term专题

【硬刚ES】ES入门 (13)Java API 操作(4)DQL(1) 请求体查询/term 查询,查询条件为关键字/分页查询/数据排序/过滤字段/Bool 查询/范围查询/模糊查询/高亮查询/聚合查
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的ES部分补充。 1 请求体查询 2 高亮查询 3 聚合查询 package com.atguigu.es.test;import org.apache.http.HttpHost;import org.apache.lucene.search.TotalHits;import org.elasticse

Elasticsearch term 查询:精确值搜索
一、引言 Elasticsearch 是一个功能强大的搜索引擎,它支持全文搜索、结构化搜索等多种搜索方式。在结构化搜索中,term 查询是一种常用的查询方式,用于在索引中查找与指定值完全匹配的文档。本文将详细介绍 term 查询的工作原理、使用场景以及如何在 Elasticsearch 中应用它。 二、term 查询概述 term 查询是 Elasticsearch 中用于精确值搜索的一种查
TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用于信息检索和文本挖掘的统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。它的重要性随着词语在文本中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF算法主要应用于关键词抽取、文档相似度计算和文本挖掘等领域。 以下是TF-IDF算法的
TF-IDF(Term Frequency-Inverse Document Frequency)算法
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于文本挖掘和信息检索的统计方法,主要用于评估一个单词在一个文档或一组文档中的重要性。它结合了词频(TF)和逆文档频率(IDF)两个指标。以下是详细解释: 1. 词频(TF,Term Frequency) 词频表示一个单词在一个文档中出现的频率。假设我们有一个单词 ( t ) 和一个文档 (
【神经网络与深度学习】Long short-term memory网络(LSTM)
简单介绍 API介绍: nn.LSTM(input_size=100, hidden_size=10, num_layers=1,batch_first=True, bidirectional=True) inuput_size: embedding_dim hidden_size: 每一层LSTM单元的数量 num_layers: RNN中LSTM的层数 batch_first: Tr


论文:Term-Weighting Approaches in Automatic Text Retrieval翻译笔记(自动文本检索中的术语加权方法)
文章目录 论文标题:自动文本检索中的术语加权方法摘要1. 自动文本分析2. 词权重规范3. 术语加权实验4 推荐4.1 查询向量4.2 文档向量 论文标题:自动文本检索中的术语加权方法 论文链接:https://www.cs.colostate.edu/~howe/cs640/papers/salton_termWeighting.pdf 在自动文本检索中,术语加权
【investment】mid_term博迪投资学12版复习1-8章
The coverage: 《Essionals of Investments》e12 Chapter 1: 1.1 ~ 1.7 Chapter 2: 2.1 ~ 2.4(no derivative) Chapter 3: 3.1 ~ 3.10 Chapter 5: 5.1 ~ 5.6 Chapter 6: 6.1 ~ 6.5 Chapter 7: 7.1 ~ 7.4 Chapter 8: 8.1
《Coupled Term-Term Relation Analysis for Document Clustering》文献笔记(上)
相关工作 这部分主要阐述了两点,一是介绍Document Clustering领域的背景知识,其实质内容只是介绍了Document Representation——Document Clustering领域的一小部分,以词包表示法为例,给出了文本表示的数学模型;二是相关工作,列举了研究词之间关系强度计算方法,以广义向量空间模型(BVSM)为分析重点。 文本
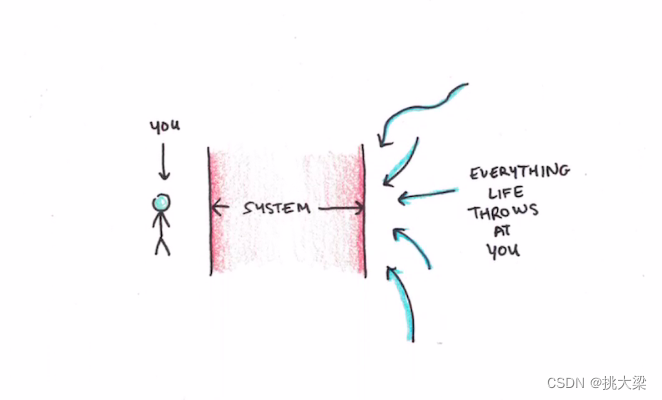
保持长期高效的七个法则(一)7 Rules for Staying Productive Long-Term(1)
Easily the best habit I’ve ever started was to use a productivity system.The idea is simple:organizing all the stuff you need to do (and how you’re going to do it) prevents a lot of internal struggle

Long-term Correlation Tracking LCT目标跟踪算法原理详解(个人学习笔记)
目录 1. 算法总览2. 算法详解2.1. 基础相关滤波跟踪2.2. 各模块详解2.2.1. 相关跟踪2.2.2. 在线检测器 3. 算法实现3.1. 算法步骤3.2. 实现细节 4. 相关讨论&总结 1. 算法总览 LCT的总体流程如上图所示,其思想为:将长时跟踪(long-term tracking)分解为对运动目标的平移(translation)估计和尺度(scale
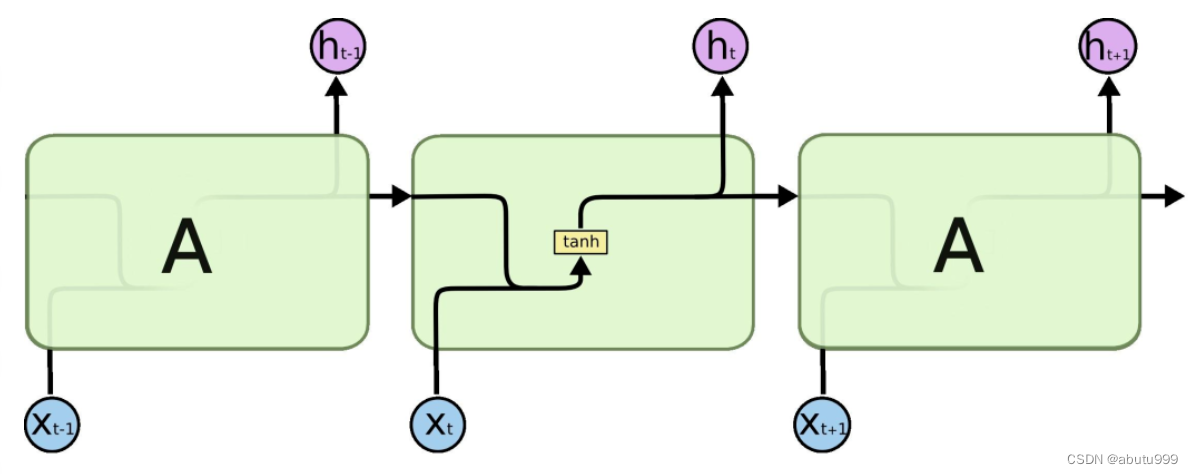
Long Short Term Memory(LSTM)
LSTM也就是长短期记忆,是用来解决RNN网络中的梯度消失而提出的。 首先我们了解一下RNN(循环神经网络),该网络主要用来处理时序问题,也就是网络的前后输入之间是有联系的,网络不仅要学习输入样本本身的特征,还有学习相邻输入样本之间的关系,所以RNN常用来处理自然语言问题,因为要理解一句话,不仅要理解话里的每个字或单词的意思,还要理解这些字或单词的不同排列顺序会产生什
Tracking The Untrackable: Learning to Track Multiple Cues with Long-Term Dependencies
来源:ICCV2017 创新点: 对于多目标跟踪的问题,现有的大多数解决方案并没能以一种一致的方式把长期的线索联合起来。本文提出了一种在线的方法,能够编码多条线索的长期的时间依赖。跟踪方法的一个关键挑战就是精准地跟踪被遮挡的物体或者那些与周围物体具有相似外观的物体。为解决这一挑战,提出一种循环神经网络(RNN)的结构,在多条线索上用一个时间窗口联合推理。该方法允许矫正数据关联的错误,并且可
php-fpm 启动参数及重要配置详解;PHP;php-fpm -c;php-fpm.pid;INT, TERM,QUIT,USR1,USR2
php-fpm 启动参数及重要配置详解 php-fpm重启操作约定几个目录一,php-fpm的启动参数二,php-fpm.conf重要参数详解三,常见错误及解决办法整理1,request_terminate_timeout引起的资源问题2,max_requests参数配置不当,可能会引起间歇性502错误:但是为什么要重启进程呢?3,php-fpm的慢日志,debug及异常排查神器:
![[论文阅读笔记21]Quo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking?](https://img-blog.csdnimg.cn/61dd20e7363f41bfa5fbf5da1a2eb9f4.png)
[论文阅读笔记21]Quo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking?
这篇文章是少有的根据轨迹预测来做MOT的文章. 论文链接: https://arxiv.org/pdf/2210.07681.pdf 代码: https://github.com/dendorferpatrick/QuoVadis 1. Abstract 长时跟踪是一个经常被忽略的问题. 对于大于三秒钟的轨迹丢失, SOTA的跟踪器中只能恢复不到10%的轨迹. 轨迹丢失的时间越长,
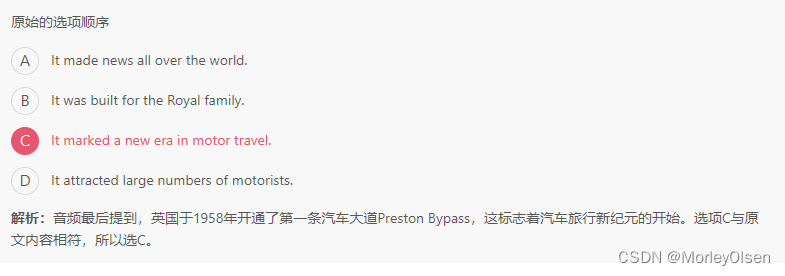
【大学英语视听说上】Mid-term Test 2
Section A 【短篇新闻1】 You probably think college students are experts at sleeping, but parties, preparations for tests, personal problems and general stress can rack a student's sleep habits, which can
Elasticsearch 中的 term、terms 和 match 查询
目录 term 查询 terms 查询 match 查询 注意事项 结论 Elasticsearch 提供了多种查询类型,用于不同的搜索需求。term、terms 和 match 是其中最常用的一些查询类型。下面分别介绍每种查询类型的用法和特点。 term 查询 term 查询用于精确值匹配。它通常用于关键字(keyword)类型的字段,或者已经过精确值(如数字、日期
Elasticsearch(es)中must以及term的基本使用
文章目录 should 和 mustterm 和 range常见的查询方式 should 和 must 在 Elasticsearch(ES)中,should 和 must 是布尔查询(Boolean Query)中常用的两个子句。 should 子句:should 表示一个或多个条件之一满足即可匹配文档。它类似于逻辑上的 OR 操作,用于构建可选项或者提升匹配文档的相
Term Termiology
term/termiology III) other fields III) other fields 3.1) GMP 《药品生产质量管理规范》(Good Manufacturing Practice of Medical Products,GMP)是药品生产和质量管理的基本准则,适用于药品制剂生产的全过程和原料药生产中影响成品质量的关键工序。
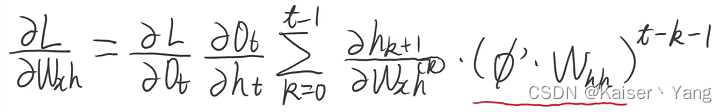
LSTM为什么晦涩难懂?Long Short-term Memory 万字解析 论文精读 LSTM的提出
说明:本文是自己阅读Long Short-term Memory期间,发现论文中的公式复杂,于是写了这篇文章进行梳理,同时给出自己的总结方法。 文中的非手绘图片均来自论文Long Short-term Memory。 注意:此篇文章提出的LSTM并不是现在所熟知的LSTM(现在是指2022年),现在的LSTM拥有Forget Gate,但是这篇文章并没有遗忘门,而带遗忘门的LSTM是出自Lear

再读Microservices-A definition of this new architectural term
前言 文章就是那种隔一段时间拿出来看看,总能获得新收获的文章。James Lewes和Martin Flower这篇就应该属于这一类,第一次读这篇文章应该是在2015年吧,读完了感觉云里雾里的,感觉懂了又感觉有点蒙,尤其是关于Product not Project那部分以及围绕业务组织团队。经过三年再看的时候才感觉到确实如此,所以本周就把重读一遍的收获在这里写一下,也算是一种特别的体验 核心内
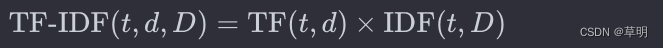
TF-IDF(Term Frequency-Inverse Document Frequency)算法 简介
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的常用算法。它用于评估一个词对于一个文档集合中某个文档的重要性。 这个算法的基本思想是:如果一个词在一个文档中频繁出现,并且在整个文档集合中很少出现,那么这个词对于这个文档的重要性较高。TF-IDF的计算涉及两个部分:词频(TF)和逆文档频率(IDF)。 1. 词频(T
【Vue3】黑马程序员 SpringBoot3+Vue3 大事件项目中 P92 抽屉样式 `:deep() Term expected` 报错的解决方法
这个报错其实不影响运行,但有些有强迫症的同学可能会很难受,以下是解决方法: 报错代码: :deep() {.avatar {width: 178px;height: 178px;display: block;}.el-upload {border: 1px dashed var(--el-border-color);border-radius: 6px;cursor: pointer;posi
论文阅读:Long-Term Visual Simultaneous Localization and Mapping
论文摘要指出,为了在长期变化的环境中准确进行定位,提出了一种新型的长期视觉SLAM(同步定位与地图构建)系统,该系统具备地图预测和动态物体移除功能。系统首先设计了一个高效的视觉点云匹配算法,将2D像素信息和3D体素信息有效融合。其次,使用贝叶斯持久性过滤器对地图点进行静态、半静态和动态分类,并移除动态点以消除其影响。通过对半静态地图点的时间序列建模,可以获得全局预测地图。最后,将预测的全局地图整合