本文主要是介绍pytorch-YOLOv4训练自己的数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题记:之前用YOLOv3训练了自己的数据集,详见该博客,Darknet--Yolov3训练自己的数据。准备试试YOLOv4,试试看校测效果是否再提高,因需要,用的pytorch版本。
一、下载代码
1、下载项目代码
git clone https://github.com/Tianxiaomo/pytorch-YOLOv4.git
cd pytorch-YOLOv42、下载预训练模型
在该目录下新建文件夹weight,用于存放权重文件,下载链接如下,下载后存放在weight文件夹下
- baidu
- yolov4.pth(https://pan.baidu.com/s/1ZroDvoGScDgtE1ja_QqJVw Extraction code:xrq9)
- yolov4.conv.137.pth(https://pan.baidu.com/s/1ovBie4YyVQQoUrC3AY0joA Extraction code:kcel)
- google
- yolov4.pth(https://drive.google.com/open?id=1wv_LiFeCRYwtpkqREPeI13-gPELBDwuJ)
- yolov4.conv.137.pth(https://drive.google.com/open?id=1fcbR0bWzYfIEdLJPzOsn4R5mlvR6IQyA)
二、配置环境
1、考虑到不同项目要求环境不同,直接在anaconda下重新创建一个虚拟环境,该环境起名为yolov4:
conda create -n yolov4 python=3.6激活该环境:
conda activate yolo_env如需关闭环境,可用如下命令:
conda deactivate2、安装pytorch
进入pytorch官网:https://pytorch.org/

下拉到这里:

根据自己的需求选择对应的选项,然后复制下面的命令在虚拟机上下载即可,我根据自己的服务器环境,选择了下面的命令:

conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch安装完成,如下:

3、安装其他包
一开始没看到requirements.txt,挨个pip,缺啥pip啥,我装的如下:
pip install opencv-python
pip install scikit-image
pip3 install tqdm
pip install tensorboardX
pip install easydict
pip install pycocotools后来发现可以一键安装所需的环境,需要用到代码里给的requirements.txt:
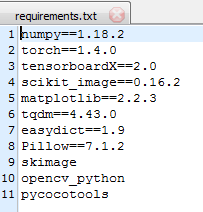
命令如下:
pip3 install -r requirements.txt三、测试模型
先测试一下demo,跑一下看看,命令如下:
python demo.py -cfgfile ./cfg/yolov4.cfg -weightfile ./weight/yolov4.weights -imgfile ./data/dog.jpg这里的demo.py所用的模型是yolov4.weights而不是yolov4.pth,其中yolov4.weights的下载链接:
- baidu(https://pan.baidu.com/s/1dAGEW8cm-dqK14TbhhVetA Extraction code:dm5b)
- google(https://drive.google.com/open?id=1cewMfusmPjYWbrnuJRuKhPMwRe_b9PaT)
PS:经博友提醒,发现之前命令不小心写错了,写成了yolov4.pth,已更正。因此提醒我试了下,demo.py用yolov4.pth跑出的来的测试图,没有框框,故猜测demo.py只能用yolov4.weights(仅个人猜测,未求证)。若要使用yolov4.pth测试,可先跳到本文第六步测试,要使用models.py来测试,具体步骤后面都有写,这里不做过多赘述。
输入命令行显示如下:

文件夹下会生成一个predictions-dog.jpg文件(原来的名字时候predictions.jpg,为了好区分我自己改了):

四、数据集
1、数据集准备
关于准备数据集,和YOLOv3一样,之前有写过,可参考上一篇博客Darknet--Yolov3训练自己的数据中的第三部分(三、数据集准备),准备好所需的图片、XML文件、训练和验证的.txt.文件。
2、数据转换
准备train.txt,内容是图片名和box,格式如下:
image_path1 x1,y1,x2,y2,id x1,y1,x2,y2,id x1,y1,x2,y2,id ...
image_path2 x1,y1,x2,y2,id x1,y1,x2,y2,id x1,y1,x2,y2,id ...
...- image_path : 图片名
- x1,y1 : 左上角坐标
- x2,y2 : 右下角坐标
- id : 物体类别
处理代码,官方给的好像是处理json格式的,我的是xml格式,重新找了一个。在pytorch-YOLOv4文件夹下,新建voc_annotation.py文件,具体代码如下:
import xml.etree.ElementTree as ET
from os import getcwdsets=[('myData', 'train'), ('myData', 'val'), ('myData', 'test')]classes = ["car", "truck", "bus", "moto", "bike", "tricycle", "pedestrian", "plate", "driver", "codriver", "tissue", "mark", "decorate"]def convert_annotation(year, image_id, list_file):##in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))in_file = open('myData/Annotations/%s.xml'%(image_id))tree=ET.parse(in_file)root = tree.getroot()for obj in root.iter('object'):difficult = 0 if obj.find('difficult')!=None:difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult)==1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))wd = getcwd()for year, image_set in sets:image_ids = open('myData/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()list_file = open('%s_%s.txt'%(year, image_set), 'w')for image_id in image_ids:list_file.write('%s/myData/JPEGImages/%s.jpg'%(wd, image_id))convert_annotation(year, image_id, list_file)list_file.write('\n')list_file.close()
运行该代码,会在pytorch-YOLOv4下生成三个文件:

我将这三个文件拷贝到myData文件夹下,为了方便(偷懒不想改训练代码了),将名字改成如下:
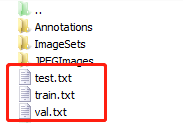
至此,所需要的数据就做好了。
五、训练模型
1、参数设置
cfg.py中根据自己需求修改如下项:


2、训练
python train.py -l 0.001 -g 2 -pretrained ./weight/yolov4.conv.137.pth -classes 13 -dir ./myData/JPEGImages/ -train_label_path ./myData/train.txt#-l 学习率
#-g gpu id
#-pretrained 预训练权值
#-classes 类别种类
#-dir 图片所在文件夹训练生成的模型保存在checkpoints文件夹中:
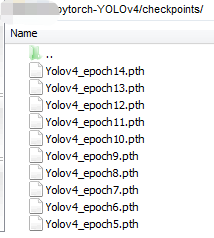
六、测试
测试模型需要用到models.py,输入命令:
python models.py <num_classes> <weightfile> <imgfile> <IN_IMAGE_H> <IN_IMAGE_W> <namefile(optional)># <num_classes> 类别
# <weightfile> 模型
# <imgfile> 要检测的图片
# <IN_IMAGE_H> 图片的高
# <IN_IMAGE_W> 图片的宽
# <namefile(optional)> 类别标签
我自己的命令如下:
python models.py 13 /checkpoints/Yolov4_epoch14.pth data/a.jpg 608 608 data/mydata.names结果报错:
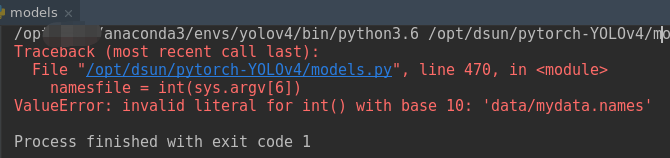
不知道为啥(原谅我又懒又菜),于是改了下代码,直接在代码里给<namefile>这个参数:

因为代码里给过<namefile>的参数了,命令行里就不给了:
python models.py 13 /checkpoints/Yolov4_epoch14.pth data/a.jpg 608 608测试结果保存在根目录下的predictions.jpg,如下:

PS:框框和字体有点细,看不清,有空再改一下。图片中的框不准,应该是我才训练了14轮就拿来测了,后面到几万应该会好很多。训练结束再来更新。
七、评估
后续再补充。。。
八、一些问题
1、train的时候遇到一个问题,说是需要创建自己的'get_image_id':

打开dataset.py,定位到出错的地方,推测是图片名字格式不对,于是改了图片名为纯数字的,但是发现并不行,看到作者注释写的:

去看了GitHub上的global image id方式,并不会用。最后直接修改dataset.py的“get_image_id”,并将自己的名字格式改为“前缀-数字.jpg”的格式,对应的xml也改为“前缀-数字.xml”:

改完可以跑了:

大家也可以根据自己的名字改写“get_image_id”,欢迎交流。
2、不知道为啥,训练速度比之前darknet-yolov3慢好多。我的26000多张图片,训练一轮要两小时,不知道是哪里出问题,有木有大佬能给说道一二。
后记:YOLOV4有darknet和pytorch等多个版本,选这个版本是因工作需要,后续要转成TensorRT,而它刚好提供了一整套转换工具,后续会继续更新模型如何转ONNX以及TensorRT。写博客为记录踩坑过程,顺便备忘,如有错误,还望大佬指教!
这篇关于pytorch-YOLOv4训练自己的数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




