本文主要是介绍NLP05_noisy channel model、语言模型、马尔科夫假设,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
给定一个source,转换成text
通过贝叶斯定理,得到如下的公式
都是将一个信号来转换成文本信息
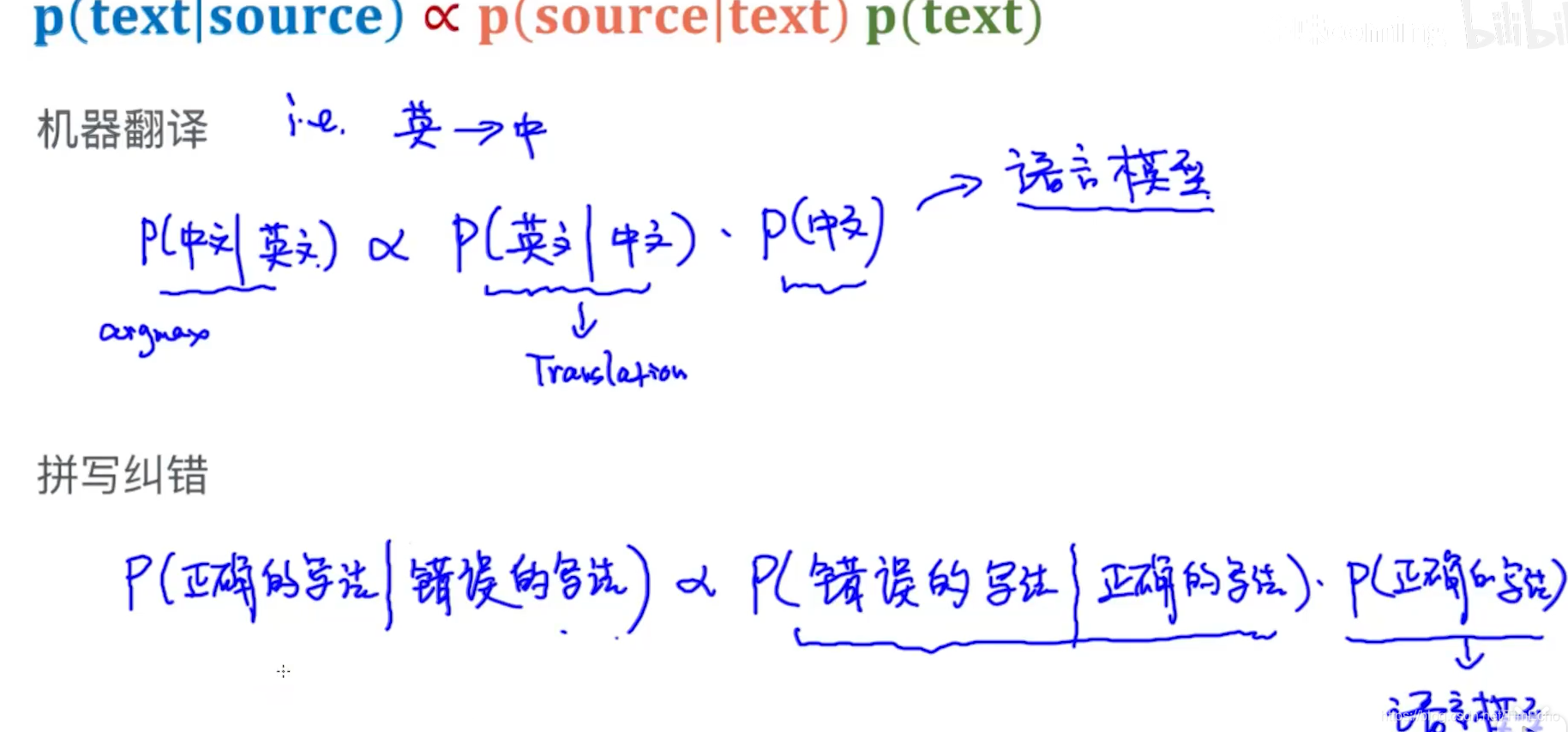
机器翻译:英译中
根据贝叶斯定理,
P(英文|中文)表示的是翻译模型, 指的是中文对应的英文翻译,这个是提供好的,通过翻译模型得到的是英到中的对照翻译,不考虑语法
P(中文)表示语言模型,用他来保证翻译的语法正确。
拼接纠错
P(错误|正确)可以表示编辑距离,也就是正确的 和错误的差异
P(正确)来保证语法的正确,也就是语言模型
语音识别
P(语言|给定文本)即翻译,将文本翻译成语音
P(文本)保证语法正确
密码破解

上边这些事例,都是左边控制翻译,右边保证语法正确
这就是noisy channel model

任何将信号转换成文本,都可以转换成Noisy channel model
语言模型
语言模型来保证句子语法上的通顺
通过预训练好的语言模型,来判断一个句子是否符合语法,最后给出句子符合语法的一个概率,选择出概率最大的那个句子

Chain relu
基本的条件概率公式得来

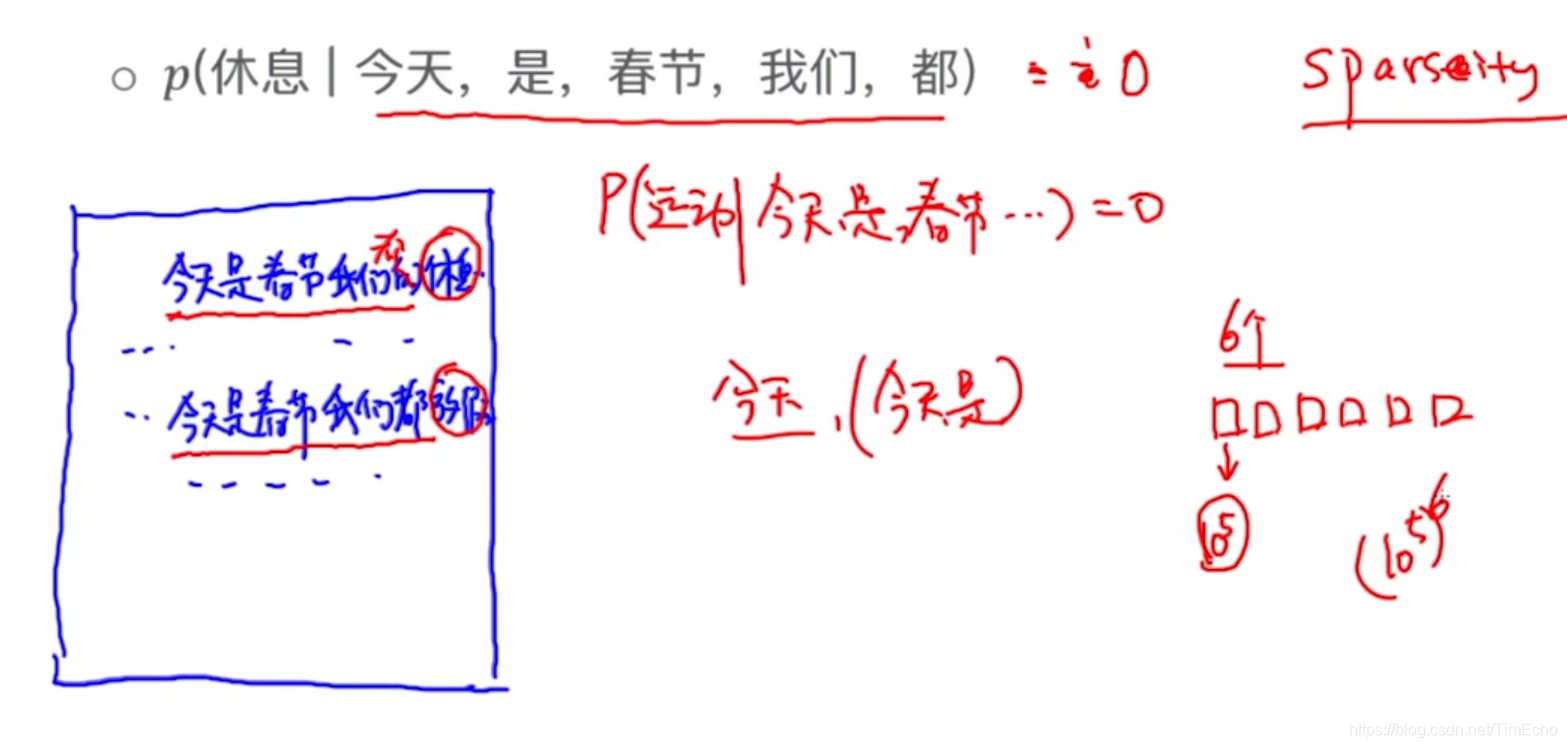
算这个概率,就是统计“今天是春节我们都“这个句子在文中出现的次数,接着长句后跟着“休息”的有一个句子,那概率就是1/2
但是这只是理想情况,大部分的长句子在文中可能都找不到,所以概率都是0
这就产生了稀疏性问题
解决稀疏性问题的办法
马尔科夫假设Markov Assumption
通过马尔科夫假设来估计概率
概率的近似,只将当前词的前几个词作为条件

更通用写法

假如已训练好语言模型,概率都知道,使用1st order计算概率

根据每一个马尔科夫假设,有一个对应的语言模型
Unigram
当每一个词都不依赖其他词时,也就是每一个单词都当成独立事件看,就得到Unigram LM, 最简单的LM
Unigram的缺陷:不考虑单词的顺序,语法注意不到

Bigram LM 对应 1st order markov assumption
可以考虑到词的先后顺序

类推
N-gram
当n > 2时,就成为higher order LM
n = 3已经是一个复杂的LM了

Bigram用到的是最多的
这篇关于NLP05_noisy channel model、语言模型、马尔科夫假设的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







