本文主要是介绍大众点评字体反爬,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
脑壳疼了两天 终于搞出来了,大众点评太狗了吧 好几种类型的字体反爬(吐槽一下,求求你们别写反爬了,给我们这些喜欢爬虫的人留点活路吧)有想知道是怎么解决的私聊我,代码就不放了
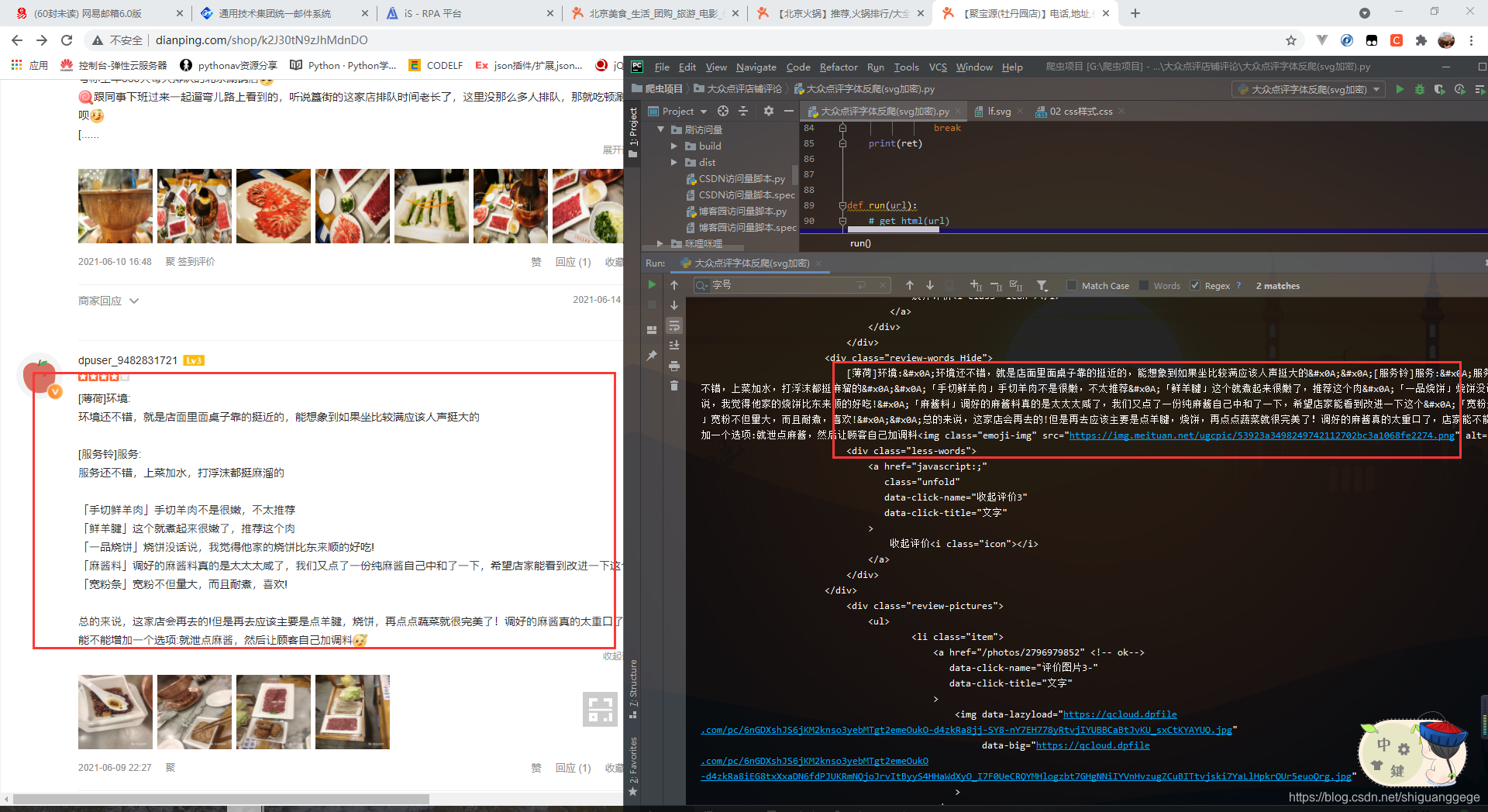
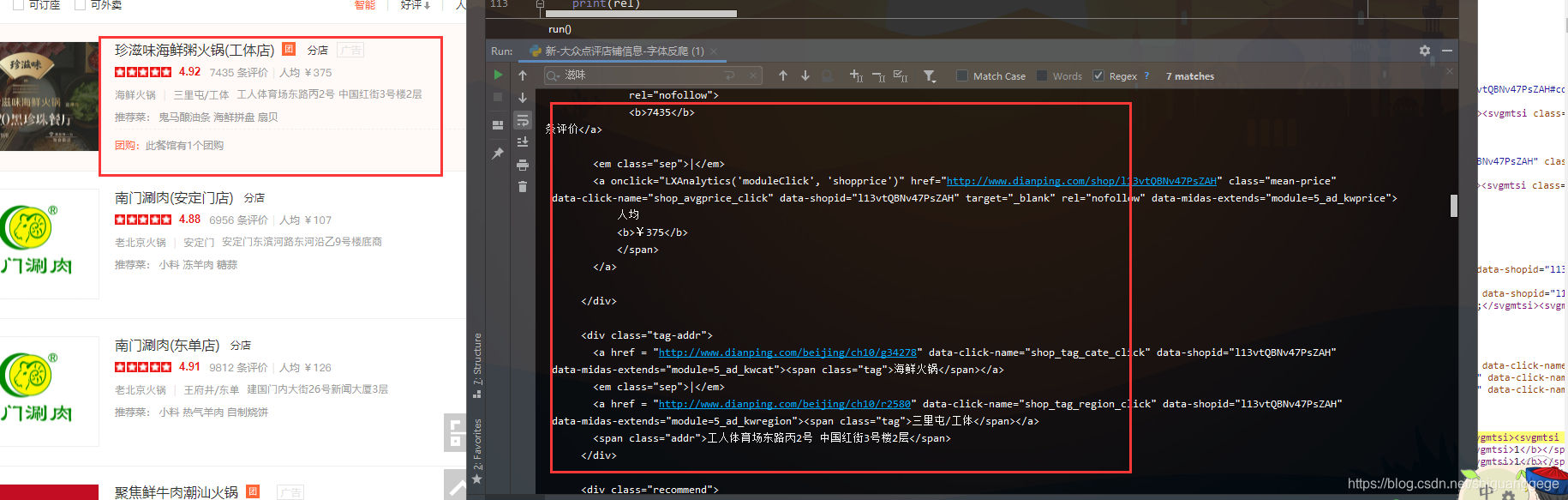
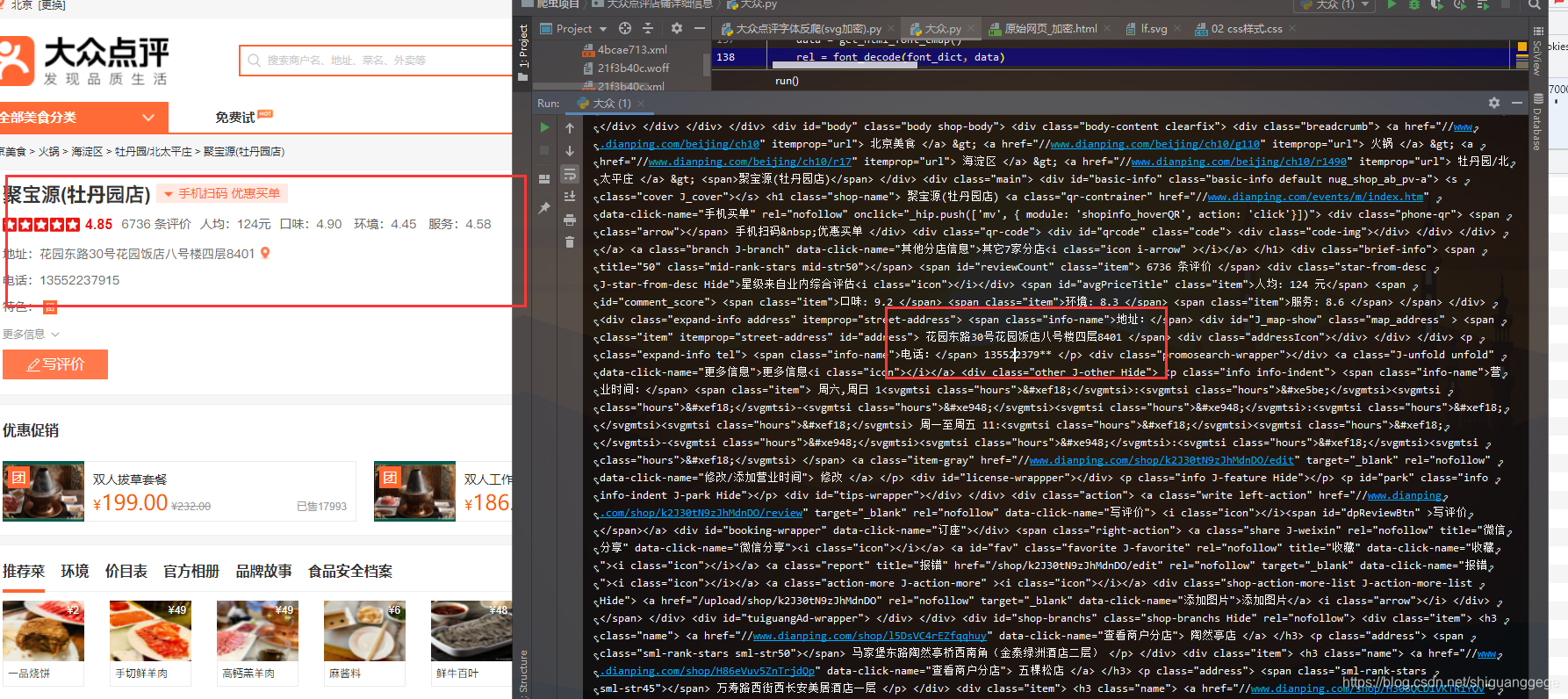
这篇关于大众点评字体反爬的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
本文主要是介绍大众点评字体反爬,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
脑壳疼了两天 终于搞出来了,大众点评太狗了吧 好几种类型的字体反爬(吐槽一下,求求你们别写反爬了,给我们这些喜欢爬虫的人留点活路吧)有想知道是怎么解决的私聊我,代码就不放了
这篇关于大众点评字体反爬的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
http://www.chinasem.cn/article/451192。
23002807@qq.com









