whisper专题

本地搭建 Whisper 语音识别模型
Whisper 是由 OpenAI 开发的一款强大的语音识别模型,具有出色的多语言处理能力。搭建和使用 Whisper 模型可以帮助您将音频内容转换为文本,这在语音转写、语音助手、字幕生成等应用中都具有广泛的用途。本指南将对如何在本地环境中搭建 Whisper 语音识别模型进行详细的说明,并通过实例演示使您更容易理解和应用。 2. 准备工作 2.1 硬件要求 处理器:最低双核 CPU,推荐四

本地搭建 Whisper 语音识别模型实现实时语音识别研究
目录 摘要 关键词 1. 引言 2. Whisper 模型简介 3. 环境准备 4. 系统架构与实现 4.1 模型加载 4.2 实时音频输入处理 4.3 实时转录处理 4.4 程序实现的框架 4.5 代码实现 5. 实验与结果 6. 讨论 7. 结论 参考文献 摘要 语音识别技术近年来发展迅速,广泛应用于智能家居、智能客服、语音助手等领域。Whisper 是由

本地搭建和运行Whisper语音识别模型小记
搭建本地的Whisper语音识别模型可以是一个非常有用的项目,尤其是在需要离线处理语音数据的情况下。Whisper是OpenAI开发的一个开源语音识别模型,支持多语言和高效的转录能力。以下是详细的步骤来本地搭建和运行Whisper语音识别模型: 1. 准备环境 安装Python 确保你的系统上安装了Python 3.8及以上版本。可以从Python官方网站下载并安装。 创建虚拟环境(可选)

大模型之二十八-语音识别Whisper进阶
在上一篇博客大模型之二十七-语音识别Whisper实例浅析中遗留了几个问题,这里来看一下前两个问题。 1.如果不是Huggingface上可以下载的数据该怎么办? 2.上面的代码是可以训练了,但是训练的时候loss真的会和我们预期一致吗?比如如下怎么办? 进阶内容 在Whisper语音识别fine-tune的例子中,我们使用的是Huggingface封装好的数据加载以及Transformer工

AI 音频/文本对话机器人:Whisper+Edge TTS+OpenAI API构建语音与文本交互系统(简易版)
文章目录 前言思路:环境配置代码1. 加载Whisper模型2. 使用Whisper语音转文本3. 使用OpenAI API生成文本进行智能问答4. 实现文本转语音功能5. 合并音频文件6. 构建Gradio界面注意 总结 前言 在本篇博客中,我将分享如何利用Whisper模型进行语音转文本(ASR),通过Edge TTS实现文本转语音(TTS),并结合OpenAI AP

【小沐学AI】Python实现语音识别(Whisper-Web)
文章目录 1、简介2、下载2.1 openai-whisper2.2 whisper-web 结语 1、简介 https://openai.com/index/whisper/ Whisper 是一种自动语音识别 (ASR) 系统,经过 680,000 小时的多语言和多任务监督数据的训练,从网络上收集。我们表明,使用如此庞大而多样化的数据集可以提高对口音、背景噪音和技术语言的
OpenAI 开源的语音技术 Whisper 真棒!!!
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 合集: 《大模型面试宝典》(2024版) 正式发布! 《AIGC 面试宝典》已圈粉无数! 在处理音频识别和翻译时,我们经常面临多样化的音频数据和处理多种语言的难题。传

whisper 模型源码解读
whisper官方源码 whisper 模型官方代码:https://github.com/openai/whisper/blob/main/whisper/model.py ;注释如下 import base64import gzipfrom dataclasses import dataclassfrom typing import Dict, Iterable, Opti

Whisper语音识别 -- 自回归解码分析
前言 Whisper 是由 OpenAI 开发的一种先进语音识别系统。它采用深度学习技术,能够高效、准确地将语音转换为文本。Whisper 支持多种语言和口音,并且在处理背景噪音和语音变异方面表现出色。其广泛应用于语音助手、翻译服务、字幕生成等领域,为用户提供了更流畅的语音交互体验。作为一个开源项目,Whisper 鼓励开发者和研究人员进一步优化和创新。 作者将解码过程整理成 简单的pyth
深入了解 Whisper 的架构、用法以及在语音识别领域的应用和性能特征
Whisper: 通用语音识别模型详解 概述 Whisper 是一个基于 Transformer 序列到序列模型的通用语音识别系统,经过训练可以执行多语种语音识别、语音翻译和语言识别任务。本文将深入介绍 Whisper 的工作原理、设置方法、可用模型及其性能评估。 方法 Whisper 使用 Transformer 序列到序列模型,同时支持多语种语音识别、语音翻译、语种识别和语音活动检测等

吴恩达老师开源翻译工作流Agent;阿里巴巴开源无需训练即可使用参考图像编辑图像的工具;Whisper Web 浏览器字幕生成
✨ 1: Translation Agent Translation Agent 吴恩达老师开源翻译工作流Agent Translation Agent 是一个基于反思工作流程的机器翻译系统的Python示范。其主要步骤包括: 使用大语言模型(LLM)将文本从source_language翻译到target_language;让LLM反思这次翻译并提出改进建议;依据这些建议改进翻译。
导出 Whisper 模型到 ONNX
前言 在语音识别领域,Whisper 模型因其出色的性能和灵活性备受关注。为了在更多平台和环境中部署 Whisper 模型,导出为 ONNX 格式是一个有效的途径。ONNX(Open Neural Network Exchange)是一个开放格式,支持不同的深度学习框架之间的模型互操作性。本指南将详细介绍如何将 Whisper 模型导出为 ONNX 格式,并提供测试模型的步骤。 本节描
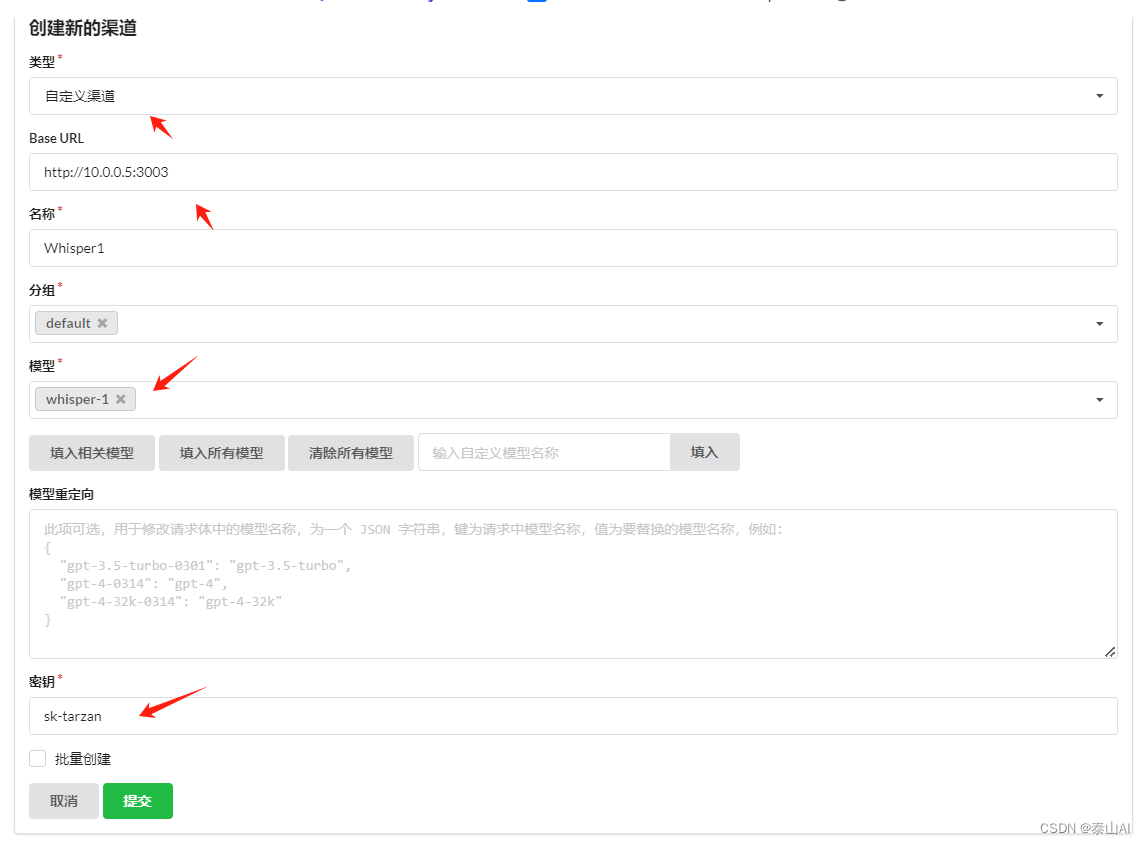
Fastgpt接入Whisper本地模型实现语音输入
前言 FastGPT 默认使用了 OpenAI 的 LLM 模型和语音识别模型,如果想要私有化部署的话,可以使用openai 开源模型Whisper。参考文章 《openai 开源模型Whisper语音转文本模型下载使用》 开源项目地址 : 兼容openai接口api服务 https://gitee.com/taisan/whisper-api 设置安全凭证(即oneapi中的渠道密钥)
优化你的WordPress网站:内链建设与Link Whisper Pro插件的利用
文章目录 内链的重要性WordPress SEO插件:Link Whisper Pro主要功能使用指南下载与安装 结语 在数字营销和网站管理领域,SEO内部优化是提升网站排名、增加流量和提高用户参与度的核心策略。在众多SEO技巧中,内链建设是构建良好网站结构和提升用户体验的关键步骤。本文将探讨内链在SEO中的重要性,并介绍一款强大的WordPress SEO插件——Link Wh
基于Whisper+SparkAI+Pyttsx3实现全流程免费的语音交互
实现前后端语音交互的Demo 在现代Web应用中,语音交互越来越受到关注。它不仅能提升用户体验,还能为特定人群提供更多便利。本文将介绍如何实现一个前后端语音交互的Demo,涵盖音频录制、语音识别、语言模型生成回复和语音合成等步骤。 文章目录 实现前后端语音交互的Demo一. 项目架构数据流流程图 二. 实现流程1. 准备工作2. 前端实现核心步骤 3. 后端实现核心步骤 配置文件运行项目
开源模型应用落地-语音转文本-whisper模型-AIGC应用探索(二)
一、前言 语音转文本技术具有重要价值。它能提高信息记录和处理的效率,使人们可以快速将语音内容转换为可编辑、可存储的文本形式,方便后续查阅和分析。在教育领域,可帮助学生更好地记录课堂重点;在办公场景中,能简化会议记录工作。同时,该技术也为残障人士提供了便利,让他们能更方便地与外界交流。此外,对于媒体行业、客服行业等都有着广泛的应用,极大地提升了工作流程和服务质量。 本文将继续介
开源模型应用落地-语音转文本-whisper模型-AIGC应用探索(一)
一、前言 语音转文本技术具有重要价值。它能提高信息记录和处理的效率,使人们可以快速将语音内容转换为可编辑、可存储的文本形式,方便后续查阅和分析。在教育领域,可帮助学生更好地记录课堂重点;在办公场景中,能简化会议记录工作。同时,该技术也为残障人士提供了便利,让他们能更方便地与外界交流。此外,对于媒体行业、客服行业等都有着广泛的应用,极大地提升了工作流程和服务质量。 本文将介绍O
whisper模型微调
Whisper模型详解及其微调过程 一、引言 在人工智能领域中,自动语音识别(ASR)技术一直是一个热门且挑战性的研究方向。近年来,随着深度学习技术的快速发展,ASR技术取得了显著的进步。其中,OpenAI的Whisper模型以其出色的性能和广泛的适用性,成为了ASR领域的佼佼者。本文将对Whisper模型进行详细介绍,并阐述其微调过程,旨在帮助读者更好地理解和应用该模型。 二、Whispe
对Whisper模型的静音攻击
针对Whisper模型的静音攻击方法主要针对基于Transformer的自动语音识别系统,特别是Whisper系列模型。其有效性主要基于Whisper模型使用了一些“特殊标记”来指导语言生成过程,如标记表示转录结束。我们可以通过在目标语音信号前添加一个通用短音频段,模拟标记的声学实现,从而成功“静音”Whisper模型。 1、针对Whisper模型的静音攻击步骤 确定攻击目标:攻
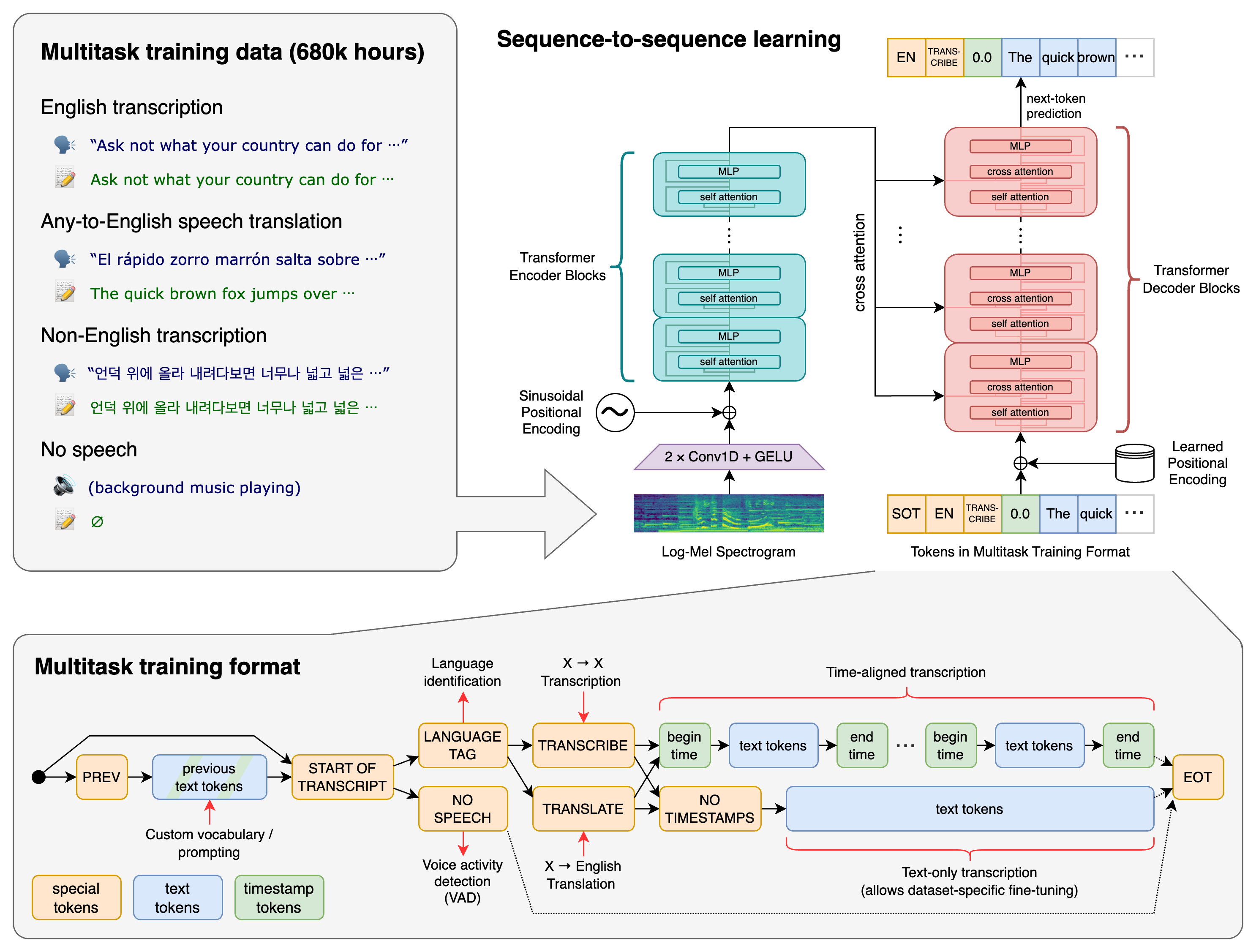
openai 开源模型Whisper语音转文本模型下载使用
Whisper Whisper 是一种通用语音识别模型。它是在大量不同音频数据集上进行训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。官方地址 https://github.com/openai/whisper 方法 一个Transformer序列到序列模型被训练在多种语音处理任务上,包括多语言语音识别、语音翻译、口语语言识别以及语音活动检测。这些任务被共同表示为
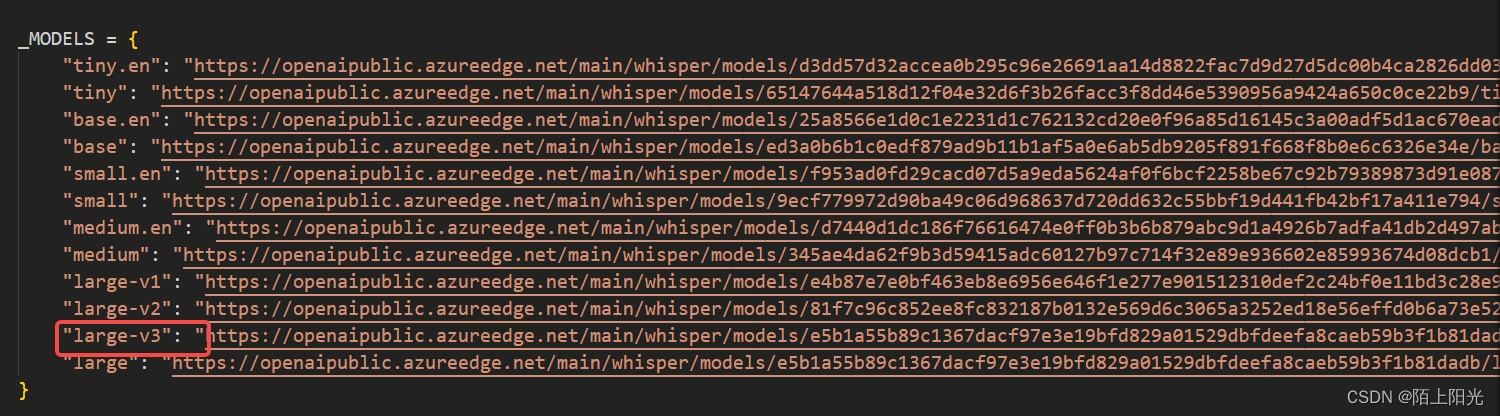
音频文件分析-- whisper(python 文档解析提取)
使用whisper转文本,这里使用的是large-v3版本 pip install git+https://github.com/openai/whisper.git import whisperimport osfrom tqdm import tqdmmodel = whisper.load_model("large-v3")path = "rag_data"for fi in
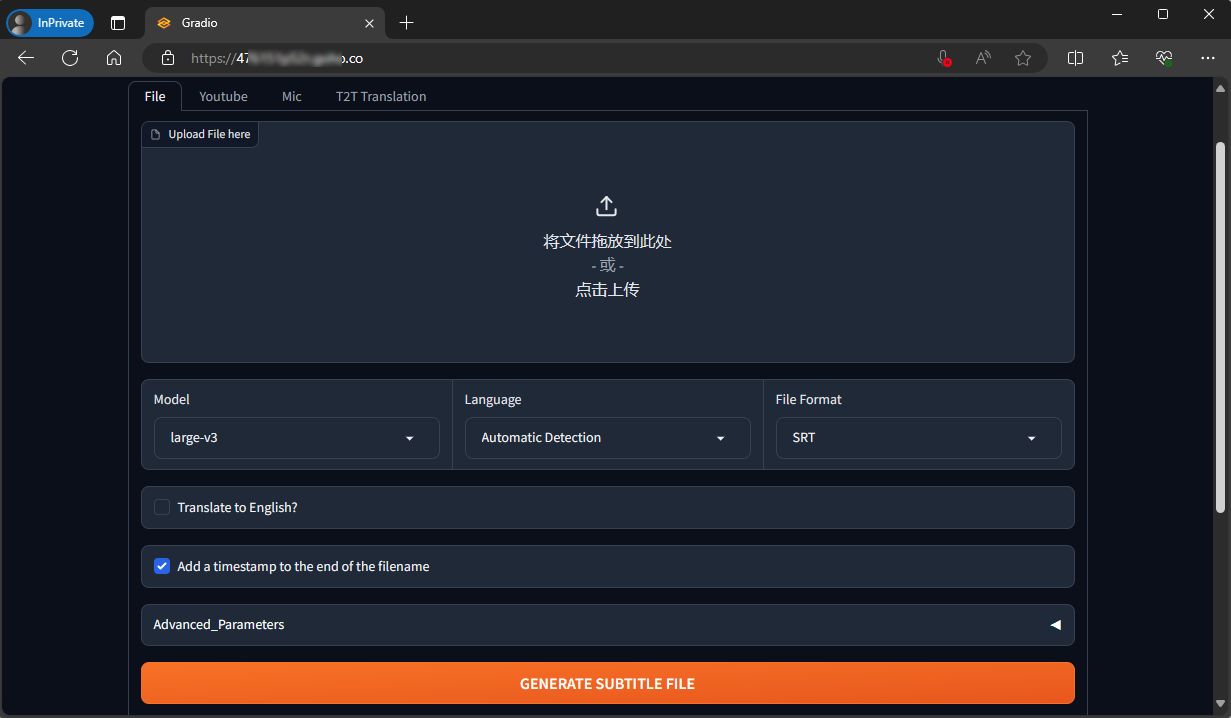
免费语音转文字:自建Whisper,贝锐花生壳3步远程访问
Whisper是OpenAI开发的自动语音识别系统(语音转文字)。 OpenAI称其英文语音辨识能力已达到人类水准,且支持其它98中语言的自动语音辨识,Whisper神经网络模型被训练来运行语音辨识与翻译任务。 此外,与其他需要联网运行的商业语音识别服务相比,Whisper的独特之处在于其完全在本地运行,无需联网,从而确保了用户个人隐私的安全。 但是,由于这种内容生成式AI工具,算力要求
openai whisper 语音转文字尝鲜
最近大模型很火,也试试搭一下,这个是openai 开源的whisper,用来语音转文字。 安装 按照此文档安装,个人习惯先使用第一个pip命令安装,然后再用第二个安装剩下的依赖(主要是tiktoken) https://github.com/openai/whisper?tab=readme-ov-file pip install -U openai-whisper #安装pypi包(这个

x-cmd mod | x whisper - 使用 whisper.cpp 进行本地 AI 语音识别
介绍 Whisper 模块通过 whisper.cpp 帮助用户快速将音频转换为文字。 INFO: whisper.cpp 是一个用 C/C++ 编写的轻量级智能语音识别库,是基于 OpenAI 的 Whisper 模型的移植版本,旨在通过深度学习模型实现音频转文字功能。 由于 whisper.cpp 目前只支持 16 khz 的 wav 文件格式的音频文件,因此该模块默认会先使用 f

基于Whisper语音识别的实时视频字幕生成 (一): 流式显示视频帧和音频帧
Whishow Whistream(微流)是基于Whisper语音识别的的在线字幕生成工具,支持rtsp/rtmp/mp4等视频流在线语音识别 1. whishow介绍 whishow(微秀)是在线音视频流播放python实现,支持rtsp/rtmp/mp4等输入,也是whistream的前端。python实现原理如下: if __name__ == "__main__":stm =