本文主要是介绍3--简单的几种反爬方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、user-Agent: 请求载体的身份标识
2、Referer: 防盗链(这次的请求是从哪个页面来的?)
3、Cookie: 本地字符串数据信息(用户登录信息,反爬的token)
一、处理cookie
# session可以认为是一连串的请求,在这个过程中cookie不会丢
# 会话
session = requests.session()
1、17k小说网模拟用户登录
数据没有在源代码中,需要js加载
爬取网站 https://user.17k.com/www/bookshelf/
- 登录 -> 得到cookie
- 带着cookie 去请求到书架url -> 书架上的内容
- 必须把上面的内容连接起来
- 我们可以使用session进行请求 -> session可以认为是一连串的请求,在这个过程中的cookie不会丢失
在我们登录自己的账户后看到的内容
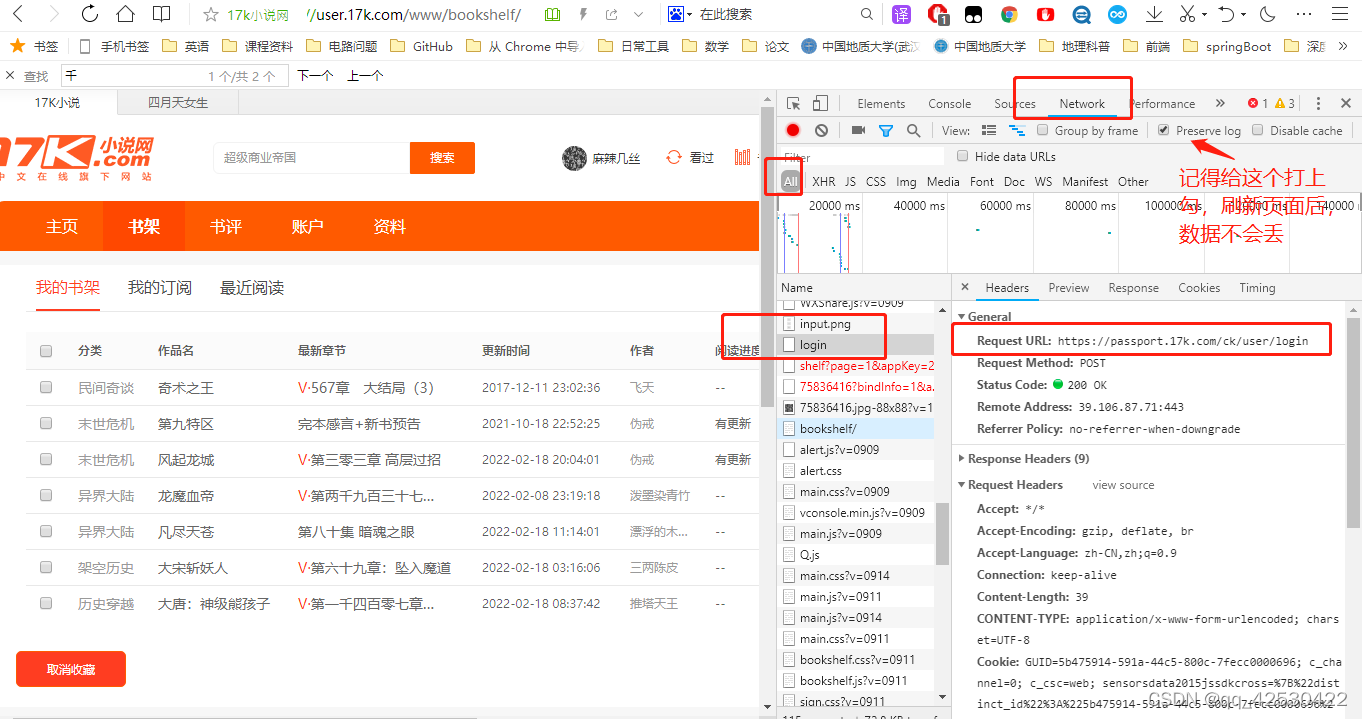

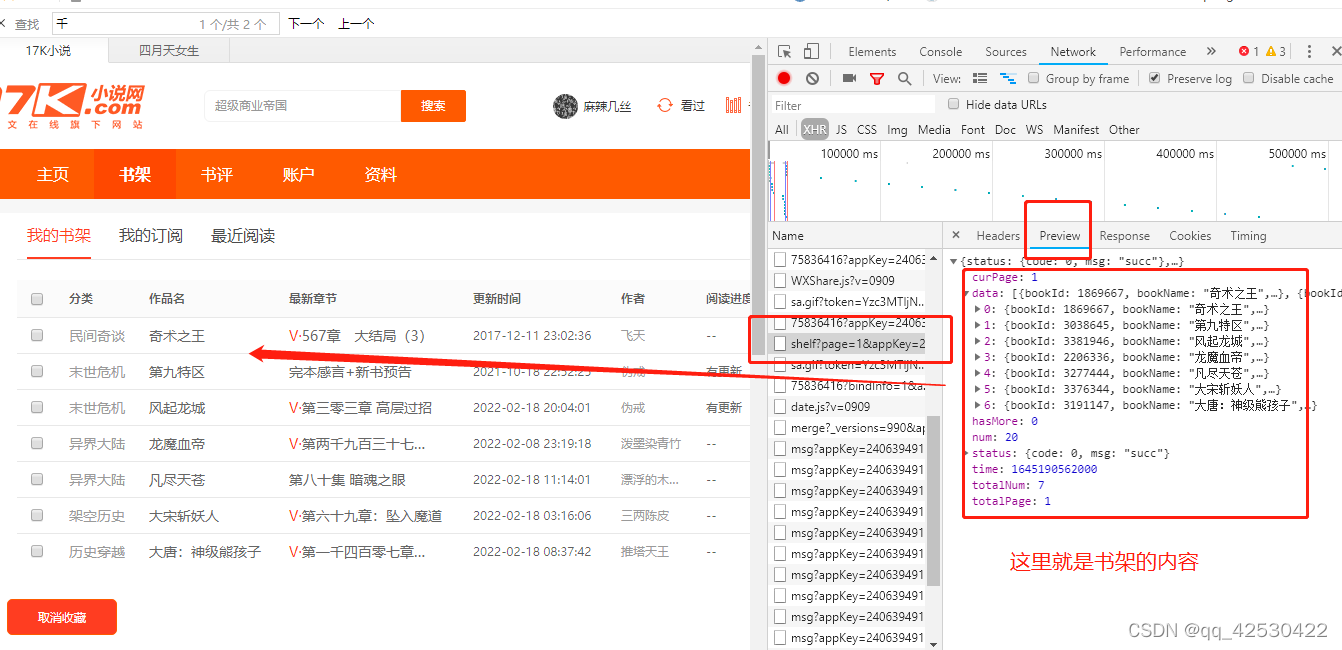
登录之后我们找到书架的书籍内容
import requests
# session可以认为是一连串的请求,在这个过程中cookie不会丢
# 会话
session = requests.session()
data = {"loginName": "你的账户", #你的账户"password": "你的密码" #你的密码
}#1、登录
url = "https://passport.17k.com/ck/user/login"
# resp = session.post(url, data=data)
session.post(url, data=data)
# print(resp.text)
# print(resp.cookies)#2、拿书架上的数据
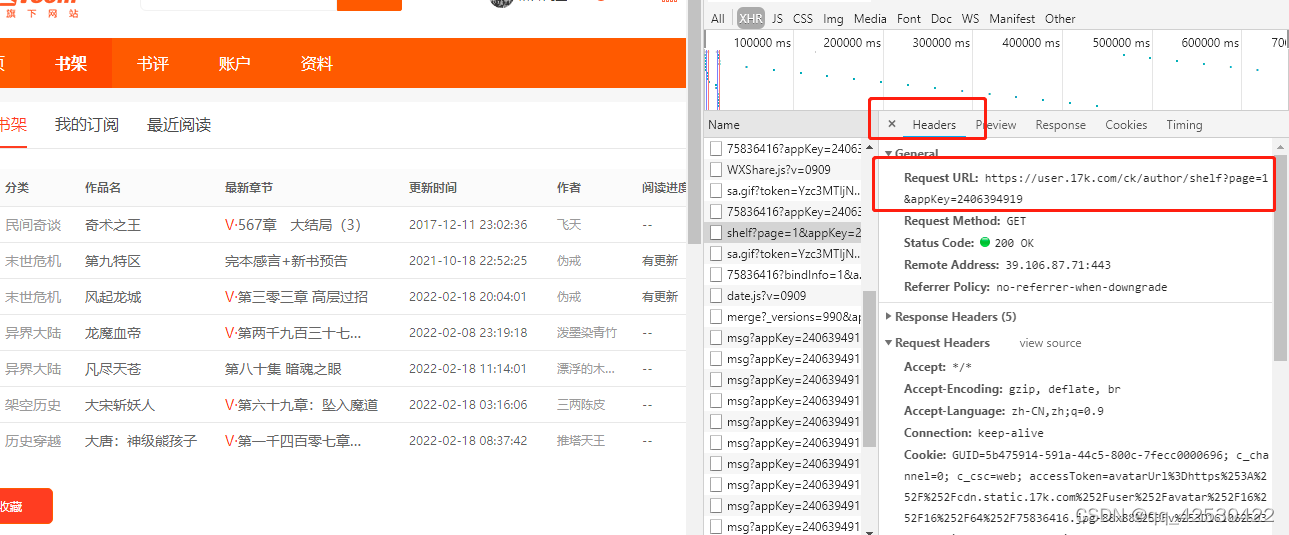
resp = session.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919')
# print(resp.text)
print(resp.json())

二、防盗链Referer的处理
1、梨视频网站视频的下载
爬取网站 https://www.pearvideo.com/
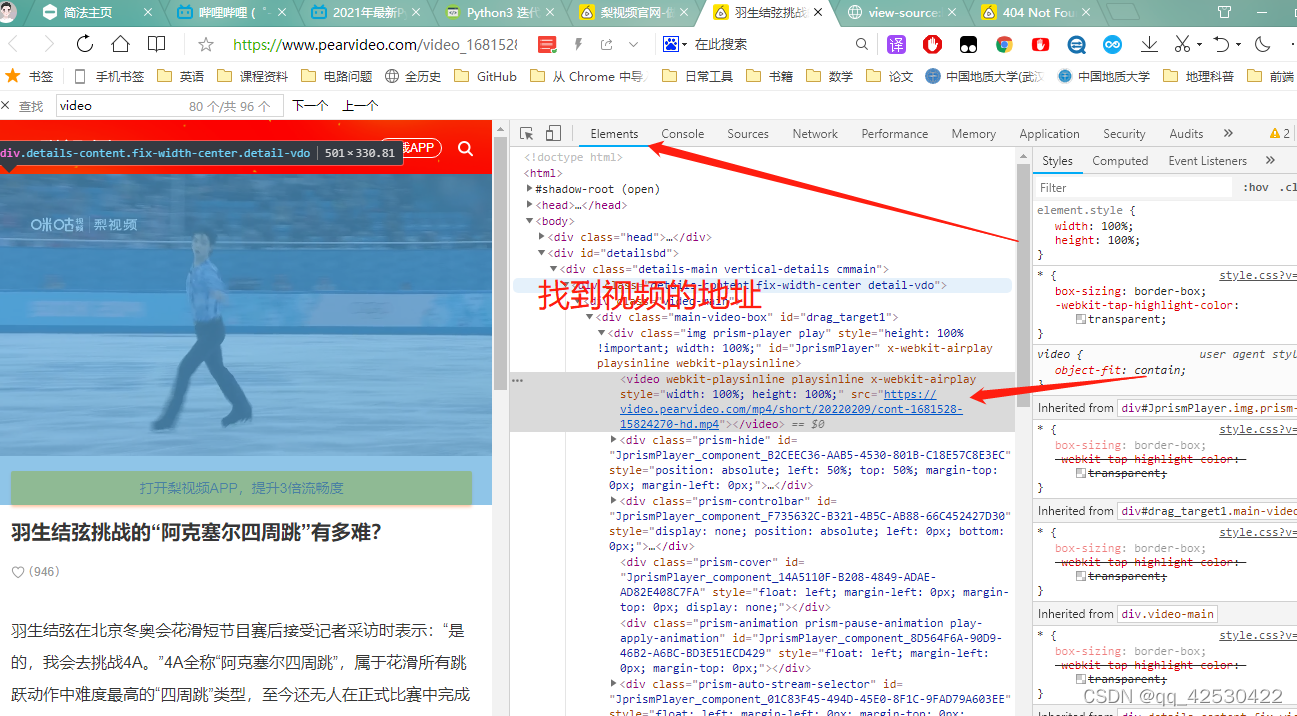
这里的视频地址是可以打开播放的,但是下面的地址是不可以的
提取的视频地址是可以播放的https://video.pearvideo.com/mp4/short/20220209/cont-1681528-15824270-hd.mp4
但是这里的视频地址确实不可以播放的https://video.pearvideo.com/mp4/short/20220209/1644561324854-15824270-hd.mp4
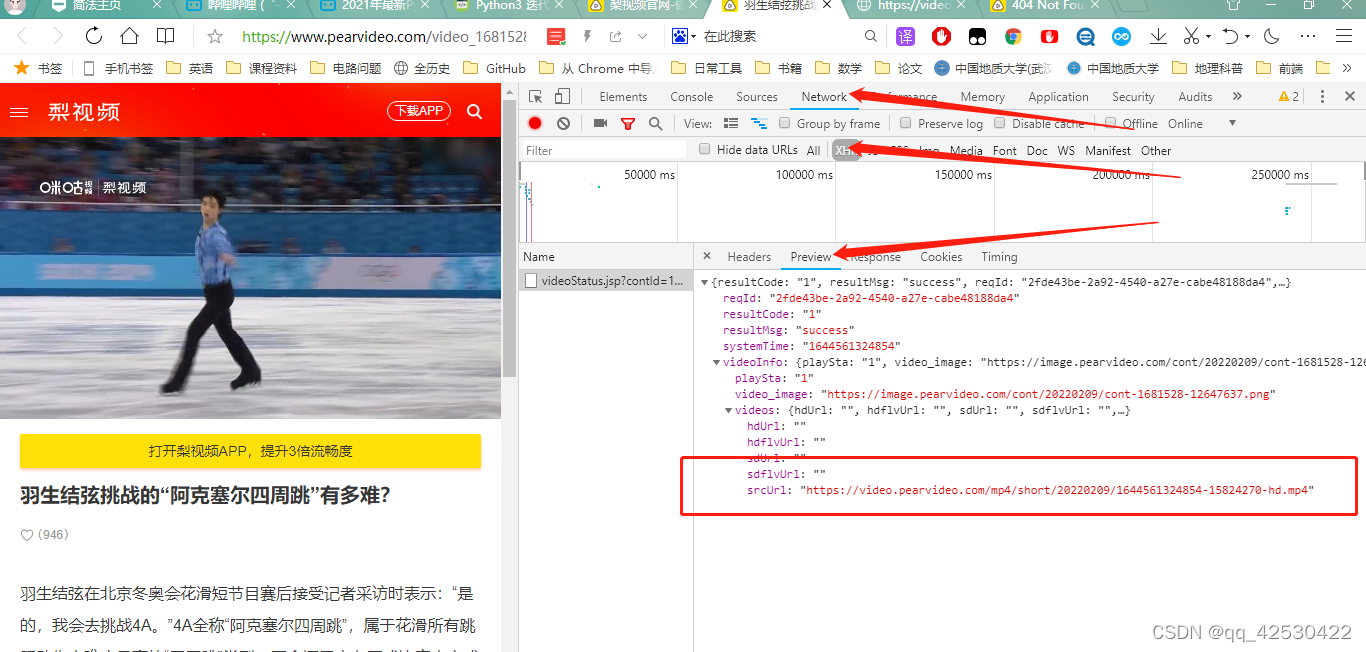
通过比较发现是cont-1681528和1644561324854不一致导致的

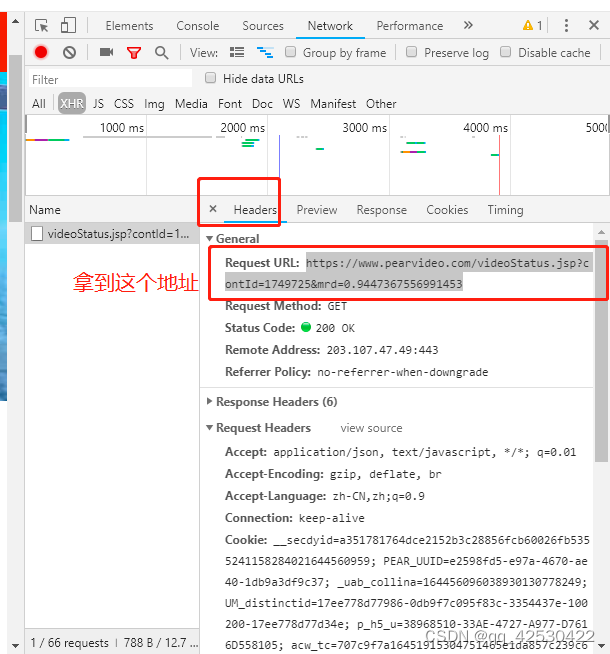

获取地址
resp = requests.get(videoStatusURL, headers=headers)
print(resp.json())
结果为{'resultCode': '1', 'resultMsg': 'success', 'reqId': '6b3d219b-c84a-4c4b-90bb-708fa603cc65', 'systemTime': '1645193588353', 'videoInfo': {'playSta': '1', 'video_image': 'https://image.pearvideo.com/cont/20220209/cont-1681528-12647637.png', 'videos': {'hdUrl': '', 'hdflvUrl': '', 'sdUrl': '', 'sdflvUrl': '', 'srcUrl': 'https://video.pearvideo.com/mp4/short/20220209/1645193588353-15824270-hd.mp4'}}}srcUrl = dic['videoInfo']['videos']['srcUrl'] #拿取到videoInfo中的videos里面的地址srcUrl
print(srcUrl)
结果如下:https://video.pearvideo.com/mp4/short/20220209/1645193588353-15824270-hd.mp4
得到正确视频下载地址
systemTime = dic['systemTime'] #拿取到systemTime的值,值是1645192834127,要把这个值是1645192834127替换为cont-1681528
srcUrl = srcUrl.replace(systemTime, f"cont-{contID}")
全部代码
#1、拿到contID
#2、拿到videoStatus返回的json. -> srcURL
#3、srcURL 里面的内容进行修整
#4、下载视频import requests
url = "https://www.pearvideo.com/video_1681528"
contID = url.split("_")[1]
# print(contID)#要把这个地址里面的内容进行修改
videoStatusURL = f"https://www.pearvideo.com/videoStatus.jsp?contId={contID}&mrd=0.29587422804361174"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3878.400 QQBrowser/10.8.4518.400",# 防盗链"Referer": "https://www.pearvideo.com/video_1681528"
}
resp = requests.get(videoStatusURL, headers=headers)
# print(resp.json())
# resp.json()['videoInfo']['videos']['srcUrl']
dic = resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
# print(srcUrl)
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{contID}")
# print(srcUrl)#下载视频
with open("a.mp4", mode="wb") as f:f.write(requests.get(srcUrl).content)
三、IP代理
import requestsurl = "https://www.baidu.com"
#代理ip
proxies = {"https://": "https://211.136.128.154:53281"
}resp = requests.get(url, proxies=proxies)
resp.encoding = "utf-8"
print(resp.text)
这篇关于3--简单的几种反爬方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







