Term Termiology
2024-01-16 17:36
文章标签
term
termiology
http://www.chinasem.cn/article/613382。
23002807@qq.com
相关文章

【硬刚ES】ES入门 (13)Java API 操作(4)DQL(1) 请求体查询/term 查询,查询条件为关键字/分页查询/数据排序/过滤字段/Bool 查询/范围查询/模糊查询/高亮查询/聚合查
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的ES部分补充。 1 请求体查询 2 高亮查询 3 聚合查询 package com.atguigu.es.test;import org.apache.http.HttpHost;import org.apache.lucene.search.TotalHits;import org.elasticse

Elasticsearch term 查询:精确值搜索
一、引言 Elasticsearch 是一个功能强大的搜索引擎,它支持全文搜索、结构化搜索等多种搜索方式。在结构化搜索中,term 查询是一种常用的查询方式,用于在索引中查找与指定值完全匹配的文档。本文将详细介绍 term 查询的工作原理、使用场景以及如何在 Elasticsearch 中应用它。 二、term 查询概述 term 查询是 Elasticsearch 中用于精确值搜索的一种查
TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用于信息检索和文本挖掘的统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。它的重要性随着词语在文本中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF算法主要应用于关键词抽取、文档相似度计算和文本挖掘等领域。 以下是TF-IDF算法的
TF-IDF(Term Frequency-Inverse Document Frequency)算法
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于文本挖掘和信息检索的统计方法,主要用于评估一个单词在一个文档或一组文档中的重要性。它结合了词频(TF)和逆文档频率(IDF)两个指标。以下是详细解释: 1. 词频(TF,Term Frequency) 词频表示一个单词在一个文档中出现的频率。假设我们有一个单词 ( t ) 和一个文档 (
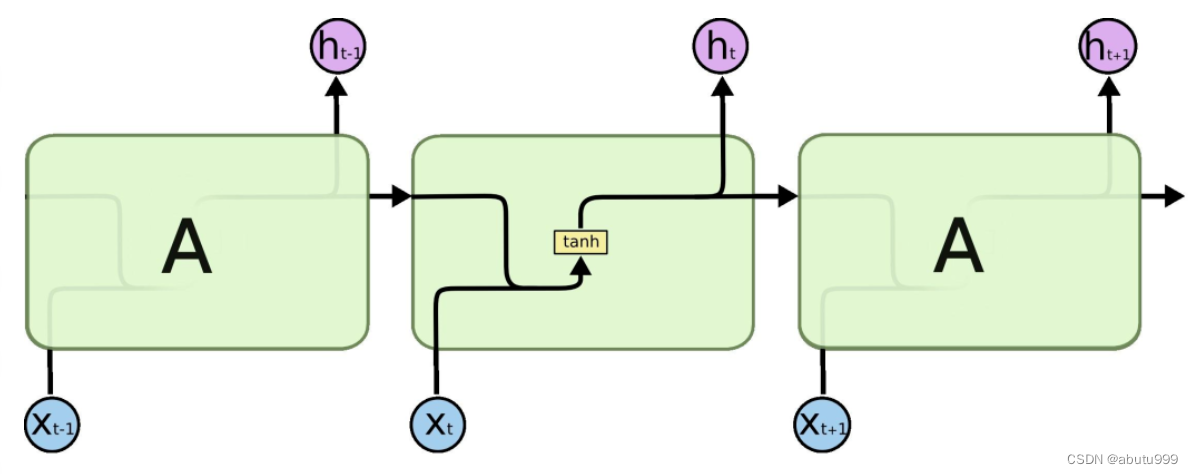
【神经网络与深度学习】Long short-term memory网络(LSTM)
简单介绍 API介绍: nn.LSTM(input_size=100, hidden_size=10, num_layers=1,batch_first=True, bidirectional=True) inuput_size: embedding_dim hidden_size: 每一层LSTM单元的数量 num_layers: RNN中LSTM的层数 batch_first: Tr
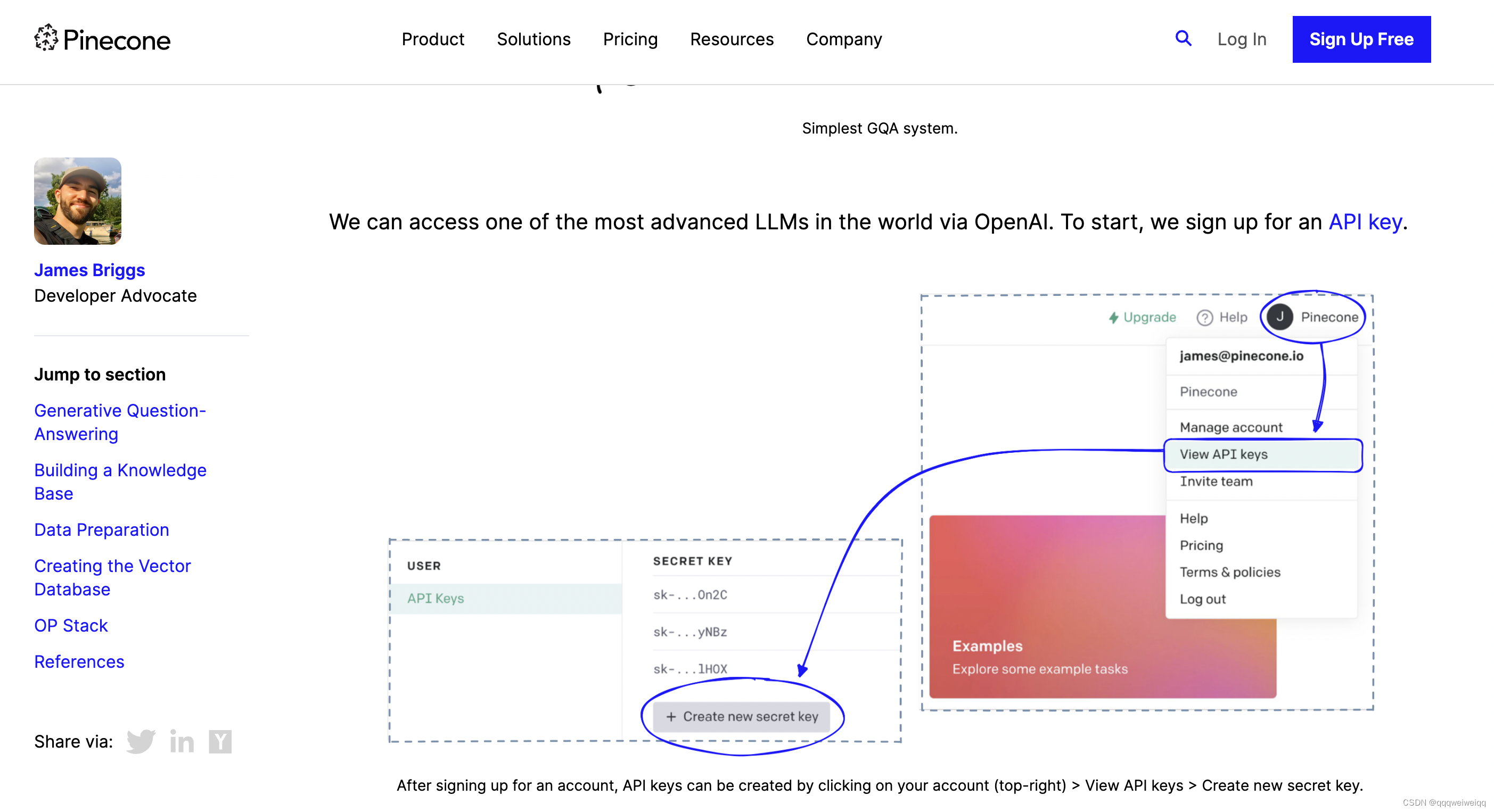

论文:Term-Weighting Approaches in Automatic Text Retrieval翻译笔记(自动文本检索中的术语加权方法)
文章目录 论文标题:自动文本检索中的术语加权方法摘要1. 自动文本分析2. 词权重规范3. 术语加权实验4 推荐4.1 查询向量4.2 文档向量 论文标题:自动文本检索中的术语加权方法 论文链接:https://www.cs.colostate.edu/~howe/cs640/papers/salton_termWeighting.pdf 在自动文本检索中,术语加权
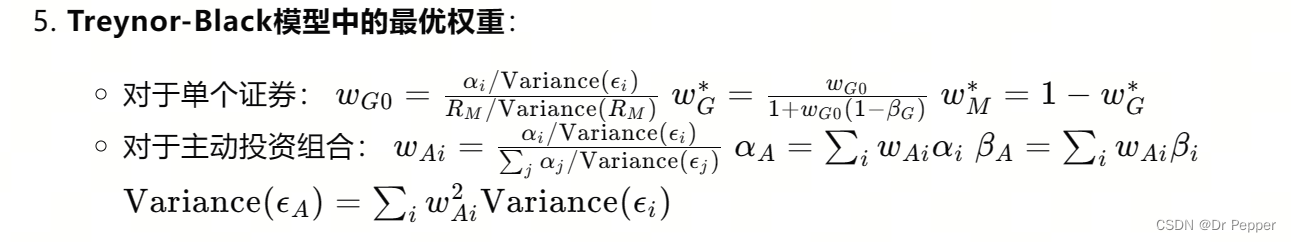
【investment】mid_term博迪投资学12版复习1-8章
The coverage: 《Essionals of Investments》e12 Chapter 1: 1.1 ~ 1.7 Chapter 2: 2.1 ~ 2.4(no derivative) Chapter 3: 3.1 ~ 3.10 Chapter 5: 5.1 ~ 5.6 Chapter 6: 6.1 ~ 6.5 Chapter 7: 7.1 ~ 7.4 Chapter 8: 8.1

《Coupled Term-Term Relation Analysis for Document Clustering》文献笔记(上)
相关工作 这部分主要阐述了两点,一是介绍Document Clustering领域的背景知识,其实质内容只是介绍了Document Representation——Document Clustering领域的一小部分,以词包表示法为例,给出了文本表示的数学模型;二是相关工作,列举了研究词之间关系强度计算方法,以广义向量空间模型(BVSM)为分析重点。 文本