下推专题

贝壳面试:什么是回表?什么是索引下推?
尼恩说在前面 在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: 1.谈谈你对MySQL 索引下推 的认识? 2.在MySQL中,索引下推 是如何实现的?请简述其工作原理。 3、说说什么是 回表,什么是 索引下推 ? 最近有小伙伴在面试 贝壳、soul,又遇到了相关的

经验笔记:状态机与下推自动机的理解与应用场景
经验笔记:状态机与下推自动机的理解与应用场景 引言 在软件开发和计算机科学领域,状态机和下推自动机是两个重要的概念,它们帮助我们理解和设计各种类型的系统。本文将简要介绍这两种模型,并详细探讨它们的应用场景。 状态机概述 状态机是一种数学模型,它通过一组状态、事件、转移条件以及动作来描述一个系统的动态行为。状态机的核心在于它的状态转换机制,即在给定条件满足时,系统如何从一个状态转移到另一个状

openGauss 之谓词下推代码走读
一. 前言 谓词下推是每一个SQL引擎必备的功能。本文主要通过走读代码了解openGauss中是如何实现谓词下推能力的。 谓词下推即是将过滤条件尽可能往tablescan的数据源节点下推,以实现上层算子尽可能少计算的能力,如下所示的执行计划便已经将谓词id<55下推到了tablescan节点。 二. 执行计划生成时将谓词信息保存在ScanState.ps.

MySQL中的回表查询、索引覆盖、索引下推
本文重点介绍索引中的常见概念:回表查询、索引覆盖、索引下推 一、回表查询 我们首先理解:在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种: 分类含义特点聚集索引 (Clustered Index)将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据必须有,而且只有一个二级索引 (Secondary Index)将数据与索引分开存储,索引结构的叶子节点关联的是对应的主

优化数据库性能:MySQL索引下推技术详解与应用策略
引言 在数据库的世界里,性能优化始终是开发者和数据库管理员关注的焦点。MySQL索引下推(Index Condition Pushdown,简称ICP)作为一项关键的优化技术,自5.6版本引入以来,已成为提升查询效率的利器。本文将深入探讨ICP的原理、实践应用以及如何通过它来优化数据库性能。 基础概念 MySQL的索引下推(Index Condition Pushdown,简称ICP
MYSQL 索引下推 45讲
刘老师群里,看到一位小友 问<MYSQL 45讲>林晓斌的回答 大意是一个组合索引 (a,b,c) 条件 a > 5 and a <10 and b='123', 这样的情况下是如何? 林老师给的回答是 A>5 ,然后下推B='123' 小友 问 "为什么不是先 进行范围查询,然后在索引下推 b='123'?" 然后就没有然后了.... 说真的,不是我有意踩林老师, 我只是说<MYSQL

PawSQL优化 | 分页查询太慢?别忘了投影下推
在进行数据库应用开发中,分页查询是一项非常常见而又至关重要的任务。但你是否曾因为需要获取总记录数的性能而感到头疼?现在,让PawSQL的投影下推优化来帮你轻松解决这一问题!本文以TPCH的Q12为案例进行验证,经过PawSQL的优化后性能提升6000多倍! 分页查询的痛点 在进行分页查询时,我们通常需要获取总记录数以计算总页数。绝大多少程序员会在原查询上添加count(1)或count(*)
【高频】什么是索引的下推和覆盖
面试回答: 索引的下推是指数据库引擎在执行查询时,将过滤条件尽可能地应用到索引上,以减少需要检索的数据量,从而提高查询性能。这样可以减少数据库引擎从磁盘加载的数据量,提高查询效率。覆盖索引是指一个索引包含了查询需要的所有字段,因此数据库引擎可以直接使用索引返回查询结果,而无需再次访问实际的数据行。覆盖索引通常用于优化查询性能,特别是对于那些需要返回大量数据列的查询。 总结:索引的下推和覆盖索引

MySQL——索引下推
1、使用前后对比 index Condition Pushdown(ICP)是MySQL5.6中新特性,是一种在存储引擎层使用索引过滤数据的优化方式。 如果没有ICP,存储引擎会遍历索引以定位基表中的行,并将它们返回给MySQL服务器,由MySQL服务器评估WHERE后面的条件是否保留行。启用ICP后(默认启用),如果部分WHERE条件可以仅使用索引中的列进行筛选,则MySQL服务器会把这部分

Flink1.17之前实现JdbcLookup谓词下推
Flink1.17之前实现JdbcLookup谓词下推 需求背景 Flink在1.17版本之前,flink-connector-jdbc的LookupJoin是不支持on条件下推的,例如on device_id=‘1’,查询SQL中是不会包含device_id='1’的条件,相关issue:https://issues.apache.org/jira/browse/FLINK-32321,在1

【MySQL数据库 | 第二十三篇】什么是索引覆盖和索引下推
前言: 在数据库查询优化领域,索引一直被视为关键的工具,用于提高查询性能并加速数据检索过程。然而,随着数据库技术的不断发展,出现了一些新的优化技术,其中包括索引下推(Index Pushdown)和索引覆盖(Index Covering)。这两种技术在提高查询性能和降低系统负载方面发挥了重要作用,并且已经成为了现代数据库系统中不可或缺的一部分。 目录 前言: 索引分类: 二者优缺点
备份的 “算子下推”:BR 简介丨TiDB 工具分享
BR 选择了在 Transaction KV 层面进行扫描来实现备份。这样,备份的核心便是分布在多个 TiKV 节点上的 MVCC Scan:简单,粗暴,但是有效,它生来就继承了 TiKV 的诸多优势:分布式、利于横向拓展、灵活(可以备份任意范围、未 GC 的任意版本的数据)等等优点。 相较于从前只能使用 mydumper 进行 SQL 层的备份,BR 能够更加高效地备份和恢复:它取消了 SQL

MySQL 中 聚集索引、非聚集索引、覆盖索引、索引下推 到底是什么
一、什么是 聚集索引、非聚集索引 在MySQL数据库中,索引是提高查询效率的关键。而聚集索引、非聚集索引、覆盖索引、索引下推其实是索引优化的重要策略之一。那这些名词的含义到底是什么呢? 在开始分析前,先来了解下 B+ 树的索引结构 和 回表查询: B+ 树结构 B+树是 B树的变体,将树的结构分为了叶子节点和非叶子节点。其中非叶子节点不存储具体数据,只存放主键和指向下一级数据的指针。而叶子
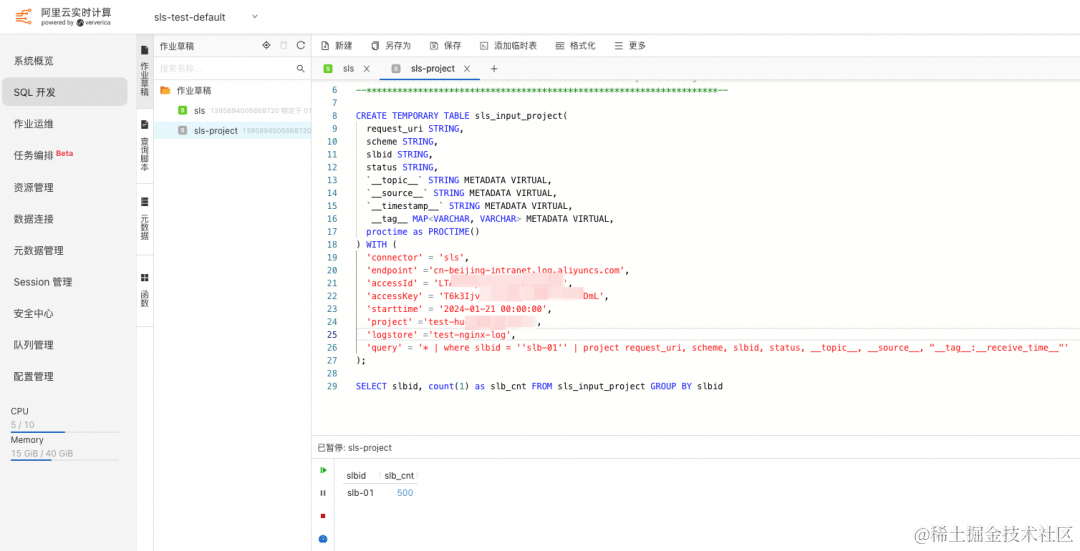
使用 SPL 高效实现 Flink SLS Connector 下推
作者:潘伟龙(豁朗) 背景 日志服务 SLS 是云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务,基于日志服务的便捷的数据接入能力,可以将系统日志、业务日志等接入 SLS 进行存储、分析;阿里云 Flink 是阿里云基于 Apache Flink 构建的大数据分析平台,在实时数据分析、风控检测等场景应用广泛。阿里云 Flink 原生支持阿里
【MySQL】索引下推
索引下推(ICP)是一种在存储引擎层使用过滤数据的优化方式。使用ICP的好处在于其可以减少存储引擎必须访问基表的次数和MySQL服务器必须访问存储引擎的次数。但ICP的加速效果取决于存储引擎内通过ICP筛掉的数据比例。 举个例子 CREATE INDEX zip_last_first ON people(zipcode, lastname, firstname);EXPLAIN SELE

Mysql索引下推、Order by优化和Using filesort文件排序原理
目录 1、like 'KK%' 和索引下推 2、Order by 和 Group by 优化 3、Using filesort文件排序原理 // 以下建表结构和数据同《Mysql explain 索引优化案例》 1、like 'KK%' 和索引下推 like 'KK%' 一般情况都会走索引,原因是like 'KK%' 用到了索引下推优化 EXPLAIN SELECT * FROM
MySQL优化之索引下推
(/≧▽≦)/~┴┴ 嗨~我叫小奥 ✨✨✨ 👀👀👀 个人博客:小奥的博客 👍👍👍:个人CSDN ⭐️⭐️⭐️:传送门 🍹 本人24应届生一枚,技术和水平有限,如果文章中有不正确的内容,欢迎多多指正! 📜 欢迎点赞收藏关注哟! ❤️ 文章目录 MySQL优化之索引下推一、概念二、验证2.1 建表语句2.2 关闭索引下推2.3 打开索引下推 三、总结 MySQL
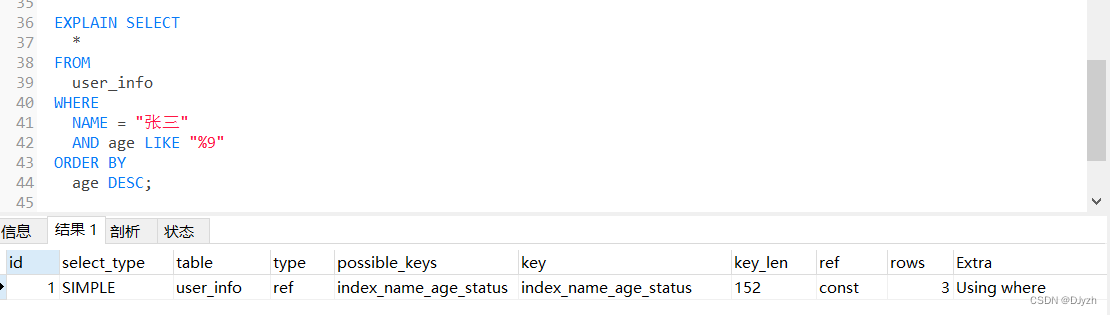
mysql(四)索引下推
目录 数据准备: 标准案列: 问题1:索引下推如何开启和关闭?(MySQL5.6以后的版本) 问题2:索引下推在哪些情况下无法使用? 2.1下推条件遇到子查询 2.2下推条件遇到函数 2.3非InnoDB表和MyISAM表 注意事项: 1、索引下推只能存在联合索引里 2、范围列可以用到索引,但是范围列后面的列无法用到索引 3、不要使用SELECT *
Hive的Join连接、谓词下推
前言 Hive-3.1.2版本支持6种join语法。分别是:inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左半开连接)、cross join(交叉连接,也叫做笛卡尔乘积)。 一、Hive的Join连接 数据准备: 有两张表studentInfo、studentScor
聚簇索引、非聚簇索引、回表、索引下推、覆盖索引
聚簇索引(主键索引) 非叶子节点上存储的是索引值,叶子节点上存储的是整行记录。 非聚簇索引(非主键索引、二级索引) 非叶子节点上存储的都是索引值,叶子节点上存储的是主键的值。非聚簇索引需要回表,IO消耗。 回表 非聚簇索引先执行一次主键查询,再通过适配的主键的值之后,再进行一次二级索引,这个过程就是回表。 覆盖索引 一次索引就可以得到数据,无需回表。覆盖索引发生在联合索引,where

openGauss学习笔记-210 openGauss 数据库运维-常见故障定位案例-谓词下推引起的查询报错
文章目录 openGauss学习笔记-210 openGauss 数据库运维-常见故障定位案例-谓词下推引起的查询报错210.1 谓词下推引起的查询报错210.1.1 问题现象210.1.2 原因分析210.1.3 处理办法 openGauss学习笔记-210 openGauss 数据库运维-常见故障定位案例-谓词下推引起的查询报错 210.1 谓词下推引起的查询报错 2
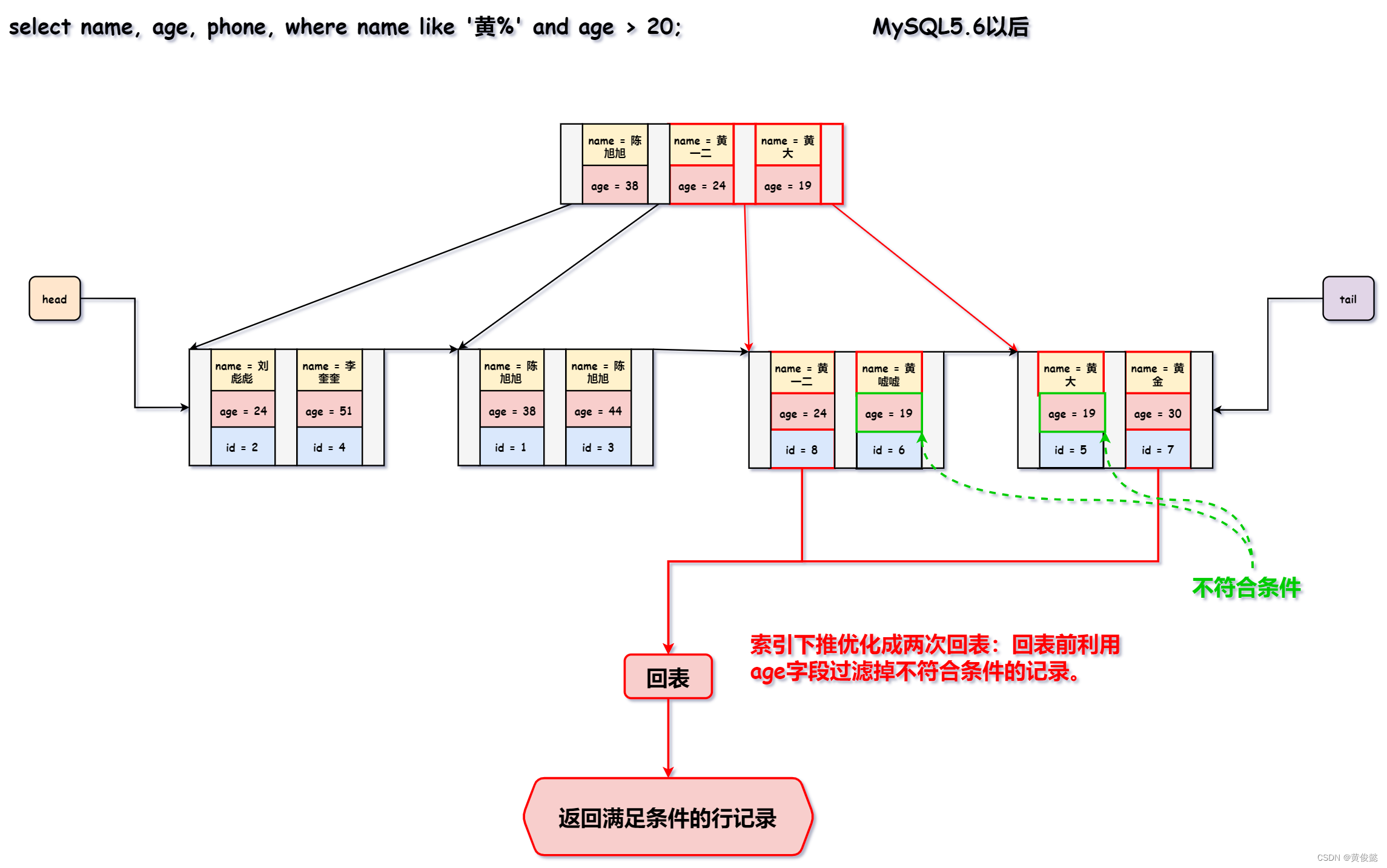
MySQL知识点总结(一)——一条SQL的执行过程、索引底层数据结构、一级索引和二级索引、索引失效、索引覆盖、索引下推
MySQL知识点总结(一)——一条SQL的执行过程、索引底层数据结构、一级索引和二级索引、索引失效、索引覆盖、索引下推 一条SQL的执行过程索引底层数据结构为什么不使用二叉树?为什么不使用红黑树?为什么不使用hash表?为什么不使用b-tree? 一级索引和二级索引索引失效索引覆盖索引下推 一条SQL的执行过程 客户端:用于向服务端发起sql查询或更新请求,MySQL自带的命
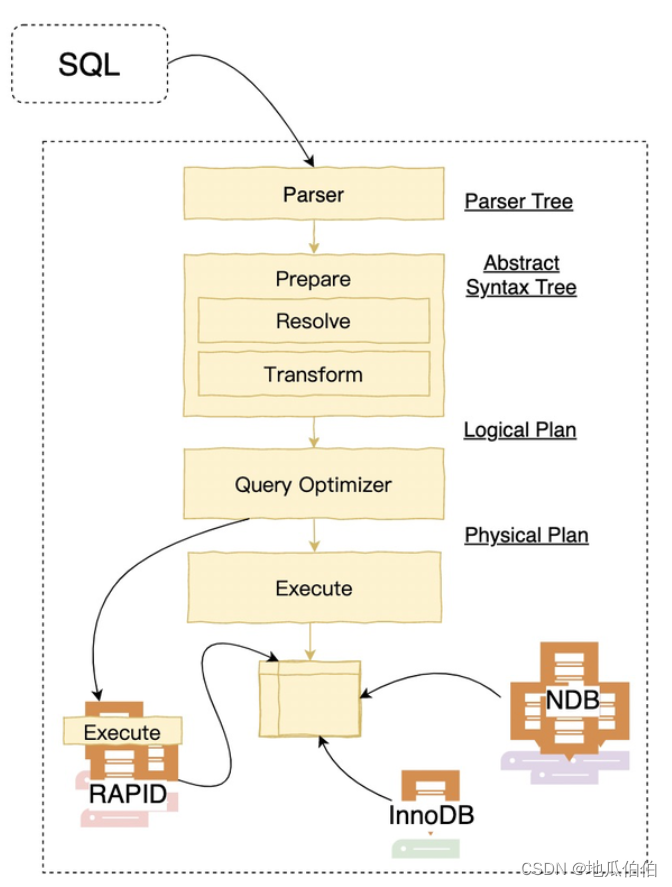
MySQL索引优化:深入理解索引下推原理与实践
随着MySQL的不断发展和升级,每个版本都为数据库性能和查询优化带来了新的特性。在MySQL 5.6中,引入了一个重要的优化特性——索引下推(Index Condition Pushdown,简称ICP)。ICP能够在某些查询场景下显著提高查询性能,减少不必要的数据行访问。 一、产生背景 在MySQL 5.6之前,当查询使用到复合索引时,MySQL会先根据索引的最左前缀原则,在索引上查找
索引下推(ICP)的应用条件
如果表访问的类型为range、ref、 eq_ref和ref_or_null可以使用索引下推 ICP可以用于InnoDB和MyISAM表,包括分区表InnoDB和MyISAM 表 对于InnoDB表,ICP 仅用于二级索引。ICP 的目标是减少全行读取次数,从而减少I/O操作。 当SQL使用覆盖索引时,不支持ICP.因为这种情况下使用ICP不会减少I/O。 相关子查询的条件不能使用ICP 注意I