task3专题

Datawhale X 李宏毅苹果书 AI夏令营-深度学习基础-Task3
# Datawhale AI 夏令营 夏令营手册:向李宏毅学深度学习 批量归一化 如果误差表面很崎岖,它比较难训练。而**批量归一化(Batch Normalization,BN)**的作用是把误差表面变得平滑,能够更好地训练。 在一个线性的的模型里面,当输入的特征,每一个维度的值,它的范围差距很大的时候,我们就可能产生像这样子的误差表面,就可能产生不同方向,斜率非常不同,坡度非常不同的误

【2024】Datawhale X 李宏毅苹果书 AI夏令营 Task3
本文是关于李宏毅苹果书”第2章 实践方法论“学习内容的记录。 模型在测试集上表现不佳,可能是因为模型没有充分学习训练集。模型不能充分学习训练集的原因: 模型偏差优化问题过拟合不匹配 一、模型偏差 模型偏差是指:由于模型过于简单,即便找到该模型的最优参数,模型的损失函数值实际还未达到最小。(想在海里捞针,但实际针不在海中) 此时可以通过重新设计模型、赋予模型更大灵活性降低模型偏差。 增加

【Datawhale X 李宏毅苹果书 AI夏令营】《深度学习详解》Task3 打卡
文章目录 前言学习目标一、优化策略二、模型偏差三、优化问题三、过拟合增加训练集给模型一些限制 四、交叉验证五、不匹配总结 前言 本文是【Datawhale X 李宏毅苹果书 AI夏令营】的Task3学习笔记打卡。 学习目标 李宏毅老师对应视频课程:https://www.bilibili.com/video/BV1JA411c7VT?p=4 《深度学习详解》第二章主要介绍

Datawhale X 李宏毅苹果书 AI夏令营 入门 Task3-机器学习框架
目录 实践方法论1.模型偏差2.优化问题3.过拟合4.交叉验证5.不匹配 实践方法论 1.模型偏差 当一个模型由于其结构的限制,无法捕捉数据中的真实关系时,即使找到了最优的参数,模型的损失依然较高。可以通过增加输入特征、使用更复杂的模型结构或采用深度学习等方法来新设计模型,增加模型的灵活性。 2.优化问题 在机器学习模型训练过程中,即使模型的灵活性足够高,也可能由于优化算
Datawhale X 李宏毅苹果书 AI夏令营 进阶 Task3-批量归一化+卷积神经网络
目录 1.批量归一化1.1 考虑深度学习1.2 测试时的批量归一化1.3 内部协变量偏移 2.卷积神经网络2.1 观察 1:检测模式不需要整张图像2.2 简化 1:感受野2.3 观察 2:同样的模式可能会出现在图像的不同区域2.4 简化 2:共享参数2.5 简化 1 和 2 的总结2.6 观察 3:下采样不影响模式检测2.7 简化 3:汇聚2.8 卷积神经网络的应用:下围棋 1.

DataWhale AI夏令营-《李宏毅深度学习教程》笔记-task3
DataWhale AI夏令营-《李宏毅深度学习教程》笔记-task2 第五章 循环神经网络5.1 独热编码5.2 RNN架构5.3 其他RNN5.3.1 Elman 网络 &Jordan 网络5.3.2 双向循环神经网络 第五章 循环神经网络 循环神经网络RNN,RNN在处理序列数据和时间依赖性强的问题上具有独特的优势,尤其是在自然语言处理和时间序列预测领域。 由图可知RN
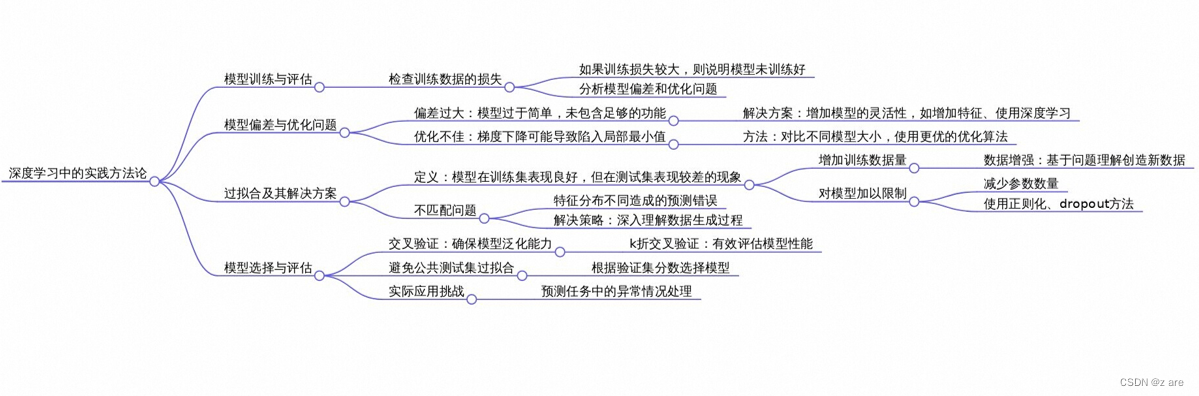
Datawhale x李宏毅苹果书AI夏令营深度学习详解入门 Task3
在深度学习中,模型偏差、优化问题和过拟合是我们经常会遇到的挑战。理解这些问题并找到合适的解决方法对于提高模型的性能至关重要。 第一章:模型偏差 1.1 模型过于简单可能导致模型偏差 在应用机器学习算法时,如果模型过于简单,就可能无法包含能够让损失变低的函数。例如,一个有未知参数的函数集合可能太小,无法涵盖最优的函数,导致即使找到了最优的参数,损失仍然不够低。

Datawhale X 李宏毅苹果书 AI夏令营 Task3打卡
实践方法论 1 模型偏差 1.1 基本概念 模型偏差(Model Bias),也称为“偏差误差”或“系统误差”,是指模型预测值与真实值之间的差异,这种差异并不是由随机误差引起的,而是由模型本身的结构或假设导致的。模型偏差通常反映了模型对数据的拟合程度不足。 高偏差模型的特征 在训练集和验证集上都有较高的误差。模型的预测结果与真实数据相差较大。模型对新数据的泛化能力差。

【Datawhale AI夏令营】从零上手CV竞赛Task3
文章目录 前言一、数据集增强二、设置 YOLO 模型训练参数三、模型微调总结 前言 本文的Task3对Task1的baseline代码继续进行优化的过程。 一、数据集增强 数据增强是机器学习和深度学习中常用的技术,用于通过从现有数据集中生成新的训练样本来提高模型的泛化能力。 常见的增强技术包括翻转、旋转、缩放和颜色调整。例如 Albumentations、Img

Datawhale AI 夏令营 第五期 CV Task3
活动简介 活动链接:Datawhale AI 夏令营(第五期) 以及CV里面的本次任务说明:Task 3 上分思路——数据集增强与模型预测 链接里的教程非常详细,主要是从三个方面(数据集增强、设置 YOLO 模型训练参数、设置 YOLO 模型预测行为和性能)来教我们在比赛中上分的技巧。 具体细节我就不赘述了,参看教程即可,这次我主要就Task3里的知识点做一下笔记,里面有些知识整理得真是非常
Datawhale AI 夏令营-CV竞赛-Task3
# Datawhale AI 夏令营 夏令营手册:从零上手CV竞赛 比赛:2024“大运河杯”数据开发应用创新大赛——城市治理赛道 代码运行平台:厚德云 赛题任务 本赛题的任务是开发智能识别系统,用于自动检测和分类城市管理中的违规行为。通过对摄像头捕获的视频进行分析,自动准确识别违规行为,并及时向管理部门发出告警,以实现更高效的城市管理。 数据集增强 数据增强是机器学习和深度学习中常

Datawhale AI夏令营 第五期 CV方向 Task3笔记
Task3:上分思路——数据集增强与模型预测 Part1:数据增强 数据增强是机器学习和深度学习中的一种技术,通过在原始数据集上应用一系列变换来人工地增加数据样本的数量和多样性,从而提高模型的泛化能力,减少过拟合,并通过模拟不同的数据变化来增强模型对新数据的适应性。 以下是对几种数据增强方法的简单介绍: Mosaic Augmentation: 这种方法通过将四张不同的训练图像组

城市管理违规行为智能识别 Task3学习心得
本次学习主要针对数据集增强和模型预测 1、数据增强: 1)将四张训练图像组合成一张,增加物体尺度和位置的多样性。 2)复制一个图像的随机区域并粘贴到另一个图像上,生成新的训练样本 3)图像的随机旋转、缩放、平移和剪切,增加对几何变换的鲁棒性 4)通过线性组合两张图像及其标签创造合成图像,增加特征空间的泛化 5)一个支持多种增强技术的图像增强库,提供灵活的增强管道定义 6)对图像的色相

DataWhale AI夏令营 2024大运河杯-数据开发应用创新赛-task3
DataWhale AI夏令营 2024大运河杯-数据开发应用创新赛 数据增强数据收集打标签 多的不说少的不唠,之前说过初赛基本就是比谁的数据好了,因为原始数据的质量太低了想跑到0.25都很难所以需要使用一些数据增强策略以及收集一些新的数据集。 数据增强 计算机视觉中有一个应用比较广泛的包,来进行数据增强transforms,其中包含了一些图像增强的常见策略比如调整大小、裁剪、

Datawhale X 李宏毅苹果书 AI夏令营(深度学习入门)task3
实践方法论 在应用机器学习算法时,实践方法论能够帮助我们更好地训练模型。如果在 Kaggle 上的结果不太好,虽然 Kaggle 上呈现的是测试数据的结果,但要先检查训练数据的损失。看看模型在训练数据上面,有没有学起来,再去看测试的结果,如果训练数据的损失很大,显然它在训练集上面也没有训练好。接下来再分析一下在训练集上面没有学好的原因。 1.模型的偏差 模型偏差可能会影响模型训练。举个例子,

Datawhale-爬虫-Task3(beautifulsoup)
Beautiful Soup Beautiful Soup是一个非常流行的Python模块。该模块可以解析网页,并提供定位内容的便捷接口。使用Beautiful Soup的第一步是将已下载的HTML内容解析为soup文档。由于大多数网页都不具备良好的HTML格式,因此Beautiful Soup需要对其实际格式进行确定。 例如,在下面这个简单的网页列表中,存在属性值两侧引号缺失和标签未闭合的问

【无标题】天池机器学习task3
一、介绍 LightGBM是2017年由微软推出的可扩展机器学习系统,是微软旗下DMKT的一个开源项目,由2014年首届阿里巴巴大数据竞赛获胜者之一柯国霖老师带领开发。它是一款基于GBDT(梯度提升决策树)算法的分布式梯度提升框架,为了满足缩短模型计算时间的需求,LightGBM的设计思路主要集中在减小数据对内存与计算性能的使用,以及减少多机器并行计算时的通讯代价。 LightGBM的主要优点:

【无标题】阿里云天池task3学习笔记
1、NN 神经网络包含输入层、隐藏层、输出层,其中涉及的一些过程如图。 两车 以下内容来自Datawhale的讲义 2、CNN介绍 卷积神经网络(简称CNN)是一类特殊的人工神经网络,是深度学习中重要的一个分支。CNN在很多领域都表现优异,精度和速度比传统计算学习算法高很多。特别是在计算机视觉领域,CNN是解决图像分类、图像检索、物体检测和语义分割的主流模型。 CNN每一层由众多的

深度强化学习Task3:A2C、A3C算法
本篇博客是本人参加Datawhale组队学习第三次任务的笔记 【教程地址】 文章目录 Actor-Critic 算法提出的动机Q Actor-Critic 算法A2C 与 A3C 算法广义优势估计A3C实现建立Actor和Critic网络定义智能体定义环境训练利用JoyRL实现多进程 练习总结 Actor-Critic 算法提出的动机 蒙特卡洛策略梯度算法和基于价值的DQN族算法的
【RL】(task3)A2C、A3C算法、JoyRL
note 文章目录 note一、A2C算法二、A3C算法时间安排Reference 一、A2C算法 在强化学习中,有一个智能体(agent)在某种环境中采取行动,根据其行动的效果获得奖励。目标是学习一种策略,即在给定的环境状态下选择最佳行动,以最大化长期累积的奖励。 A2C(Advantage Actor-Critic) Actor-Critic 框架:A2C 基于
【天池—街景字符编码识别】Task3 字符识别模型
CNN介绍 卷积神经网络(简称CNN)是一类特殊的人工神经网络,是深度学习中重要的一个分支。CNN在很多领域都表现优异,精度和速度比传统计算学习算法高很多。特别是在计算机视觉领域,CNN是解决图像分类、图像检索、物体检测和语义分割的主流模型。 CNN每一层由众多的卷积核组成,每个卷积核对输入的像素进行卷积操作,得到下一次的输入。随着网络层的增加卷积核会逐渐扩大感受野,并缩减图像的尺寸。 CNN是

linux-0.11调试教程,task3(04),sa_restore函数
返回用户态之后,先运行的是用户定义的信号处理程序,既sa_handler,然后sa_handler函数最后是ret!!!ret之后运行sa_restore函数,sa_restore函数最后也是ret!!!再返回到int 0x80下面的语句,既old_eip位置处继续运行。 所以第一需要改变的是信号处理所在的用户程序的
linux0.11调试教程,task3概述
通过/etc/rc和/etc/update文件的运行过程,可以很好的理解sys_pause的作用和机理。 以及可以理解信号的通信机制和sys_alarm系统调用是如何起作用的。 update 会设置update所在任务的信号值SIGHUP和SIGTERM的处理句柄为SIG_IGN(忽略)。 linux-0.11调试教程,task3(01),/etc/rc文件 linux-0.11
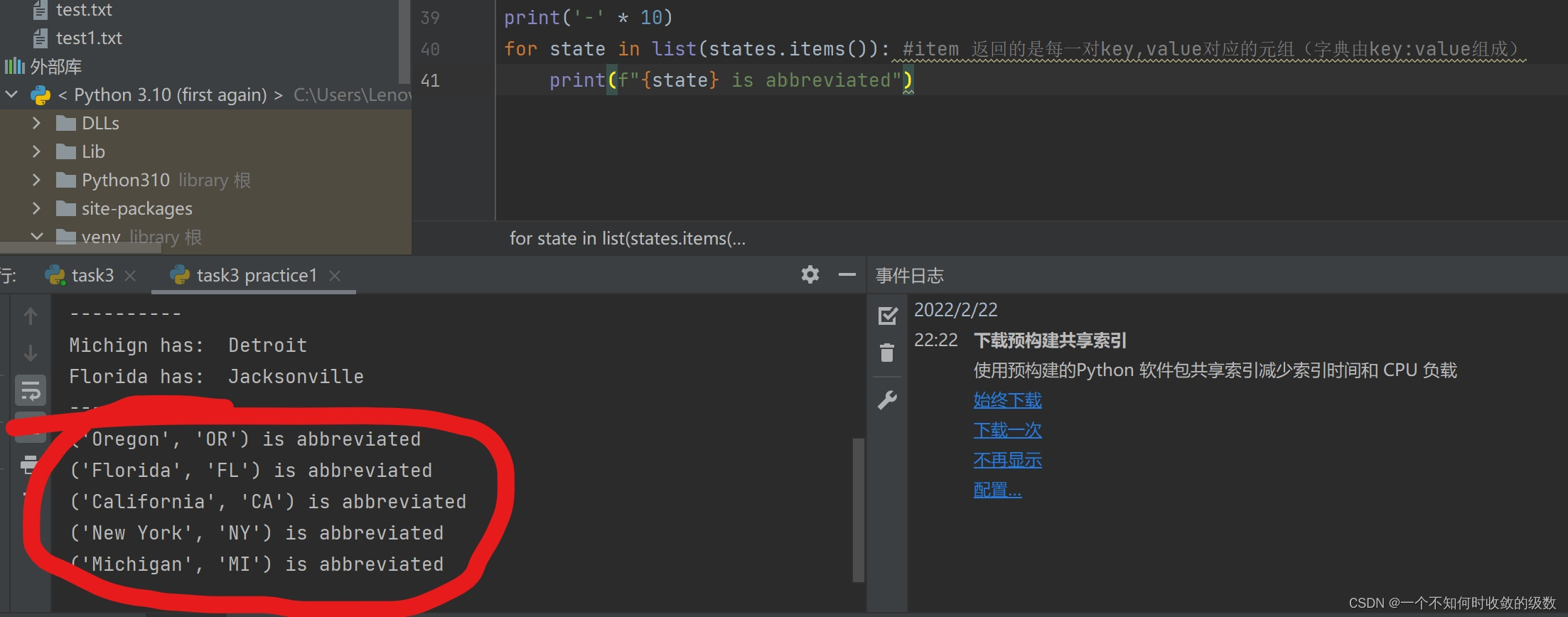
Task3 字典、元组、布尔类型、读写文件
老规矩,先上代码。 # 索引列表things = ['a','b','c','d']print(things[1])things[1] = 'z'print(things[1])print(things)#索引字典(dictionary) dict字典是大括号 而列表是中括号#列表只能用数字提取,而字典能用字符串,如下stuff = {'name': 'Zed','age': 39
Datawhale聪明办法学Python(task3变量与函数)
一、课程基本结构 课程开源地址:课程简介 - 聪明办法学 Python 第二版 章节结构: Chapter 0 安装 Installation Chapter 1 启航 Getting Started Chapter 2 数据类型和操作 Data Types and Operators Chapter 3 变量与函数 Variables and Functions Chapter 4 条

【NLP】(task3下)预训练语言模型——GPT-2
学习总结 学习了GPT-2以及对其父模型(只有 Decoder 的 Transformer),复习其中带mask的Self Attention(原文教程是有这玩意详细讲解的,下面暂时省略了)。注意GPT的Predict Next Token的过程:GPT拿到一笔训练资料的时候,先给它BOS这个token,然后GPT output一个embedding,然后接下来,你用这个embedding去预测