本文主要是介绍【高频】什么是索引的下推和覆盖,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
面试回答:
- 索引的下推是指数据库引擎在执行查询时,将过滤条件尽可能地应用到索引上,以减少需要检索的数据量,从而提高查询性能。这样可以减少数据库引擎从磁盘加载的数据量,提高查询效率。
- 覆盖索引是指一个索引包含了查询需要的所有字段,因此数据库引擎可以直接使用索引返回查询结果,而无需再次访问实际的数据行。覆盖索引通常用于优化查询性能,特别是对于那些需要返回大量数据列的查询。
总结:索引的下推和覆盖索引都是用于优化查询性能的技术。索引的下推通过将过滤条件应用到索引上,减少实际数据的检索量;而覆盖索引通过包含所有需要的字段,避免了回表操作,提高了查询效率。这两种技术通常结合使用,以提高数据库查询的性能。
一、覆盖索引
https://juejin.cn/post/7221910604469796922 (参考)
1.定义
在MySQL的查询优化过程中,覆盖索引是一种常见的优化技术。覆盖索引指的是一个查询可以仅通过索引就能够返回所需的所有列,而无需再次到表中查找。 【当sql语句的所求查询字段(select列)和查询条件字段(where子句)全都包含在一个索引中 (联合索引),可以直接使用索引查询而不需要回表。 】
传统的索引通常只包含关键字和指向实际数据的指针,因此在查找时需要再次到表中进行查找,以获取其他列的数据。而覆盖索引则将覆盖列也包含进了索引中,可以直接从索引中返回所有需要的列,从而避免二次查找的开销,提高了查询效率。
2.原理
利用索引数据结构存储了查询所需的字段信息,当查询命中覆盖索引时,数据库引擎可以直接从索引中获取所有需要的数据,而无需再去访问实际的数据行。
示例:
有一个包含以下字段的表 products:
product_id(主键)product_namepricecategory
现在我们想要查询产品名称和价格,但是我们只想使用覆盖索引来提高查询性能。我们可以创建一个包含 product_name 和 price 字段的覆盖索引来实现这个目的。
#创建覆盖索引
CREATE INDEX idx_product_name_price ON products (product_name, price);
由于覆盖索引包含了 product_name 和 price 字段,数据库引擎可以直接从索引中获取这两个字段的值,而无需再访问实际的数据行,从而提高查询性能。
SELECT product_name, price FROM products WHERE category = 'electronics';
3.优劣
优点:
- 避免了二次查找:使用索引覆盖可以直接从索引中返回需要的列,避免了再次到表中进行查找的开销,提高查询效率。
- 减少了I/O操作:覆盖索引通常可以使用索引下推技术,直接在索引中过滤,从而减少了要读取的行数,降低了I/O操作。
缺点:
- 对索引的要求较高:使用覆盖索引必须创建一个包含所有需要返回的列的联合索引,而联合索引的效率和使用场景都有一定限制,否则可能会导致索引扫描的代价比较大。
- 占用更多的空间:覆盖索引包含了所有需要返回的列,因此会占用更多的存储空间,而且在修改表数据时需要更新索引,也会带来额外开销。
二、索引下推
参考:https://www.cnblogs.com/three-fighter/p/15246577.html
1.定义
索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率。在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数来提高查询效率。
2.原理
MySQL服务层负责SQL语法解析、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
Mysql的大概框架:
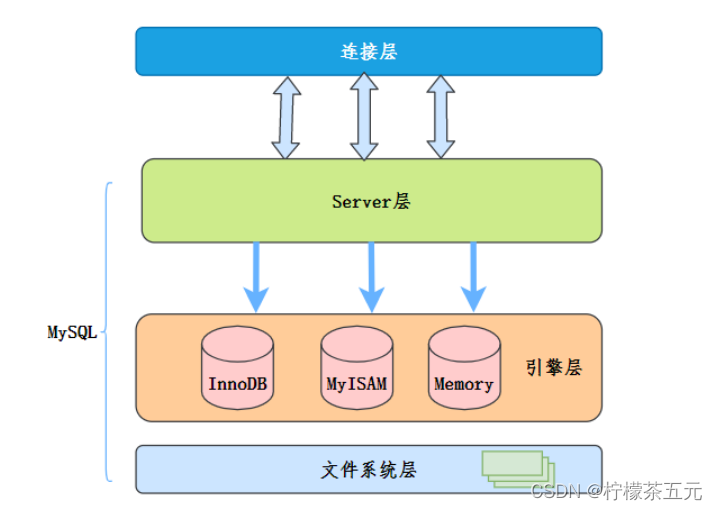
没有使用ICP的情况下,MySQL的查询:
- 存储引擎读取索引记录;
- 根据索引中的主键值,定位并读取完整的行记录;
- 存储引擎把记录交给
Server层去检测该记录是否满足WHERE条件。
使用ICP的情况下,查询过程:
- 存储引擎读取索引记录(不是完整的行记录);
- 判断
WHERE条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录; - 条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
- 存储引擎把记录交给
Server层,Server层检测该记录是否满足WHERE条件的其余部分。
示例:
有一个包含以下字段的表 orders:
order_id(主键)order_datecustomer_idtotal_amount
创建一个索引来包含 order_date 和 customer_id 字段:
CREATE INDEX idx_order_date_customer_id ON orders (order_date, customer_id); 执行一个查询,让数据库引擎利用索引下推来过滤数据:
SELECT * FROM orders WHERE order_date = '2022-01-01' AND customer_id = 123; 在这个示例中,数据库引擎可以利用索引 idx_order_date_customer_id 来过滤出 order_date 为 '2022-01-01' 并且 customer_id 为 123 的数据行,而无需再去访问实际的数据行。这样可以减少不必要的数据访问,提高查询性能。
3.条件
- 只能用于
range、ref、eq_ref、ref_or_null访问方法; - 只能用于
InnoDB和MyISAM存储引擎及其分区表; - 对
InnoDB存储引擎来说,索引下推只适用于二级索引(也叫辅助索引);
索引下推的目的是为了减少回表次数,也就是要减少IO操作。对于
InnoDB的聚簇索引来说,数据和索引是在一起的,不存在回表这一说。
- 引用了子查询的条件不能下推;
- 引用了存储函数的条件不能下推,因为存储引擎无法调用存储函数。
三、最左匹配原则
最左匹配原则:是指在使用多列索引进行查询时,MySQL会尽可能地利用索引的最左边的列来执行查询和过滤数据。这意味着,如果一个查询条件涉及到多列索引,MySQL通常只会使用索引中最左边的列来进行匹配和过滤,而不会跳过最左边的列直接使用索引中的后续列。
举个例子,假设有一个包含 (A,B,C) 三列的索引,那么在查询过程中,MySQL会优先使用 A 列来过滤数据,然后才会考虑 B 列和 C 列。如果查询条件只涉及索引的 A 列,那么索引可以被充分利用;但如果查询条件只涉及 B 列或 C 列,那么索引的后续列可能无法被有效利用。
缺点:
-
无法充分利用索引:当查询条件不满足最左匹配原则时,索引的后续列无法被有效利用,导致索引的效率降低。
-
索引冗余:为了满足最左匹配原则,可能需要创建冗余的索引,以应对不同的查询条件,这样会增加索引所占用的空间。
-
索引维护成本高:由于需要考虑最左匹配原则,索引的设计可能会更复杂,维护起来也更困难。
-
查询性能下降:当查询条件无法满足最左匹配原则时,可能需要进行全表扫描,导致查询性能下降。
使用场景:
-
组合索引:当需要创建组合索引来满足多个查询条件时,根据最常用的查询条件放在最左边,可以充分利用最左匹配原则,提高查询性能。
-
查询条件遵循左侧顺序:当查询条件经常遵循索引的最左边列的顺序时,最左匹配原则可以有效提高查询性能。
-
覆盖索引:当使用覆盖索引来优化查询性能时,最左匹配原则可以帮助确保索引覆盖所需的查询字段,从而减少回表操作,提高查询性能。
四、回表
回表:指当数据库引擎在使用索引进行查询时,如果无法直接从索引中获取全部需要的数据,就需要继续访问实际的数据行来获取完整的信息。这种情况下,数据库引擎需要通过索引找到相应的记录指针,然后再根据指针去实际的数据表中检索数据,这个过程就称为回表。
回表通常发生在以下情况:
- 当查询结果需要返回的字段不完全包含在索引中;
- 当使用覆盖索引查询的条件无法覆盖所有需要返回的字段。
回表会造成:
- 性能下降:回表操作涉及额外的IO操作,需要访问聚集索引来获取完整的数据行,导致查询性能下降。特别是在大规模数据表上或高并发的查询场景下,回表操作可能会成为性能瓶颈。
- 增加数据库负载:回表操作会引起额外的数据库负载,包括磁盘读取和内存消耗。当频繁进行回表操作时,可能会导致数据库服务器的负载过高,影响整体性能。
- 降低查询效率:由于回表需要额外的IO访问,查询的速度变慢,从而降低了查询效率,影响了用户体验。
- 增加网络开销:如果数据库服务器和应用服务器位于不同的节点或机器上,回表操作会增加网络开销,进一步影响查询性能。
这篇关于【高频】什么是索引的下推和覆盖的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






