本文主要是介绍Task3 字典、元组、布尔类型、读写文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
老规矩,先上代码。
# 索引列表
things = ['a','b','c','d']
print(things[1])
things[1] = 'z'
print(things[1])
print(things)#索引字典(dictionary) dict字典是大括号 而列表是中括号
#列表只能用数字提取,而字典能用字符串,如下
stuff = {'name': 'Zed','age': 39, 'height': 6 * 12 + 2 }
print(stuff['name'])
print(stuff['age'])
print(stuff['height'])
stuff['city'] = "SF"
print(stuff['city'])
print(stuff)
#给字典添加东西
stuff[1] = "Wow" #命名要双引号,调用用单引号
stuff[2] = "Neato"
print(stuff[1])
print(stuff[2])
#用del删除东西
del stuff['city']
del stuff[1]
del stuff[2]
print(stuff)# 元组 不能二次赋值,相当于只读列表2
tuple = ( 'runoob', 786 , 2.23, 'john', 70.2)
tinytuple = (123, 'john')print(tuple) # 输出整个元组
print(tuple[0]) # 输出元组第1个元素
print(tuple[1:3]) # 输出元组第2到第3个元素
print(tuple[2:]) # 输出元组第3到最后一个元素
print(tinytuple * 2) # 输出两次元组
print(tuple + tinytuple) # 输出组合的元组# 以下元组不允许更新but列表允许
tuple = ( 'runoob', 786 , 2.23, 'john', 70.2)
list = [ 'runoob', 786 , 2.23, 'john', 70.2]
#tuple[2] = 1000 #元组中是非法应用
list[2] = 1000 #列表中是合法应用#布尔类型
print(True and True)
print(1 == 1 and 2 ==2)
print("test" == "testing")
print( True and False) #and一个错就全错,or则是得两者都错
print(not (1 == 1 and 0 != 1))
print(not (10 == 1 and 1000 == 1000)) #and是只要一个错就行了
print(not (3 == 1 or 2 == 1)) #or是两者都错结果才对
print(3 == 3 and (not ("testing" == "testing" or "Python" == "Fun")))#用读写文件命令做一个小小的编辑器
from sys import argvscript , filename = argvprint(f"We're going to erase {filename}.")
print("If you don't want that, hit CTRL-C (^C).")
print("IF you do want that, hit RETURN.")input("?")print("Opening the file...")
target = open(filename, 'w') # 读写模式:r只读,r+读写,w新建(会覆盖原有文件),a追加,b二进制文件.常用模式print("Truncatting the file. Goodbye!")
target.truncate() # 清空文档,慎用print("Now I'm going to ask you for three lines.")line1 = input("line 1: ") # 写入文档
line2 = input("line 2: ")
line3 = input("line 3: ")print("I'm going to write these to the file.")target.write(line1)
target.write("\n")
target.write(line2)
target.write("\n")
target.write(line3)
target.write("\n")print("And finally ,we close it.")
target.close()# 疑问:为什么把line改成4 5 6 就不行呢?
一、字典
字典(Dictionary)。字典(也叫 dict)是一种和列表类似的数据存储方式。但是不同于列表只能用数字获取数据,字典可以用任何东西来获取。可以把字典当成是一个存储和组织数据的数据库。
注:键值对在字典中以这样的方式标记:d = {key1 : value1, key2 : value2 }。注意它们的键/值对用冒号分割,而各个对用逗号分割,所有这些都包括在花括号中。另外,记住字典中的键/值对是没有顺序的。如果你想要一个特定的顺序,那么你应该在使用前自己对它们排序
二、元组
一个没啥卵用的东西,另一个数据类型,类似于 List(列表)。元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。另外,元组是不允许更新的。而列表是允许更新的。
三、布尔类型
在python表述的语法是
• and
• or
• not
• != (不等于)
• == (等于)
• >= (大于等于)
• <= (小于等于)
• True
• False
具体对错逻辑可见代码#标注~
四、读写文件
- close - 关闭文件,就像编辑器中的 “文件->另存为”一样。
- read - 读取文件内容。你可以把读取结果赋给一个变量。
- readline - 只读取文本文件的一行内容。
- truncate - 清空文件。清空的时候要当心。
- write('stuff') - 给文件写入一些“东西”。
- seek(0) - 把读/写的位置移到文件最开头。
其中 write 命令需要你提供一个你要写入的文件的字符串参数。用读写文件做一个小小的编辑器见代码。另外,读写模式:r只读;r+读写;w新建(会覆盖原有文件);a追加;b二进制文件。
特别注意:在运行之前需要先设置文件名(传参)
 结果如下
结果如下
附上一个字典的小小练习:这个例子是如何把州名和它们的缩写以及州的缩写和城市映射(mapping)起来的,记住,“映射”或者说“关联”(associate)是字典的核心理念。
#字典示例
# creat a mapping(映射) of state to abbreviation(缩写)
states = {'Oregon': 'OR', #俄亥冈洲'Florida': 'FL', #佛罗里达州'California': 'CA', #加利福尼亚州'New York': 'NY', #纽约州'Michigan': 'MI' #密歇根州
}
# creat a basic set of states and some cities in them
cities = {'CA': 'San Francisco', #圣弗朗西斯科'MI': 'Detroit', #底特律'FL': 'Jacksonville' #杰克逊维尔
}# add some more cities
#即在原有城市的字典中加入纽约和波特兰这两城市
cities['NY'] = 'New York'
cities['OR'] = 'Portland' #波特兰# print out some cities
print('-' * 10) #分隔符的作用:美观
print("NY State has: ", cities['NY'])
print("OR State has: ", cities['OR'])# print some states
# abbreviation n. 缩写
print('-' * 10)
print("Michigan's abbreviation is:", states['Michigan'])
print("Florida's abbreviation is:", states['Florida'])# do it by using the state then cities dict
print('-' * 10)
print("Michign has: ", cities[states['Michigan']]) #把州的代码赋给城市
print("Florida has: ", cities[states['Florida']])# print every state abbreviation
print('-' * 10)
for state, abbrev in list(states.items()): #item 返回的是每一对key,value对应的元组(字典由key:value组成)print(f"{state} is abbreviated {abbrev}")# print every city in state
print('-' * 10)
for abbrev, city in list(cities.items()):print(f"{abbrev} has the city {city}")# now do both at the same time
print('-' * 10)
for state, abbrev in list(states.items()):print(f"{state} state is abbreviated {abbrev}")print(f"and has city {cities[abbrev]}")print('-' * 10)
# safely get a abbreviation by state that might not be there
state = states.get('Texas') #德克萨斯州if not state:print("Sorry, no Texas.")# get a city with a default value
city = cities.get('TX', 'Does Not Exist')
print(f"The city for the state 'TX' is: {city}")(ps.只有一个变量接收值的情况下,直接返回的是每一对key,value对应的元组。举个例子,for state, abbrev变成for state,结果如下。)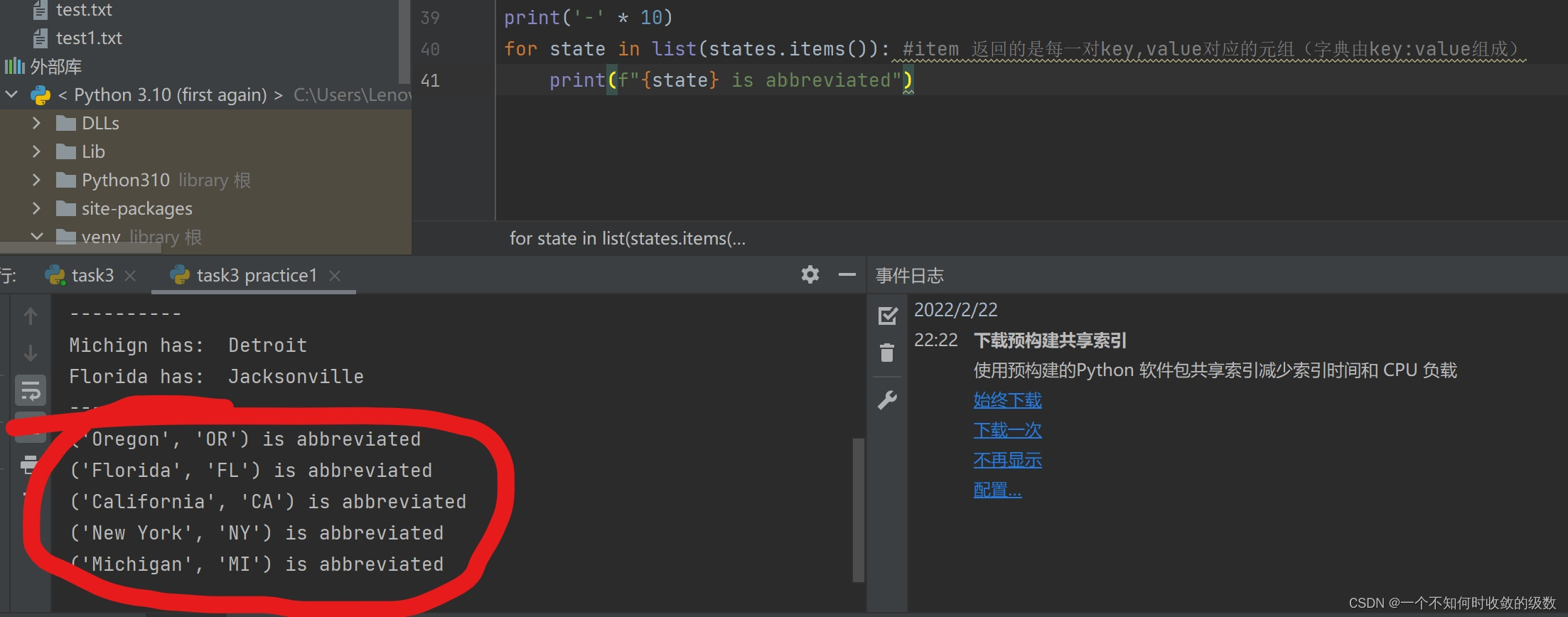
最后的最后
附上大佬的感触(等系统地学完python再回来看):
my_text = "今天又是一周的开始,打起精神认真赚钱不含参"with open("path", "w", encoding="utf-8") as f:f.write(my_text)
写入数据的时候最好是指定一下文件的编码方式,不然下次读取的时候可能就读取不了了(出现乱码)。经常遇到的问题是中文的保存,会以各种各样的编码方式保存。但其实在读取的时候选择对应的编码方式仍旧可以打开但直接保存为utf-8一劳永逸。特别是使用pandas将含有中文数据的DataFrame对象保存为csv文件的时候,有一个具体的编码方式需要指定。
其次如果是爬取的图片类型的数据此时的写入方式就需要更改为二进制方式保存,也是之前困扰过的问题。
如果爬取的文本中含有emoji而且准备写入mysql中,需要更改mysql数据库的编码方式为utf-8mb4格式,不然会出现问题。mysql数据库的版本也有要求具体5.10以上应该都可以~
数据的存写最好是使用with open() as f这种形式,上下文管理器会自动帮你读取完数据后关闭文件。不然在报错后寻找问题的原因真的很麻烦,一个小问题可能要找很久也找不到(亲生经历)。
如果遇到一个不确定是什么编码方式的文档,最好的方式是以txt打开该文件可以看到文件的编码方式,此时也可以另存为的时候将编码方式改为自己需要的合适的编码方式。
大文件的读写,很浪费时间而且对于内存的负担也很大。此时可以对数据进行分页读取比较合适 内存毕竟有限。pickle,和json可以将数据存储为二进制文件和通用的json格式文件。可能需要注意的地方就是dump和dunps以及load和loads的区别。这个真的是一直没注意每次都随机试,反正只最多需要试两下就可以,多试几次就知道了。pickle保存的.pkl文件内存小,读取快。真的非常和,json文件的引号需要注意一下。还有就是json文件load的时候如果数据有问题就直接写正则对数据做拆分,避免所有数据都被丢失。之前遇到过json文件保存明明可以,但是读取就是失败的问题。后来发现是有一些字符编码有问题,会具体报错的那个位置,可以自行定位一点一点的排除。网上有一个解决思路是有一个参数,控制解码相关的设置一下就可以了,但并不是万能的至少没解决我之前遇到的问题。
数据的写入读取方式:只读,只写,覆盖写等这些容易忽略很容易将幸幸苦苦的数据保存出问题然后发现结果不对劲。回头一看才发现是数据的写入有问题,这样就很消磨热情以及浪费时间。
这篇关于Task3 字典、元组、布尔类型、读写文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




