yolov4专题

darknet/YOLOV4 预训练时冻结参数,停止反向传播
目录 1.首先获取预训练模型 2.修改cfg文件 3.训练 平时我们在训练模型时,会利用预训练模型做迁移学习,但是有时候我们想前面的几层直接复用预训练模型的参数,然后只训练后面的几个网络层,这时候需要冻结前面几层的参数,停止反向传播。 1.首先获取预训练模型 darknet partial cfg/cspdarknet53.cfg cspdarknet53.weights cspd
yolov4训练自己的数据集,基于darknet框架
目录 一:安装darknet 二:首先以VOC的数据格式准备好自己的数据 三:制作darknet需要的label以及txt文件。 四:准备data文件 五:准备names文件 六:修改cfg文件 七:开始训练 八:单张图片测试 一:安装darknet git clone https://github.com/AlexeyAB/darknet/ 修改makefile里面的值

【YOLOV4】FPN+PAN结构
yolo4的neck结构采用该模式,我们将Neck部分用立体图画出来,更直观的看下两部分之间是如何通过FPN结构融合的。 如图所示,FPN是自顶向下的,将高层特征通过上采样和低层特征做融合得到进行预测的特征图。Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。 和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。这样结合操

c++项目中使用YOLOv4模型简单案例
主要是使用yolo_v2_class.hpp文件 1、hpp文件 #ifndef DEMO_HPP#define DEMO_HPP#ifndef OPENCV#define OPENCV#endif#include<yolo_v2_class.hpp>#include<darknet.h>using namespace cv;using namespace std;class

基于YoloV4汽车多目标跟踪计数
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 一、项目背景与意义 随着城市交通的快速发展,交通流量和车辆密度的不断增加,对交通管理和控制提出了更高的要求。传统的交通流量计数方法通常依赖于人工统计或者简单的传感器设备,这些方法不仅效率低下,而且容易出错。因此,开发一个能够自动、准确地

使用YoloV4深度学习对图像上的车辆进行检测计数
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 三、系统四. 总结 一项目简介 一、项目背景与意义 随着智能交通系统(ITS)的快速发展,对道路监控视频中车辆进行准确、实时的检测与计数已成为一项重要的技术需求。传统的车辆检测方法往往依赖于人工或简单的图像处理技术,这些方法不仅效率低下,而且容易受到环境、光照、遮挡等因素的影
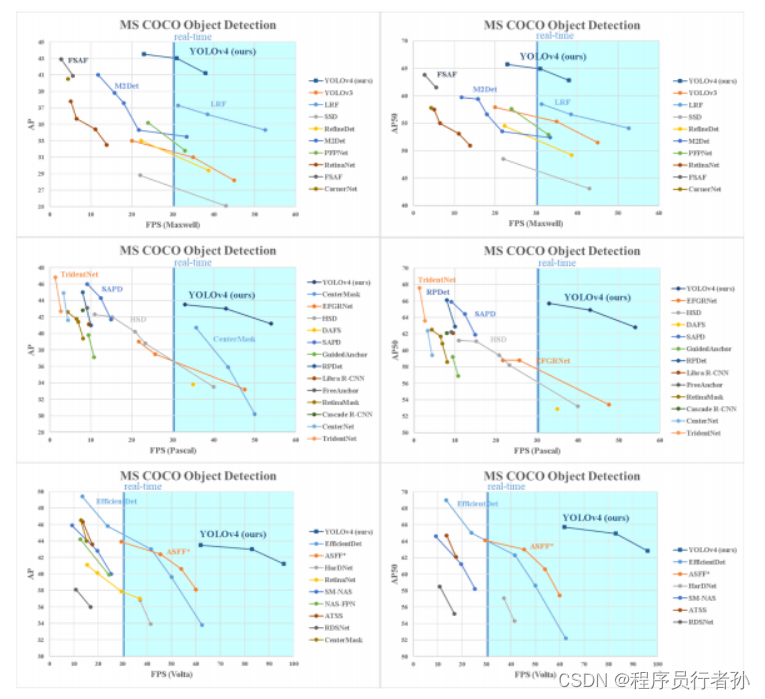
YOLOv4重磅发布,五大改进,二十多项技巧实验,堪称最强目标检测万花筒
点击上方蓝色字体,关注我们 今年2月22日,知名的 DarkNet 和 YOLO 系列作者 Joseph Redmon 宣布退出 CV 界面,这也就意味着 YOLOv3 不会再有官方更新了。但是,CV 领域进步的浪潮仍在滚滚向前,仍然有人在继续优化 YOLOv3。今日,著名的AlexeyAB版本发布了 YOLOv4的论文。该论文提出了五大改进,二十多个技巧的实验,可以说 YOLOv4是一项非
YOLOV4目标检测--计数方法draw_detections_v3
YOLOv4检测图片添加置信度和计数 YOLOv4检测图片添加置信度和计数 本文章向大家介绍 YOLOv4检测图片添加置信度和计数 ,主要包括 YOLOv4检测图片添加置信度和计数 使用实例、应用技巧、基本知识点总结和需要注意事项,具有一定的参考价值,需要的朋友可以参考一下。 主要修改的image.c文件,在darknet目录下直接ctrl+f搜即可,然后打开,找到draw_d
【万字长文】看完这篇yolov4详解,那算是真会了
前言 目标检测作为计算机视觉领域的一个核心任务,其目的是识别出图像中所有感兴趣的目标,并给出它们的类别和位置。YOLO(You Only Look Once)系列模型因其检测速度快、性能优异而成为该领域的明星。随着YOLOv4的推出,目标检测的性能得到了进一步的提升。本文将详细介绍YOLOv4相对于前代YOLO模型的改进点,以及它在目标检测领域的新贡献。 YOLO系列概述 YOLO系列自20
Ubuntu18.04 搭建YOLOV4环境
Darknet是一个轻型的深度学习和训练框架,从这一点上,它和tensorflow以及pytorch这种没有什么不同,特点在轻型二字,它主要对卷集神经网络进行了底层实现,并且主要用于YOLO的目标检测,特点主要有: C语言实现没有依赖项,除了opencv进行视频和UVC摄像头处理容易安装,可移植性好支持CPU于GPU(CUDA)两种计算方式 下面开始实验。 下载代码,编译 git clo

【目标检测】YOLOv7 网络结构(与 YOLOv4,YOLOv5 对比)
YOLOv7 和 YOLOv4 Neck 与 Head 结构对比 其实 YOLOv7 的网络结构网上很多文章已经讲得很清除了,网络结构图也有非常多的版本可供选择,因为 YOLOv7 和 YOLOv4 是一个团队的作品,所以在网络结构方面, YOLOv7 和 YOLOv4 有很多相似的地方,下面我们就来比较一个 YOLOv7 和 YOLOv4 的 Neck 和 Head 部分: 可以看出来宏

在Unity程序中使用YOLOv4识别物体时报错CvException
在某项目中使用OpenCV for Unity中YOLOv4识别物体,在Unity编辑环境下运行得好好的,发布出来一运行就报错。刚开始以为是显卡原因,换了几台电脑都报错,后来发现是中文路径的问题。 CvException: An error occurred on the C++ side, causing the class initialization to fail.Enclose th
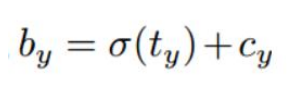
Yolo 一小时吃透 yolov4 yolov5 原理
一小时吃透 yolov4 & yolov5 原理 概述网络结构BOF数据增强马赛克数据增强对抗训练Drop Block BOSSPPNetCSPNetCBAMPANet 损失函数标签平滑IOUGIOUDIOUCIOU对比DIOU-NMSSOFT-NMSMish 激活函数网络敏感性 概述 Yolo 之父 Joe Redmon 在相继发布了 yolov1 (2015) yolov2
00X基于Jetson Nano+yolov4-tiny的目标检测
本节将详细介绍如何在Jetson Nano平台上搭建基于YoloV4-tiny模型的对象检测系统。 说在最前面,本篇文档的许多内容来自多篇技术文档,我只是结合自己的学习经历,进行了加工和组合 1.1 Why Yolo V4-tiny? 在介绍具体内容之前,首先说明为何选用YoloV4-tiny这个模型。其实原因也很简单,就两个。一是该模型是Jetson Nano自带的,不用单独安装了,使

TX2跑YOLOv4代码所需硬件配置
一、尝试安装pycharm所需步骤 安装JDK (1)在https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html, 用户名:qq邮箱 密码:数字+大写字母+小写字母(自己记忆) (2)在安装包所在目录下打开终端 将文件解压到指定地方 sudo mkdir /usr/lib/jvmsudo tar

yolov4_trt
环境: tensorRT5.1.6-1xaviercuda10python2.7 tensorRT简介及原理: tensorRT是由Nvidia推出的一款GPU推理引擎(GIE: GPU Inference Engine)。由于训练好的神经网络权重已经确定,后续使用中无需后向传播以及高精度计算,因此在模型的部署过程中可以通过使用低精度如FP16(16位的float型)来对前向传播过程进行加速
学习笔记(01):Windows版YOLOv4目标检测实战:训练自己的数据集-先验框聚类分析
立即学习:https://edu.csdn.net/course/play/28748/401686?utm_source=blogtoedu Try to set subdivisions=64 in your cfg-file. CUDA status Error: file: G:\AIfile\darknet\src\dark_cuda.c : cuda_make_array() : l

pytorch-YOLOv4训练自己的数据集
题记:之前用YOLOv3训练了自己的数据集,详见该博客,Darknet--Yolov3训练自己的数据。准备试试YOLOv4,试试看校测效果是否再提高,因需要,用的pytorch版本。 一、下载代码 1、下载项目代码 git clone https://github.com/Tianxiaomo/pytorch-YOLOv4.gitcd pytorch-YOLOv4 2、下载预训练模型

YOLOv4环境配置
2020年4月24日,YOLOv4开源了,可谓速度与精度的完美结合(但笔者认为,这也要视具体场景而定),来张AB大神的论文图先: 本文主要介绍YOLOv4的环境配置。 本文的适应环境: Ubuntu18.04 cuda10.0 cudnn7.5 opencv4.1 1、安装CUDA和CUDNN 这部分网上教程很多,可以参考以下博客: (1)安装tensorflow GPU版本–tensorf
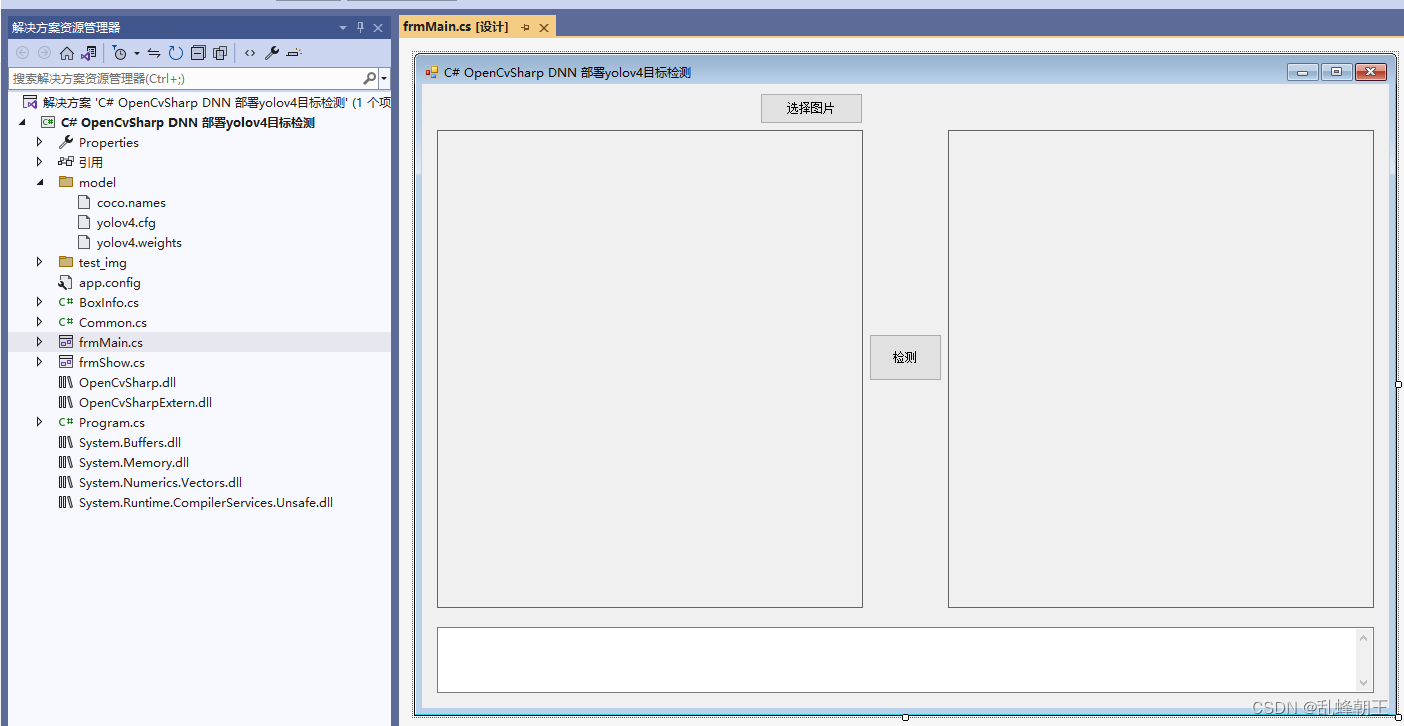
C# OpenCvSharp DNN 部署yolov4目标检测
目录 效果 项目 代码 下载 效果 项目 代码 using OpenCvSharp;using OpenCvSharp.Dnn;using System;using System.Collections.Generic;using System.Drawing;using System.IO;using System.Linq;using System.W
目标检测学习笔记(一)——YoloV4环境配置及代码实现
文章目录 前言环境配置参考 一、yoloV3算法原理及实现yolov3 算法原理主干提取网络 Darknet53 介绍残差网络Darknet53 预测部分训练部分其他参考 二、YoloV4 算法原理YOLOV4改进的部分主干特征提取网络Backbone 三、YoloV4 算法程序实现1 训练及预测步骤训练 P10VOC2007文件夹 和 voc2yolo4.pyvoc_annotation

YOLOV4 使用GeForce RTX1660Super显卡 不识别宠物狗
YOLOV4 使用GeForce RTX1660Super显卡 不识别宠物狗 但是更换GeForce RTX1060 重新安装1060显卡驱动后可以识别 CUDA不支持GeForce RTX1660Super

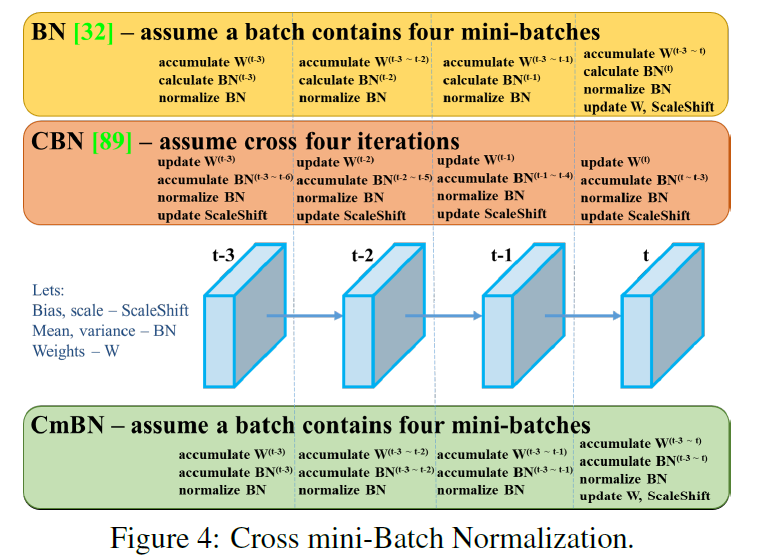
【YOLO系列】 YOLOv4之BN、CBN、CmBN(附代码)
一、BN 论文下载:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 1、背景 在神经网络训练过程中,输入的数据可能具有分布不平衡、相关性强等问题,同时随着前一层参数的变化,每一层输入的分布也会发生变化,这使得训练深度神经网络