉树,4.多路平衡查找树,5. B+树,6.索引为什么不用红黑树?7.InnoDB的hash索引指什么?
MySQL5:MySQL数据存储文件;MylSAM中索引和数据是两个独立的文件,它是如何通过索引找到数据呢?聚集索引/聚簇索引,InnoDB中二级索引为什么不存地址而是存键值?row ID如何理解?
MySQL6:索引使用原则,联合索引,联合主键/复合主键,覆盖索引、什么是回表?索引条件下推,索引的创建与使用,索引的创建与使用,索引失效
这篇关于MySQL6:索引使用原则,联合索引,联合主键/复合主键,覆盖索引、什么是回表?索引条件下推,索引的创建与使用,索引的创建与使用,索引失效的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




