反爬专题

网站反爬新招:一键封杀右键菜单,让你的网站数据稳如泰山,打造爆款防护秘籍!
引言 最近正在使用uniapp开发小程序,是一种跨平台技术,一次开发可以部署到多种环境,于是也顺手部署了h5网页版. 但是,突然想到那背后脆弱的接口设计,又不禁冒出一阵冷汗,也欢迎大家学习研究(结尾附网站地址)! 所以为了防止别有用心好奇宝宝窥探我的网站秘密,必须要做点什么整活,正在写文章的时候发现了右键菜单功能,给我提供了灵感. 我也可以这么玩的呀?不能右键也不影响我网页的功

【python】懂车帝字体反爬逐层解密案例(附完整代码)
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。 🏆《博客》:Python全栈,PyQt5和Tkinter桌面应用开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django

python反爬⾍策略应对
应对⽹站的反爬⾍措施通常涉及到⼀系列技术和策略,以模仿正常⽤⼾的⾏为或规避检测机制。 1. 更换⽤⼾代理(User-Agent):很多⽹站会检查HTTP请求的 User-Agent 字段来识别爬⾍。通过更换不同的 User-Agent ,爬⾍可以模仿不同的浏览器和设备访问⽹站。 import requestsurl = 'http://example.com'headers = {'Use

爬虫进阶-- 字体反爬终极解析
爬取一些网站的信息时,偶尔会碰到这样一种情况:网页浏览显示是正常的,用python爬取下来是乱码,F12用开发者模式查看网页源代码也是乱码。这种一般是网站设置了字体反爬 什么是字体反爬? 字体反爬虫:在网页中的关键部分中采用自定义的字体来显示,防止爬虫爬取到关键信息。 采用自定义字体文件是CSS3特性,可参考CSS3字体。 这是网友的见解。(ps:比我高明多了) 字体反爬也就是自定义
爬虫学习--18.反爬斗争 selenium(3)
操作多窗口与页面切换 有时候窗口中有很多子tab页面。这时候肯定是需要进行切换的。selenium提供了一个叫做switch_to.window来进行切换,具体切换到哪个页面,可以从driver.window_handles中找到。 from selenium import webdriver from selenium.webdriver import ActionChains fro

爬虫案例-亚马逊反爬分析-验证码突破(x-amz-captcha)
总体概览:核心主要是需要突破该网站的验证码,成功后会返回我们需要的参数后再去请求一个中间页(类似在后台注册一个session),最后需要注意一下 IP 是不能随意切换的 主要难点: 1、梳理整体反爬流程 2、验证码识别 3、IP识别 难度:三颗星(适合小白、初级跟中级学习) 目标网址:aHR0cHM6Ly93d3cuYW1hem9uLmNvbS9kcC9CMENTMjhaTFdT 备
爬虫案例-亚马逊反爬分析(验证码突破)(x-amz-captcha)
总体概览:核心主要是需要突破该网站的验证码,成功后会返回我们需要的参数后再去请求一个中间页(类似在后台注册一个session),最后需要注意一下 IP 是不能随意切换的 主要难点: 1、梳理整体反爬流程 2、验证码识别 3、IP识别 难度:三颗星(适合小白、初级跟中级学习) 目标网址:aHR0cHM6Ly93d3cuYW1hem9uLmNvbS9kcC9CMENTMjhaTFdT 备
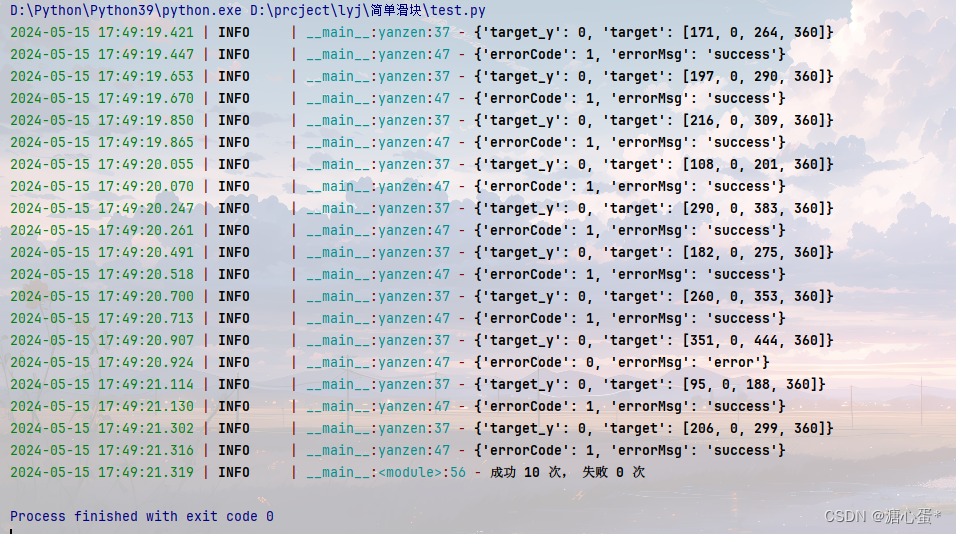
反爬-简单滑块思路,秒了~
文章目录 找图片的返回包curl 大法获取图片链接ddddocr分析距离看结果秒了~ 本文仅供参考学习,如有侵权,请联系作者删。 目标地址:aHR0cHM6Ly9pZHMuZ2RpdC5lZHUuY24vYXV0aHNlcnZlci9sb2dpbj9zZXJ2aWNlPWh0dHBzOi8vd2JkdC5nZGl0LmVkdS5jbi9zaGlyby1jYXM= 触发条件:输

有了这个,网页反爬限制请求频率易如反掌!
这是「进击的Coder」的第 548 篇技术分享 作者:kingname 来源:未闻 Code “ 阅读本文大概需要 6 分钟。 ” 在以前的文章里面,我给大家介绍了使用 Python 自带的 LRU 缓存实现带有过期时间的缓存:实现有过期时间的 LRU 缓存。也讲过倒排索引:使用倒排索引极速提高字符串搜索效率。但这些代码对初学者来说比较难,写起来可能会出错。 实际上,这些功能其实都可以使用
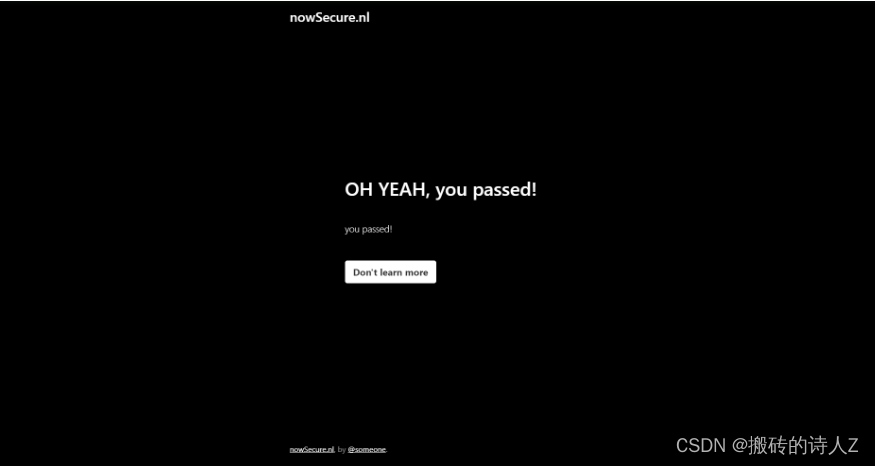
开源推荐榜【绕过反爬检测的 Python 库】
绕过反爬检测的 Python 库 undetected-chromedriver 是一个针对 Selenium 的 Chromedriver 优化补丁,它旨在避免触发诸如 Distill Network、Imperva、DataDome、Botprotect.io 等反机器人服务。该项目能够自动下载驱动程序二进制文件并对其进行补丁处理。 开源地址:添加链接描述 支持的浏览器 经过测试



3--简单的几种反爬方式
1、user-Agent: 请求载体的身份标识 2、Referer: 防盗链(这次的请求是从哪个页面来的?) 3、Cookie: 本地字符串数据信息(用户登录信息,反爬的token) 一、处理cookie # session可以认为是一连串的请求,在这个过程中cookie不会丢# 会话session = requests.session() 1、17k小说网模拟用户登录 数据没
爬虫中遇到的js反爬技术
现在的网页代码搞得越来越复杂,除了使用vue等前端框架让开发变得容易外,主要就是为了防爬虫,所以写爬虫下的功夫就越来越多。攻和防在互相厮杀中结下孽缘却又相互提升着彼此。 本文就JS反爬虫的策略展开讨论,看看这中间都有着怎样的方法破解。 一 、JS写cookie 我们要写爬虫抓某个网页里面的数据,无非是打开网页,看看源代码,如果html里面有我们要的数据,那就简单了。用requests
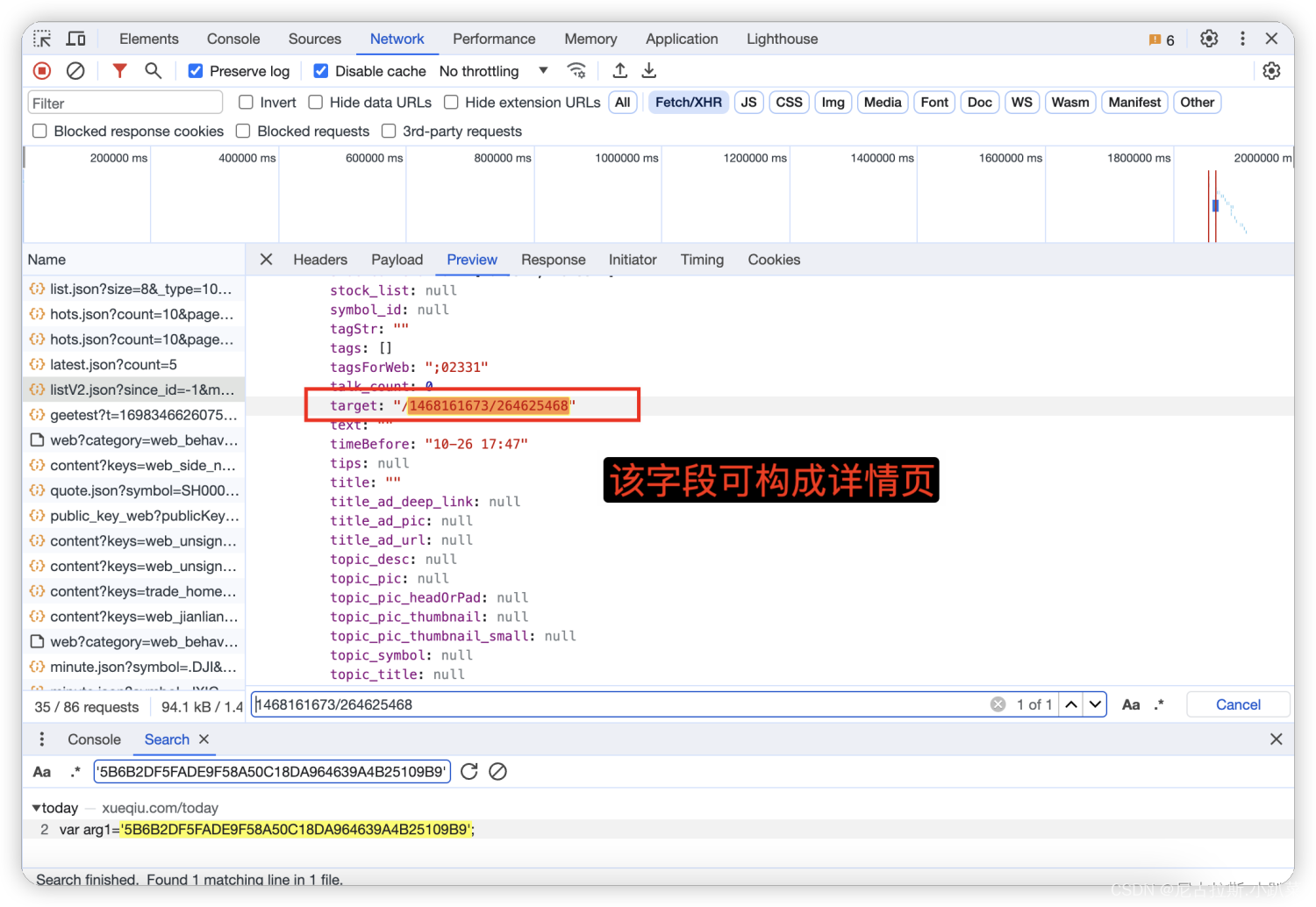
cookie反爬实战案例四(acw_sc__v2 + 无限debugger处理)
文章目录 一、需求 获取雪球热帖数据 二、目标网址 aHR0cHM6Ly94dWVxaXUuY29tL3RvZGF5Iy8= 三、详细步骤 1、确定数据接口 2、验证反爬并找到反爬参数 3、确定cookie反爬参数 import requestsheaders = {"Accept": "*/*","Accept-Language": "zh-CN,zh;

反爬研究---时间戳防盗链技术
文章目录 1. 时间戳防盗链1.1 时间戳防盗链原理1.2 时间戳防盗链鉴权过程(七牛云)1.3 时间戳防盗链处理方案(无CDN) 2. referer防盗链2.1 防盗链2.2 使用场景2.3 访问链接来源2.4 防盗链过滤器处理 3. 防盗链其他方案4. 参考文档 1. 时间戳防盗链 1.1 时间戳防盗链原理 时间戳防盗链的目的是使得每个请求的 url 都具有一定的 “时

爬虫反爬:JS逆向之实战3
1. 简介 从上面两节实战中已经可以做一个属于自己的翻译应用了,甚至可以对翻译结果进行对比然后通过一些语意软件进行优化,这里的所有的DEMO都只是为了学习JS逆向这些技能的过程,今天这节是关于某东登陆参数的逆向,只是为了巩固调试技巧,在实际操作上也不能直接登陆,因为还有一个滑块验证,这个后期再学习。 2. 实战信息 网址: aHR0cHM6Ly9wYXNzcG9ydC5qZC5jb20vbm
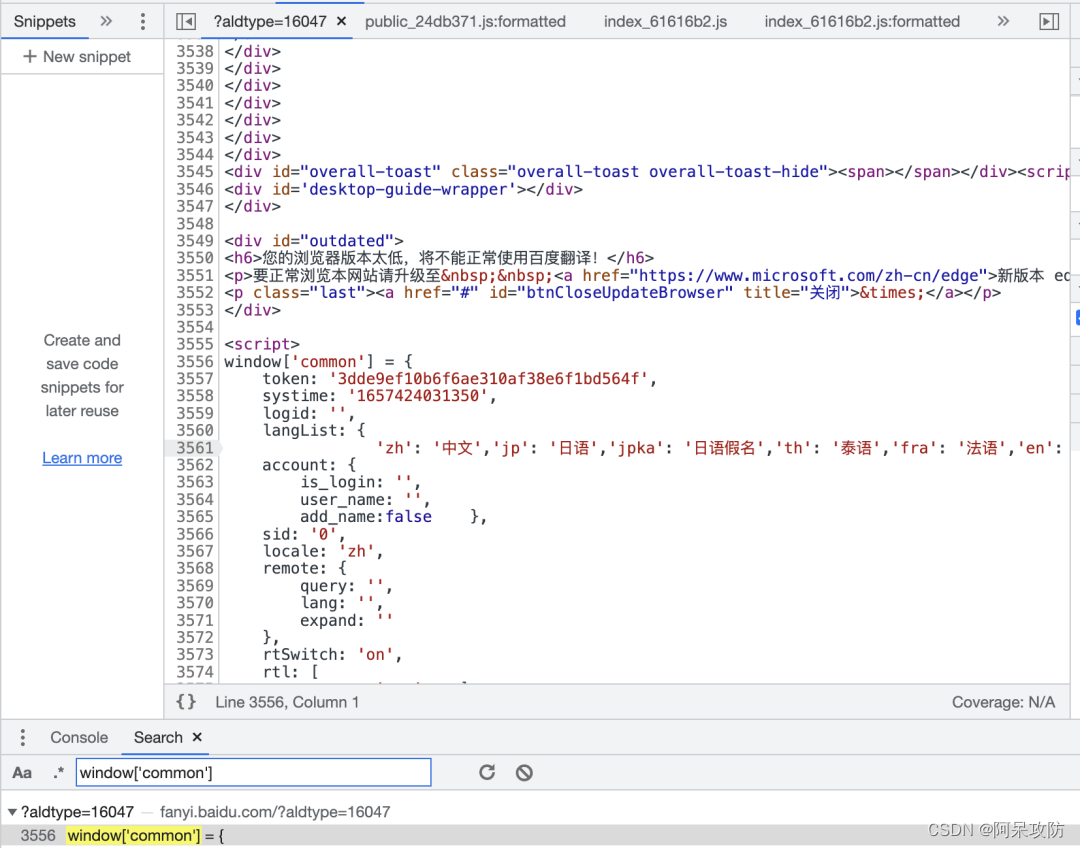
爬虫反爬:JS逆向实战练习1
1. 简介 快速优雅地学会JS逆向,就需要从实战开始,接下来我会提供Base64加密的原网址以及接口参数,从实战中学习如何下断点、抠代码、本地运行等操作,此技术一般用于爬虫上,是一个爬虫程序猿进阶的必经之路。 2. 实战信息 网址: aHR0cHM6Ly9mYW55aS5iYWlkdS5jb20vP2FsZHR5cGU9MTYwNDcjYXV0by96aA== 接口: aHR0cHM6Ly9

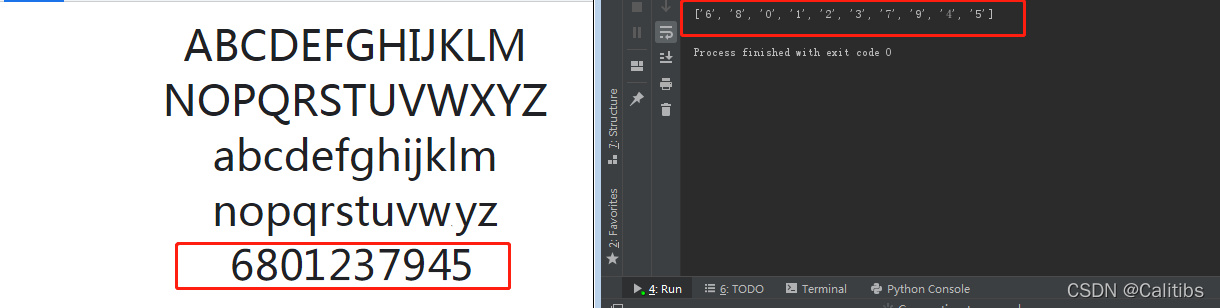
字体反爬破解学习--爬取实习僧
一、前言 这几天搜索一些反爬虫资料时又发现了一种字体反爬的方式。所谓字体反爬,就是一些关键数据你在网页上观看时他是正常的,而当你在使用浏览器的网页检查时却显示的是一个个的方块,这样我们就无法从网页中将数据正确的爬取下来。下面我们我们就来学习如何去破解字体反爬。 参考文章:1、爬虫与反爬虫 | 土法破解字符映射反爬策略及高频词可视化 2、如何解决爬虫过程中网页中数字解析为方块的问题?

从入门到入土:学习|实例练手|获取裁判决定网|Selenium出击|绕过反爬机制|实现批量下载裁决书|狗头保命|仅用于学习交流|Selenium自动化操作
此博客仅用于记录个人学习进度,学识浅薄,若有错误观点欢迎评论区指出。欢迎各位前来交流。(部分材料来源网络,若有侵权,立即删除) 本人博客所有文章纯属学习之用,不涉及商业利益。不合适引用,自当删除! 若被用于非法行为,与我本人无关 仅用于学习交流,若用于商业行为或违法行为,后果自负 学习|实例练手|获取裁判决定网 情况说明代码分析代码展示运行结果总结 情况说明 最近在学习法律
【原创】python反爬策略--字体反爬(政策网)
字体反爬,也是一种常见的反爬技术,这些网站采用了自定义的字体文件,在浏览器上正常显示,但是爬虫抓取下来的数据要么就是乱码,要么就是变成其他字符。下面我们通过其中一种方式解决字体反爬。 1 字体反爬案例 来源网站:查策网_https://www.chacewang.com/chanye/news。 我们可以看到网站展示的时间日期与html中的时间日期不一致,每次刷新网页,html中的时间都会

Python解决反爬机制_滑块解锁的思路以及踩的坑+心得_一蓑烟雨任平生
文章目录 前言目标滑块解锁分三种1.每次验证的第一个图都是定死的2.验证滑块不通过图片不变3.无论你验证成功失败,你拉一次图片位置变一次 一、下载滑块与背景图1.利用canvas标签下载图片(此路不通)2.利用selenium的电脑截图下载图片(此路不通)3.利用selenium的鼠标下载图片(成功) 二、计算滑块到空缺的距离1.第一种方法对比像素(此路不通)2.第二种方法对比滑块和背景(


爬虫进阶-反爬破解9(下游业务如何使用爬取到的数据+数据和文件的存储方式)
一、下游业务如何使用爬取到的数据 (一)常用数据存储方案 1.百万级别数据:单机数据库,搭建和使用方便快捷,成本低 2.千万级别数据:负载均衡的多台数据库,安全和稳定 3.海量数据:大数据框架,分布式部署,承载量巨大 (二)数据库及框架 1.百万级别数据:Mysql、PostgreSQL、Mongo 2.千万级别数据:主从同步数据库,性能调优 3.大数据框架:Hbase、Elast