本文主要是介绍TF-IDF(Term Frequency-Inverse Document Frequency)算法 简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的常用算法。它用于评估一个词对于一个文档集合中某个文档的重要性。
这个算法的基本思想是:如果一个词在一个文档中频繁出现,并且在整个文档集合中很少出现,那么这个词对于这个文档的重要性较高。TF-IDF的计算涉及两个部分:词频(TF)和逆文档频率(IDF)。
1. 词频(TF)
词频(TF):用于衡量一个词在文档中的出现频率。计算方式是指定词在文档中出现的次数除以文档的总词数。

2. 逆文档频率(IDF)
逆文档频率(IDF):用于衡量一个词在整个文档集合中的普遍程度。计算方式是文档集合中文档总数除以包含该词的文档数量的对数。

其中,分母加1是为了避免分母为零。
3. TF-IDF
TF-IDF:将词频和逆文档频率相乘得到最终的TF-IDF值。
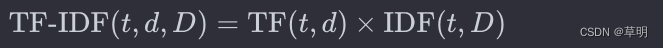
TF-IDF的应用场景包括文本相似性计算、搜索引擎排名、文本分类等。
在实际使用中,TF-IDF算法有一些变种和优化,例如考虑归一化、平滑等因素,具体实现可能会因应用场景而有所不同。
这篇关于TF-IDF(Term Frequency-Inverse Document Frequency)算法 简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









