假设专题

java常用算法之返回目标数字在有序数组中的位置(假设有序数组中不存在重复数字)
/*** @Description 返回目标数字在有序数组中的位置(假设有序数组中不存在重复数字)* @param source* @param target* @return*/public static Integer numIndex(int[] source, int target) {int index = 0;if (source == null || source.length =

R语言统计分析——线性模型假设的综合验证与多重共线性
参考资料:R语言实战【第2版】 1、线性模型假设的综合验证 gvlma包中的gvlma()函数,能对线性模型进行综合验真,同时还能做偏斜度、峰度和异方差性的评价。也就是说,它给模型提供了一个单独的综合验证(通过/不通过)。 # 加载gvlma包library(gvlma)# 获取数据states<-as.data.frame(state.x77[,c("Murder",

【PL理论深化】(3) MI 归纳法:归纳假设 (IH) | 结构归纳法 | 归纳假设的证明
💬 写在前面:所有编程语言都是通过归纳法定义的。因此,虽然编程语言本身是有限的,但用该语言编写的程序数量是没有限制的,本章将学习编程语言研究中最基本的归纳法。本章我们继续讲解归纳法,介绍归纳假设和结构性归纳法。 目录 0x00 归纳假设 (IH) 和结构归纳法 0x01 归纳假设的证明 0x00 归纳假设 (IH) 和结构归纳法 归纳法是一种用于证明归纳定义的集合中的元素所具有

gitlab怎么实现将A仓库的新内容推送到B仓库,假设A仓库有1,2文件,B仓库有4,5,6,经过操作后,B仓库有1,2,4,5,6
要求给出两种方法:手动git或者自动化python脚本 文章目录 GPT-4o:手动Git命令实现Python 脚本实现总结 gpt3.5: GPT-4o: 为了将A仓库的新内容(文件1和文件2)推送到B仓库(保留其已有文件4、5、6),可以使用以下步骤: 克隆A仓库到本地临时目录。克隆B仓库到本地临时目录。将A仓库内容复制到B仓库。提交更改并推送到B仓库。 你可以使用以下脚
假设Python脚本包含引用了大量的第三方库,如何打包成.exe文件,并且可以在没有环境的服务器下正常运行
文章目录 1.示例代码说明: 2.如何打包注意事项: 1.示例代码 以下是一个通常用于数据处理、分析和可视化任务的示例脚本: # 引入第三方库import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom scipy import stat
探索Linux中的`aserver`命令(假设命令)
探索Linux中的aserver命令(假设命令) 在Linux生态系统中,有众多的命令和工具可以帮助我们管理、配置和监控我们的系统。然而,aserver并非Linux标准发行版中的一个常见命令。在本文中,我将假设aserver是一个自定义的或者特定于某个应用程序的服务器管理工具,并基于这个假设来探讨其可能的用途和用法。 一、aserver的假设用途 假设aserver是一个用于管理某个应用程

回归现实:无需复杂假设即可轻松评估过程能力的简单方法
Cpk 和 Ppk 等过程能力指标能够测量您的过程相对于客户规格要求的执行情况。我们先回顾一些能力分析基础知识,再深入了解另一个能力估计值 Cnpk,该估计值很可能在您的能力分析库中非常有用。 能力统计指标分析 能力统计指标使用单个数字,是一种无单位指标,用于评估过程能否满足指定要求以及确定需要改进的领域。为此,可以将此常用估计值视为“客户之声”与“过程之声”的比值。 我们可以轻松测量“客户之声
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它 将会被按顺序插入的位置,你可以假设数组中无重复元素.(二分法)
class Solution {public int searchInsert(int[] nums, int target) {int left=0,right=nums.length-1;int mid=-1;while(left<=right){mid=left+(right-left)/2;if(nums[mid]<target){left=mid+1;}else if(nums[m

贝叶斯学习--极大后验假设学习
我们假定学习器考虑的是定义在实例空间X上的有限的假设空间H,任务是学习某个目标概念c:X→{0,1}。如通常那样,假定给予学习器某训练样例序列〈〈x1,d1,〉…〈xm,dm〉〉,其中xi为X中的某实例,di为xi的目标函数值(即di=c(xi))。为简化讨论,假定实例序列〈x1…xm〉是固定不变的,因此训练数据D可被简单地写作目标函数值序列:D=〈d1…dm〉。 基于贝叶斯理论我们可以设计一
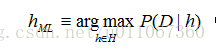
贝叶斯学习--极大后验概率假设和极大似然假设
在机器学习中,通常我们感兴趣的是在给定训练数据D时,确定假设空间H中的最佳假设。 所谓最佳假设,一种办法是把它定义为在给定数据D以及H中不同假设的先验概率的有关知识条件下的最可能(most probable)假设。 贝叶斯理论提供了计算这种可能性的一种直接的方法。更精确地讲,贝叶斯法则提供了一种计算假设概率的方法,它基于假设的先验概率、给定假设下观察到不同数据的概率、以及观察的数据本身。 要

【应用机器学习】评估一个假设
检验是否过拟合 将数据分成训练集和测试集 通常用70%的数据作为训练集,用剩下30%的数据作为测试集。 很重要的一点是训练集和测试集均要含有各种类型的数据,通常我们要对数据进行洗牌,然后再分成训练集和测试集。 使用训练集对模型进行训练 可以得到一系列参数 theta 使用测试集对模型进行测试 使用测试集数据对模型进行测试,有两种方式计算误差 线性回归模型 利用测试集数据计算代

A-CSPO课程概念澄清和实操:假定(Assumptions)、实验(Experiments)、假设(Hypotheses)
“确保你把这当作一个实验。” “我们的工作假设是客户想要这个。” 这些场景熟悉吗?你的团队(或整个组织)可能会经常混淆假定(Assumptions)、实验(Experiments)和假设(Hypotheses)等术语,这会造成混乱。 让我们澄清一下每一个术语的含义。 假定是关于我们认为某个想法的正确性的陈述。以“我们相信……”这样的格式陈述。通常,你的假定集中在一个想法的可能性、可用性、可
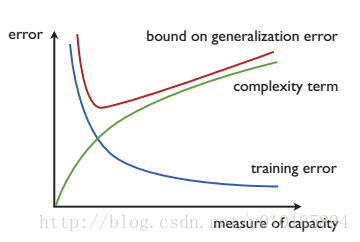
Foundation of Machine Learning 笔记第四部分 —— Generalities 以及对不一致假设集的PAC学习证明
前言 注意事项: 这个系列的文章虽然题为书本《Foundation of Machine Learning》的读书笔记,但实际我是直接对书本的部分内容进行了个人翻译,如果这个行为有不妥当的地方,敬请告知。由于知识面限制,部分名词的翻译可能存在错误,部分难以翻译的名词保留英文原词。为了防止误导大家,在这里声明本文仅供参考。本文基本翻译自《Foundation of Machine Learnin

假设在n进制下,下面的等式成立,n值是() 567*456=150216 9 10 12 18
假设在n进制下,下面的等式成立,n值是() 567*456=150216 9 10 12 18 假设n进制,则有(5*n 2 +6*n+7) * (4*n 2 +5*n+6) = n 5 +5*n 4 +2*n 2 +n+6,简化以后可以得到 15*n4+49*n3+86*n2+70*n+36=n5,两边同时除以n5,可以得到15/n+49/n2+86/n3+70/

非常好的介绍流形假设文章
总觉得即使是“浅谈”两个字,还是让这个标题有些过大了,更何况我自己也才刚刚接触这么一个领域。不过懒得想其他标题了,想起来要扯一下这个话题,也是因为和朋友聊起我自己最近在做的方向。Manifold Learning 或者仅仅 Manifold 本身通常就听起来颇有些深奥的感觉,不过如果并不是想要进行严格的理论推导的话,也可以从许多直观的例子得到一些感性的认识,正好我也就借这个机会来简单地谈一下这个
ChatGPT研究论文提示词集合2-【形成假设、设计研究方法】
点击下方▼▼▼▼链接直达AIPaperPass ! AIPaperPass - AI论文写作指导平台 目录 1.形成假设 2.设计研究方法 3.书籍介绍 AIPaperPass智能论文写作平台 近期小编按照学术论文的流程,精心准备一套学术研究各个流程的提示词集合。总共14个步骤,每天总结两个,最终形成一篇合计分享给宝子们。 宝子们可以使用小编精

请勿假设你的用户都有管理员权限
有些人觉得自己很聪明,他们在程序中做了这样一项”优化”。 在程序的安装阶段,他们不会安装某些程序功能,而是等到用户第一次使用的时候才执行,也即所谓的 “按需加载”。 问题在于,第一次使用的时候,用户可能没有管理员权限,而安装阶段一般都要求管理员权限。 举个例子,有一个流行的多媒体软件,用户在第一次使用的时候,才会安装 CD AutoPlay 处理器,如果此时用户没有管理员权限,则处理器将不会

让模型训练速度提升2到4倍,「彩票假设」作者的这个全新PyTorch库火了
来源:机器之心本文约3000字,建议阅读10分钟本文介绍了MosaicML 推出了一个用于高效神经网络训练的 PyTorch 库「Composer」。 登陆 GitHub 以来,这个项目已经收获了 800 多个 Star。 随着越来越多的企业转向人工智能来完成各种各样的任务,企业很快发现,训练人工智能模型是昂贵的、困难的和耗时的。 一家公司 MosaicML 的目标正是找到一种新的方法来应

NLP05_noisy channel model、语言模型、马尔科夫假设
给定一个source,转换成text 通过贝叶斯定理,得到如下的公式 都是将一个信号来转换成文本信息 机器翻译:英译中 根据贝叶斯定理, P(英文|中文)表示的是翻译模型, 指的是中文对应的英文翻译,这个是提供好的,通过翻译模型得到的是英到中的对照翻译,不考虑语法 P(中文)表示语言模型,用他来保证翻译的语法正确。 拼接纠错 P(错误|正确)可以表示编辑距离,也就是正确的 和错误的差异 P

机器学习---假设的评估问题
机器学习的假设理论:任一假设若在足够大的训练样例集中很好的逼近目标函数,它也能在未见实例中很好地逼近目标函数。 伯努利分布的期望 np 方差 np(1-p) 训练样例(Sample)的错误率:errors 测试数据(data)的错误率:errorD 评估偏差 bias=E(errors)-errorD 对于无偏估计(bias=0):h和S选择必须独立 评估方差: 对于无偏的评估S
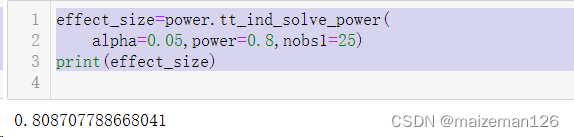
python统计分析——假设概念、错误、p值和样本量
参考资料:python统计分析【托马斯】 1、例子 假设你在经营一家私立教育机构,你的合同显示:如果全国平均水平时100分时,你的学生在期末考试中得了110分,你就能获得奖金;若结果明显降低,你就会失去奖金。 学生得分数据如下:109.4,76.2,128.7,93.7,85.6,117.7,117.2,87.3,100.3,55.1 图像展示如下: # 导入库# 用于
人工智能数学验证工具LEAN4【入门介绍9】高级乘法世界:逆否策略的等效替代,提取假设 的已知,tauto另类理解,更 严格的归纳法假设。。。
视频讲解:人工智能数学验证工具LEAN4【入门介绍9】高级乘法世界:逆否策略的等效替代,提取假设 的已知,tauto另类理解,更 严格的归纳法假设。。。_哔哩哔哩_bilibili import Game.Levels.AdvMultiplication.L08mul_eq_zero World "AdvMultiplication" Level 9 Title "mul_left_can

贝叶斯定理与条件独立假设:朴素贝叶斯分类方法深度解读
今天给大家分享的是朴素贝叶斯算法,这个算法在实际使用中不是很多,因为现在很多算法已经发展的很好,性能上也比朴素贝叶斯算法的好很多,因此在实际中我们其实看到在实际应用中朴素贝叶斯算法的使用已经比较少,即使出现,最终的效果也是不及其他算法的,但是作为简单、基础的算法之一,我们掌握该算法的原理还是非常有必要的,同时在实际论文研究中也经常会使用贝叶斯算法的改进版,所以大家可以多了解了解。 朴素贝叶斯算法