本文主要是介绍爬虫案例-亚马逊反爬分析(验证码突破)(x-amz-captcha),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
总体概览:核心主要是需要突破该网站的验证码,成功后会返回我们需要的参数后再去请求一个中间页(类似在后台注册一个session),最后需要注意一下 IP 是不能随意切换的
主要难点:
1、梳理整体反爬流程
2、验证码识别
3、IP识别
难度:三颗星(适合小白、初级跟中级学习)
目标网址:aHR0cHM6Ly93d3cuYW1hem9uLmNvbS9kcC9CMENTMjhaTFdT
备注:目前是有两套方案的(1、直接正面突破验证码 2、通过修改指纹来绕过验证码),本文先讲如何直接正面突破验证码,方案2后面有机会再讲
废话不多说,先上流程图
======= 正文开始 =======
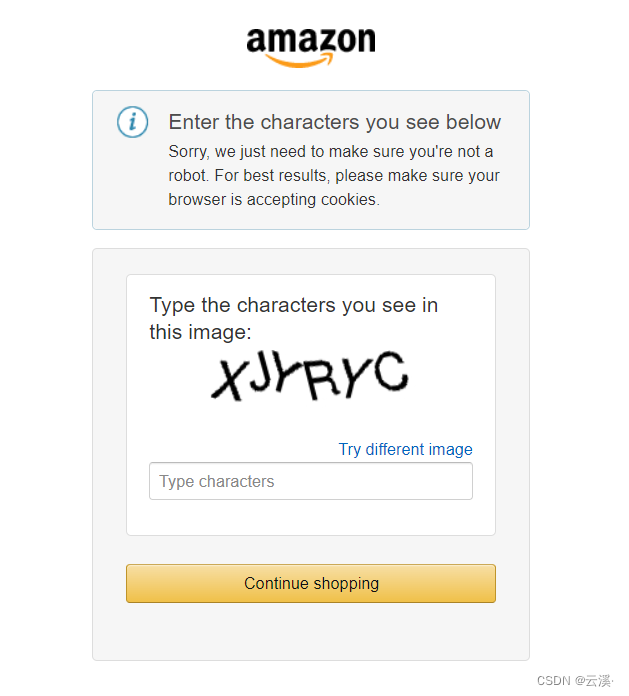
首先打开浏览器自带的无痕模式,输入网址发现直接就弹出验证码了
打开抓包软件,尝试随机输入一个数字,我这里输入的是1,发现是明文,这就简单多了
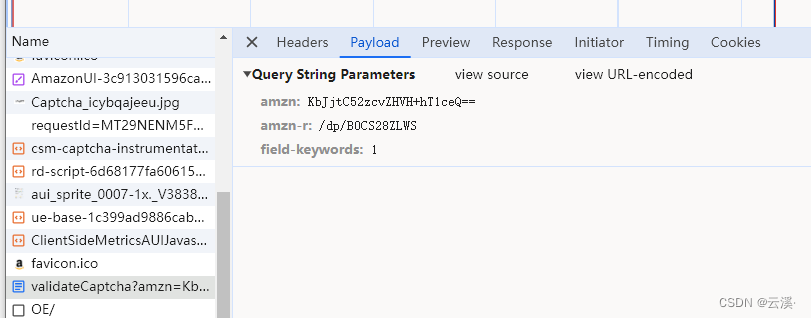
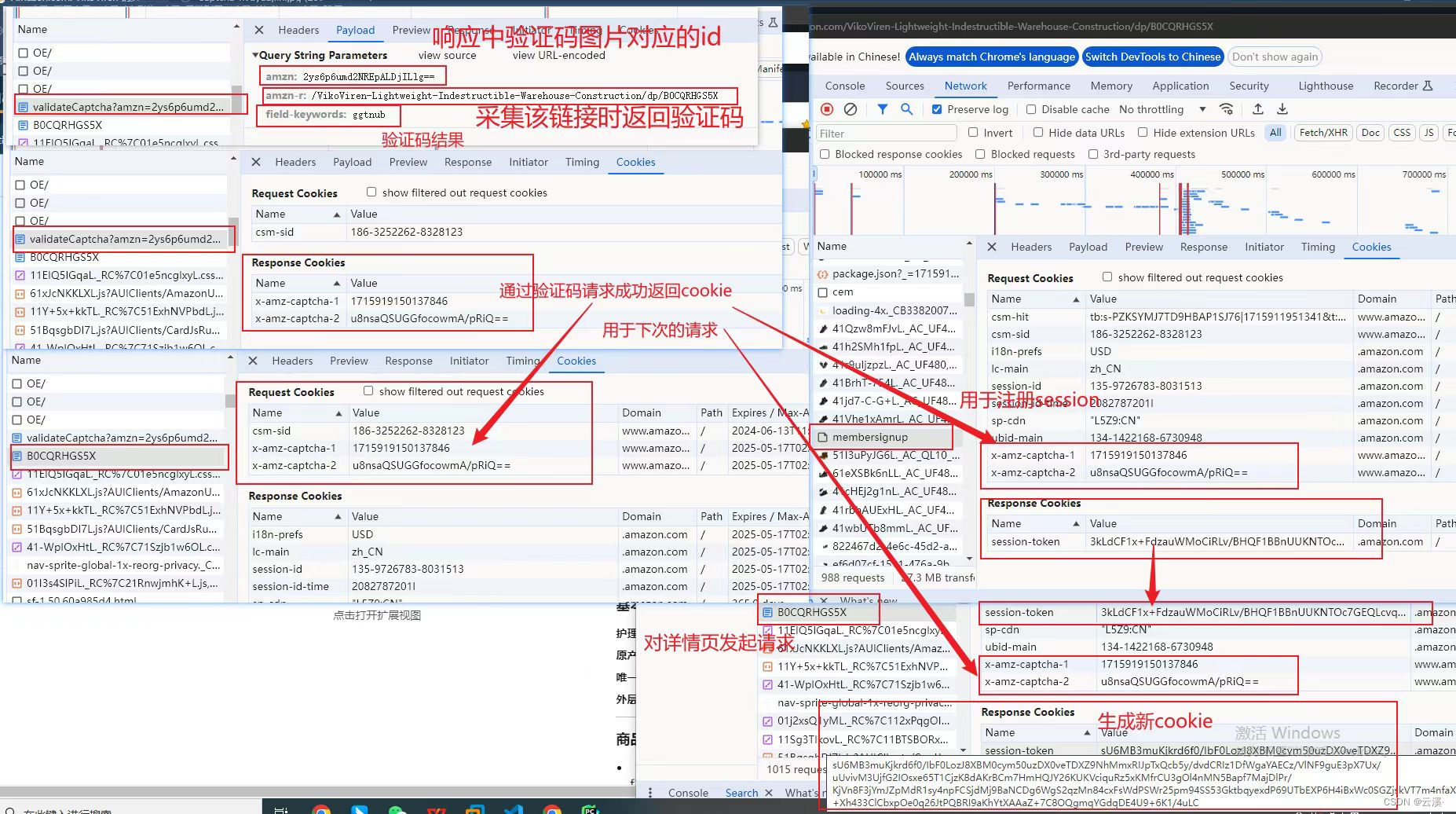
搜索一下 amzn 与 amzn-r 发现这 amzn 很明显的是验证码的标识,field-keywords是我们输入验证码的结果

这次我们再输入正确的验证码:
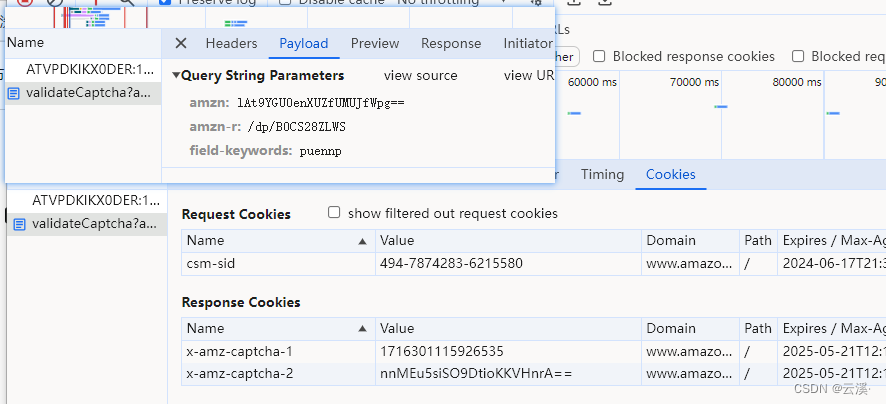
发现对接口https://www.amazon.com/errors/validateCaptcha 进行请求,得到了
x-amz-captcha-1 与 x-amz-captcha-2 两个参数,同时会自动条状到我们最开始输入的那个产品详情页中。
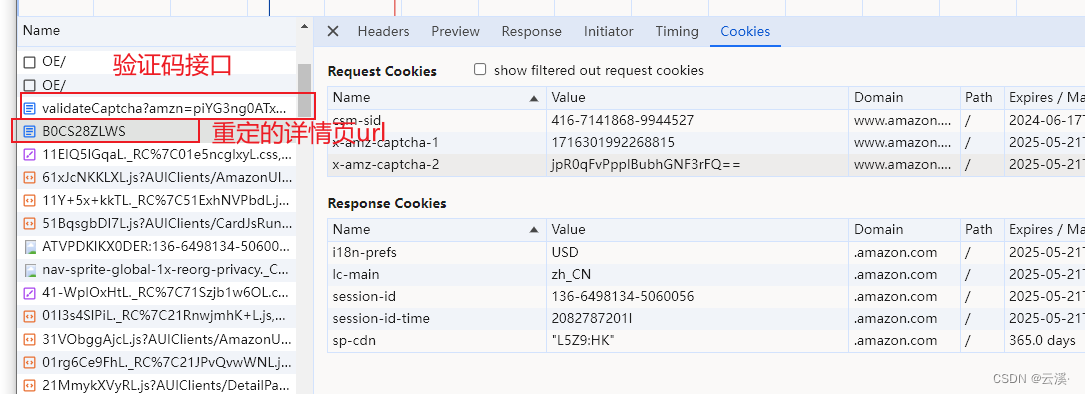
在这个时候发现此时已经生成了大部分的参数了,但经过测试发现缺少 session-token 时,这几个ID很快就会被封掉不能继续使用。
接下来继续观察发现 session-token 在这个位置生成了出来,不难看出这个接口是疑似用来注册session-token 的,这里就是在开头说的请求一个中间页来注册一个session

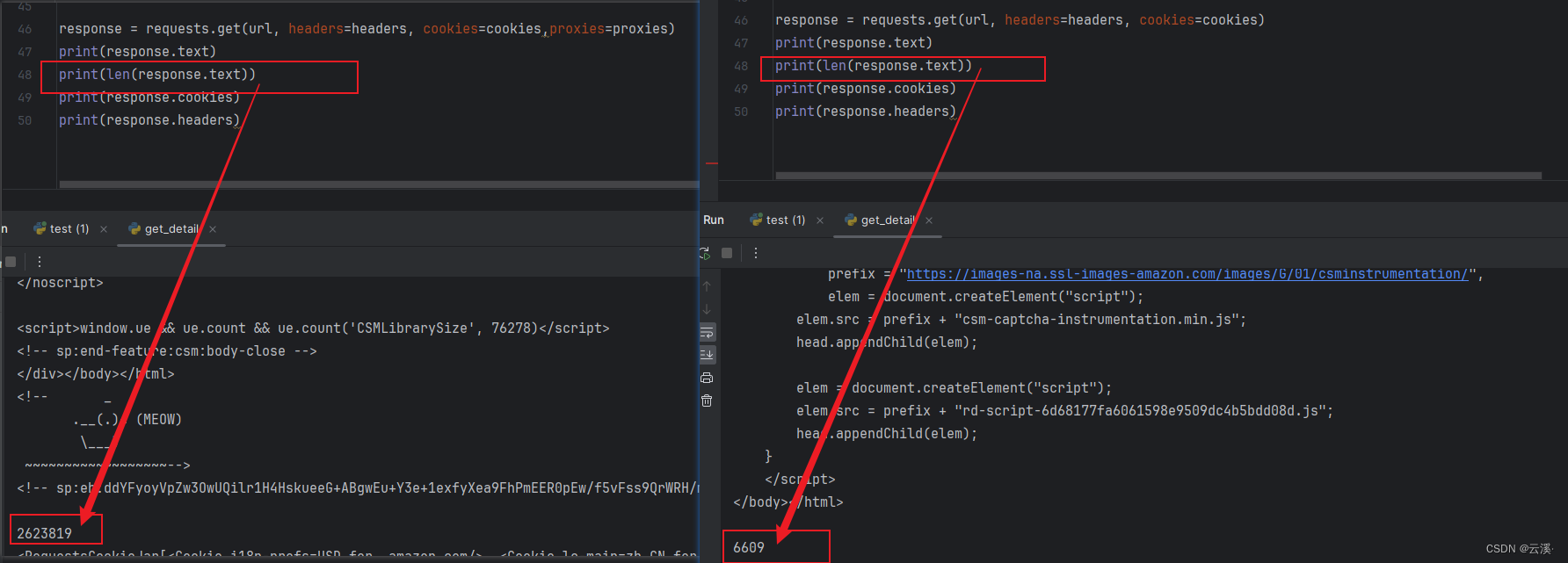
携带这些参数再次请求的时候发现response已经没有cookie返回了,这个时候说明cookie的状态是比较好的,该网站有一个类似Cookie纠错的功能,当cookie没有特别满足他的要求的时候就会返回一些新的参数过来,此时我们只需要更新一下请求就可以了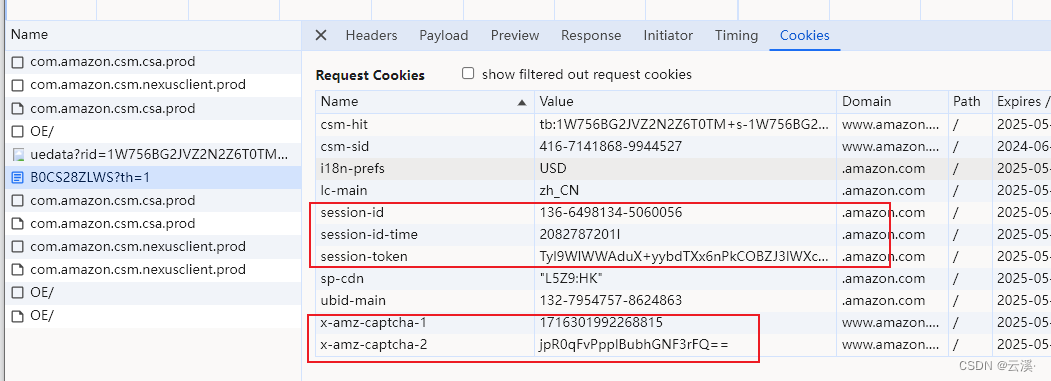
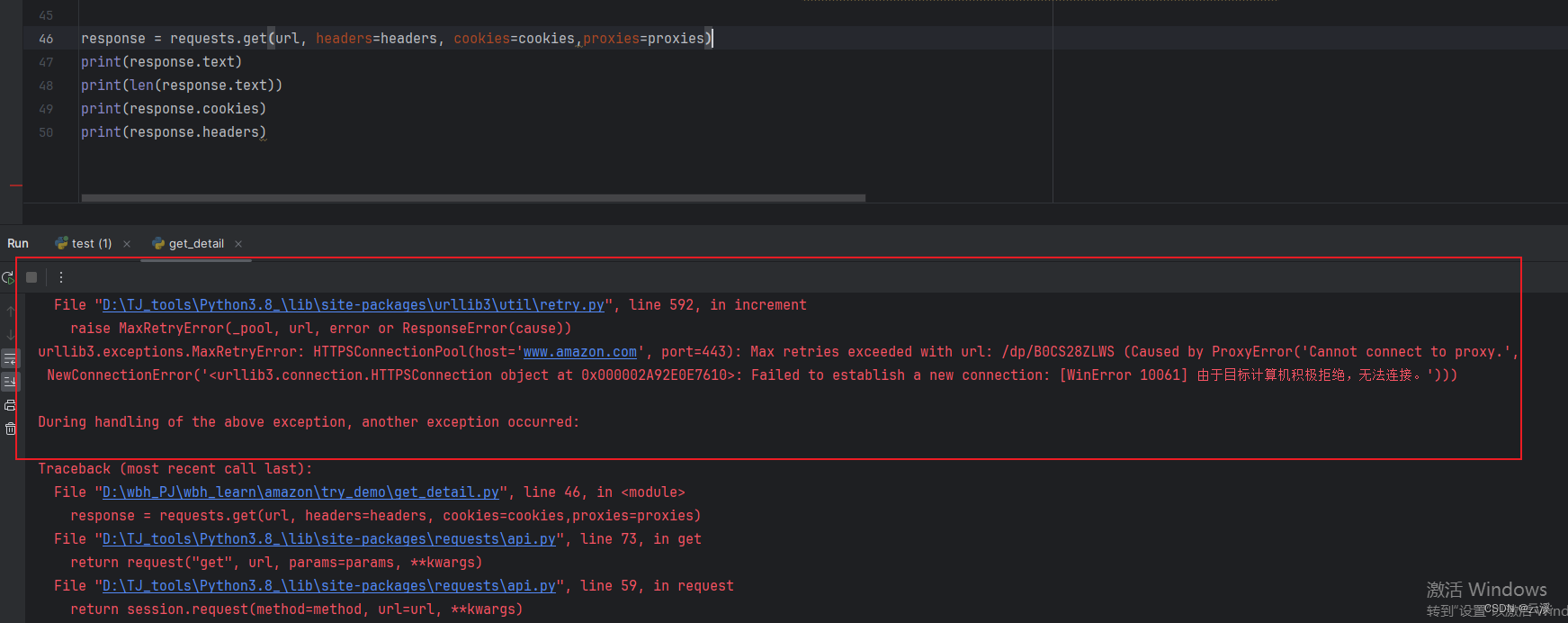
最后需要注意一点就是 IP 是不能随意更换的,在生成x-amz-captcha-1 与 x-amz-captcha-2 这两个参数时的 IP 是绑定的,当IP更换了去请求就会失败,对比一下
同时,当再次使用那个IP时就会出现请求被拒绝,也就是被识别到为爬虫程序,被封禁
验证码识别部分:
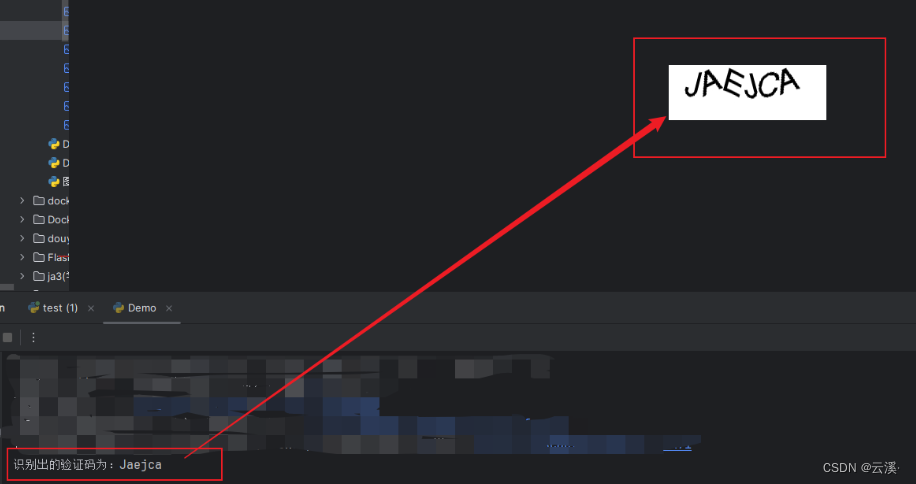
最后还有一个 OE 文件 ,很明显的鼠标轨迹识别,非常有可能在后续会被用于反爬的识别

整体的思路到这基本上就结束了,后续可能会再写一遍如何实现同时实现高并发的稳定爬取该网站
有兴趣,需要源码的可以私聊我
这篇关于爬虫案例-亚马逊反爬分析(验证码突破)(x-amz-captcha)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





