本文主要是介绍Foundation of Machine Learning 笔记第四部分 —— Generalities 以及对不一致假设集的PAC学习证明,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
注意事项:
- 这个系列的文章虽然题为书本《Foundation of Machine Learning》的读书笔记,但实际我是直接对书本的部分内容进行了个人翻译,如果这个行为有不妥当的地方,敬请告知。
- 由于知识面限制,部分名词的翻译可能存在错误,部分难以翻译的名词保留英文原词。为了防止误导大家,在这里声明本文仅供参考。
- 本文基本翻译自《Foundation of Machine Learning》的2.4节。
正文
在这一部分中,我们将讨论几个与学习相关的重要问题,在前些章节中我们为了便于理解而忽略了。
2.4.1 确定性与随机性
在监督学习的大多数情况下,分布 D D 定义在空间 ,训练数据是一个按照 D D 独立同分布地抽取的一个带标签样本集 :
在这种场景下,PAC 学习框架自然地拓展出一个新的概念:不可知的 PAC 学习 ( agnostic PAC-learning )。
定义 2.4 不可知 PAC 学习
设 H H 为一个假设集。如果存在一个多项式函数 ,使得对于任意 ϵ>0 ϵ > 0 、任意 δ>0 δ > 0 和所有在空间 × X × Y 上的分布 D D ,下式在任意样本量 的样本集上成立:
当一个点上的标签能够被一个可观测函数 f:→ f : X → Y 唯一地确定的时候,这种场景称为确定性场景 ( deterministic scenario )。在这种情况下,考虑只在输入空间 X 上的分布 D 就足够了。这样,根据 D 抽取 (x1,…,xm) ( x 1 , … , x m ) ,通过对 i∈[1,m] i ∈ [ 1 , m ] 使用函数 f:yi=f(xi) f : y i = f ( x i ) 获取标签,就能得到训练集。很多学习问题都可以被形式化为这种决定性场景。
在前面几个部分中,为了简便我们都只讨论了确定性场景下的学习问题。但是从这些确定性场景拓展到随机场景的方法还是比较直白的(我的理解:随机性场景和前面假设集不一致的情况是不一样的)。
2.4.2 贝叶斯错误率和噪声
在确定性场景的情况下,存在一个没有泛化误差的目标函数 f f 使得:。在随机情况下,存在一个泛化误差大于 0 但最小的假设。
定义 2.5 贝叶斯错误率
给定一个在空间 × X × Y 上的分布 D D , 贝叶斯错误率 被定义为可观测函数 h:→ h : X → Y 的泛化误差的下确界:
通过定义可以知道,在确定性场景的情况下,我们有 ,但是在随机性场景的情况下, R∗≠0 R ∗ ≠ 0 。显然,贝叶斯分类器 hBayes h B a y e s 可以使用条件概率定义为 ( 我的疑问:那么如何证明下式的泛化误差是所有分类器的泛化误差的下确界?):
定义 2.6 噪声
给定一个在空间 × X × Y 上的分布 D D ,点 上的噪声定义为
因此,平均噪声就是前述的贝叶斯错误率: noise=E[noise(x)]=R∗ n o i s e = E [ n o i s e ( x ) ] = R ∗ 。噪声是一个衡量学习任务难度的特征。对于一个点 x∈ x ∈ X ,如果他的噪声 noise(x) n o i s e ( x ) 接近于 1/2,常常称 x x 为噪点 ( noisy )。噪点是预测的一个挑战。
2.4.3 估计误差和近似误差
假设集 的泛化误差和贝叶斯误差的差可以分解成 :
(2.25) ( 2.25 ) 的第一项是估计误差,它由被选择的假设 h h 确定。它描述了假设 与 best-in-class 假设的接近程度。不可知PAC学习的定义也是基于估计误差的。算法 A 的估计误差,也就是算法在样本集 S S 上训练后返回的假设 的估计误差,有时被限制小于某个由泛化误差决定的项。
例如,用 hERMS h S ERM 代表经验风险最小化算法——也就是返回经验误差最小的假设 hERMS h S ERM 的一种算法——返回的假设。那么,上一节中定理2.2给出的泛化上限,或者任意其他在 suph∈H∣∣R(h)−R̂ (h)∣∣ s u p h ∈ H | R ( h ) − R ^ ( h ) | 上的限制,都能被用来限制经验风险最小化算法的估计误差。实际上,通过重写估计误差的计算公式使得公式中出现 R̂ (hERMS) R ^ ( h S ERM ) ,并且通过定义得到不等式 R̂ (hERMS)≤R̂ (h∗) R ^ ( h S ERM ) ≤ R ^ ( h ∗ ) ,我们可以写出
(2.26) ( 2.26 ) 的右侧可以通过定理 2.2 限制上限,并且假设集增大而上升, R(h∗) R ( h ∗ ) 随 |H| | H | 上升而下降,这个上限值也上升。
2.4.4 模型选择
基于前几节的理论结果,在这里我们讨论一些模型选择方法和算法思想。我们假设大小为 m m 的样本集 的生成是服从独立同分布的,并使用 R̂ S(h) R ^ S ( h ) 代表假设 h h 在 上的误差,以便清除地表示它与 S S 的依赖关系。
虽然定理 2.2 给出的保证只对有限的假设集成立,它已经为我们提供了一些在算法设计上的指导,我们将在下一章中提出,类似的保证在假设集无限的情况下同样存在。这样的结果促使我们对经验误差和复杂度项进行思考,在这里复杂度项是一个关于 和样本量 m m 的一个函数。
从这一点出发,一个只寻求取最小化训练集上的误差的算法,ERM算法
另一种被称为结构风险最小化 ( structural risk minimization, SRM ) 方法从一个有着逐渐增大的样本量的无穷的假设集序列
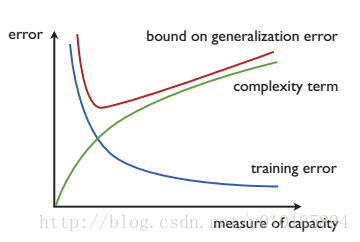
图为结构风险最小化示意图。三种误差被画成了假设集大小的函数。显然,随着假设集大小的上升,训练误差下降,同时复杂度上升。SRM 通过最小化训练误差和复杂度之和,选择使得泛化误差的上限最低的那个假设。
虽然 SRM 从较强的理论保证中受到益处,它的计算往往十分复杂,因为它需要取解多个 ERM 问题的解。注意 ERM 问题的个数不是无限的,因为随着 n n 的增大,假设集 的训练误差变为0,这时因为训练误差不变了,而复杂度项还在不断上升,那么目标函数一定会不断上升,以后后面的假设集就都不用考虑了。
还有另一种基于更加直白的优化策略的算法,这种方法的优化目标函数为经验误差和正则项的和,这个正则项对复杂的假设进行了惩罚。当 H H 是一个向量空间的时候,正则项通常被定义为 的某种范数 ||h||2 | | h | | 2 通常正则项被定义为某种:
我的补充
在《Foundation of Machine Learning》的这一节中,作者给出了一个新的定义——不可知 PAC 学习,并且分析了一种更加难的学习问题——随机场景下的学习问题——的误差构成,最后从 PAC 理论作为指导讲述了经验风险最小化和结构风险最小化两种学习模型的原理。
我在阅读书本到这部分的时候,对一些概念的关系的理解比较混乱,于是还查阅了一些其他资料。下面的把查阅到的资料整合起来,企图把这里的体系补充得更加完整。
上文说到随机场景的学习问题这个概念,我们可以把随机场景这类问题纳入到不一致的学习问题当中。把不一致的假设集总结为以下三种:
- 目标 concept ;
- c∈H c ∈ H , 但是要从 H H 中找出 是一个难以计算的问题;
- c c 不存在。(也就是上文所说的随机情况。我们总是假设存在一个目标 concept 把样本投影到标签中去,但现实中并不总是这样。例如天气预报就没有一个确定的结果,而是给出出现各种天气的概率。我们认为这些问题都是固有随机性的,或者说,这些问题太过复杂以至于以我们现有的知识不能够为它们建立模型。)
显然,上一节的不一致假设学习问题属于第 1, 2 种,这一节引入的随机场景属于第 3 种。
如上文所说的一样,为了研究随机场景下的学习问题,我们引入一种新的形式化方法。我们统一把分布 定义在空间 × X × Y 中。根据条件概率公式,对于一个样本,我们可以给出:
Pr[(x,y)]=PrD[x]⋅PrD[y|x]. P r [ ( x , y ) ] = P r D [ x ] ⋅ P r D [ y | x ] .我们可以这么理解分布 D D 的样本生成过程,首先按照概率 生成样本点,然后由于这一个样本点有可能属于两个或多个标签,那么它就应该还有一个决定样本 x x 属于什么标签的概率分布 。我们把这种设定下的学习问题的泛化误差定义为:R(h)=E(x,y)∼D[1h(x)≠y]. R ( h ) = E ( x , y ) ∼ D [ 1 h ( x ) ≠ y ] .经验误差可以定义为:R̂ (h)=1m∑i=1m1h(xi)≠yi. R ^ ( h ) = 1 m ∑ i = 1 m 1 h ( x i ) ≠ y i .我们定义泛化误差最小的分类器为贝叶斯分类器,不知如何得证,下式所示的分类器就是贝叶斯分类器:∀x∈,hBayes(x)=argmaxy∈{0,1} Pr[y|x]. ∀ x ∈ X , h B a y e s ( x ) = arg max y ∈ { 0 , 1 } P r [ y | x ] .要注意的是,上面的式子同样可以用到确定的情况下,只是 PrD[y|x] P r D [ y | x ] 被限定为 0 或者 1。所以前一节所说的确定场景下假设集不一致问题同样可以使用这里的方法表达,此时贝叶斯误差 R∗=0 R ∗ = 0 。
由于上一节的定理 2.2 只用到了 Hoeffding 不等式和 Union Bound 进行证明,而改变分布 D D 的形式对它们不会造成影响,所以定理 2.2 同样适用在这种设定下的学习问题上。设 是一个有限的假设集,那么对于任意 δ>0 δ > 0 ,下面的不等式至少有 1−δ 1 − δ 的几率成立:
∀h∈H,R(h)≤R̂ (h)+log|H|+log2δ2m‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√. ∀ h ∈ H , R ( h ) ≤ R ^ ( h ) + log | H | + log 2 δ 2 m .定理
对于一个有限不一致的假设集 H H ,一个从 中学习到的经验误差最小的假设 hS=argminh∈HR̂ (h) h S = arg min h ∈ H R ^ ( h ) ,和任意的 0<δ<1 0 < δ < 1 ,下式有 1−δ 1 − δ 的概率成立:
R(hS)≤2log|H|+log2δ2m‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√+minh∈HR(h). R ( h S ) ≤ 2 log | H | + log 2 δ 2 m + min h ∈ H R ( h ) .也就是说,学习问题满足不可知 PAC 学习。证明 因为定理 2.2 成立,由定理 2.2 的推导过程可得对于任意 ϵ>0 ϵ > 0 :
Pr[∃h∈H,|R̂ (h)−R(h)|>ϵ]≤ 2|H|e−2mϵ2. P r [ ∃ h ∈ H , | R ^ ( h ) − R ( h ) | > ϵ ] ≤ 2 | H | e − 2 m ϵ 2 .取反则有:Pr[∀h∈H,|R̂ (h)−R(h)|≤ϵ]≥ 1−2|H|e−2mϵ2. P r [ ∀ h ∈ H , | R ^ ( h ) − R ( h ) | ≤ ϵ ] ≥ 1 − 2 | H | e − 2 m ϵ 2 .若 ∀h∈H, |R̂ (h)−R(h)|≤ϵ ∀ h ∈ H , | R ^ ( h ) − R ( h ) | ≤ ϵ 成立,有:∀h∈H, R(hS)≤≤≤R̂ (hS)+ϵR̂ (h)+ϵR(h)+2ϵ.(3)(4)(5) (3) ∀ h ∈ H , R ( h S ) ≤ R ^ ( h S ) + ϵ (4) ≤ R ^ ( h ) + ϵ (5) ≤ R ( h ) + 2 ϵ .其中因为 R(h)−R̂ (h)≤ϵ R ( h ) − R ^ ( h ) ≤ ϵ 对所有 h h 成立,第一个不等式成立;因为 ,第二个不等式成立;因为 R̂ (h)−R(h)≤ϵ R ^ ( h ) − R ( h ) ≤ ϵ 对所有 h h 成立,第三个不等式成立。设 ,解 ϵ ϵ ,定理得证。参考
- jeremykun 的博客 Occam’s Razor and PAC-learning
- Princeton Computer Science 511
Theoretical Machine Learning 的 scribe note 0225
这篇关于Foundation of Machine Learning 笔记第四部分 —— Generalities 以及对不一致假设集的PAC学习证明的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








