本文主要是介绍深度强化学习Task3:A2C、A3C算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本篇博客是本人参加Datawhale组队学习第三次任务的笔记
【教程地址】
文章目录
- Actor-Critic 算法提出的动机
- Q Actor-Critic 算法
- A2C 与 A3C 算法
- 广义优势估计
- A3C实现
- 建立Actor和Critic网络
- 定义智能体
- 定义环境
- 训练
- 利用JoyRL实现多进程
- 练习
- 总结
Actor-Critic 算法提出的动机
蒙特卡洛策略梯度算法和基于价值的DQN族算法的优缺点在深度强化学习Task2:策略梯度算法中已经介绍过了。Actor-Critic 算法提出的主要目的是为了:
- 结合两类算法的优点
- 缓解两种方法都很难解决的高方差问题
策略梯度算法是因为直接对策略参数化,相当于既要利用策略去与环境交互采样,又要利用采样去估计策略梯度
基于价值的算法也是需要与环境交互采样来估计值函数的,因此也会有高方差的问题
Q Actor-Critic 算法
目标函数:类比Q函数, 利用Critic 网络来估计价值。

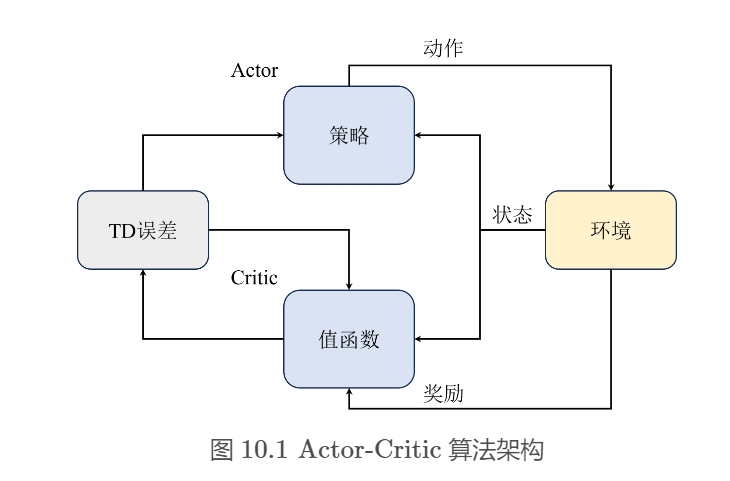
Actor-Critic算法的基本通用架构
- Actor与环境交互采样,然后将采样的轨迹输入Critic网络
- Critic网络估计出当前状态-动作对的价值
- 根据价值更新Actor网络的梯度
A2C 与 A3C 算法
为了进一步缓解高方差问题,A2C中引入一个优势函数 A π ( s t , a t ) A^\pi(s_t,a_t) Aπ(st,at),计算方式如下:
A π ( s t , a t ) = Q π ( s t , a t ) − V π ( s t ) A^\pi(s_t,a_t)=Q^\pi(s_t,a_t)-V^\pi(s_t) Aπ(st,at)=Qπ(st,at)−Vπ(st)
优势函数可以理解为在给定状态 s t s_t st下,选择动作 a t a_t at相对于平均水平的优势。如果优势为正,则说明选择这个动作比平均水平要好,反之如果为负则说明选择这个动作比平均水平要差。
将优势函数带入原目标函数中得到的结果如下:
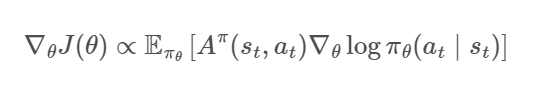
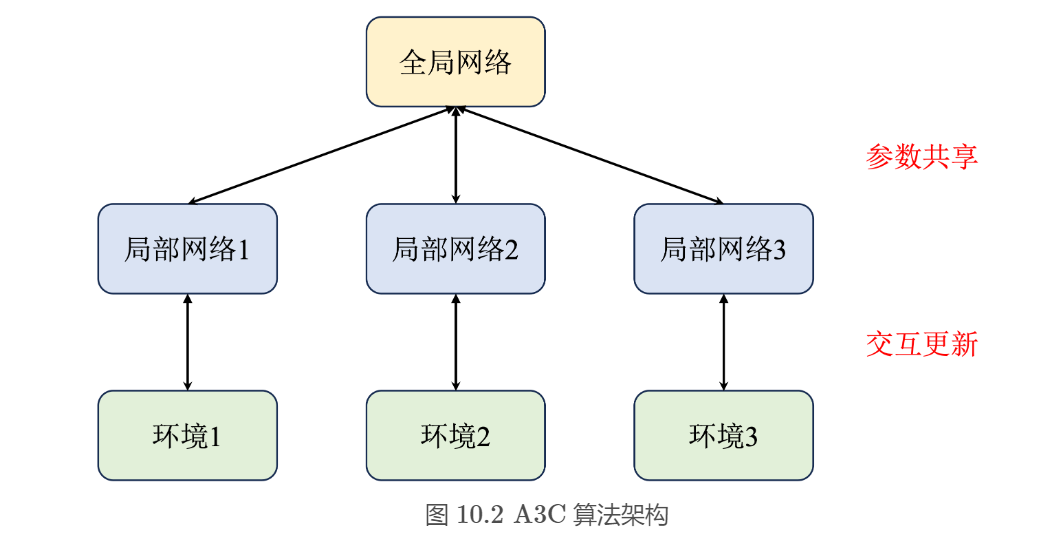
原先的 A2C 算法相当于只有一个全局网络并持续与环境交互更新。而 A3C算法中增加了多个进程,每一个进程都拥有一个独立的网络和环境以供交互,并且每个进程每隔一段时间都会将自己的参数同步到全局网络中,这样就能提高训练效率。
该算法结合了几个关键思想:
- 一种更新方案:对固定长度的经验段(比如20个时间步长)进行操作,并使用这些段来计算收益和优势函数的估计值
- 在策略和价值功能之间共享层的体系结构
- 异步更新
通过查阅Open AI的相关博客发现,A2C的同步版本比异步版本(即A3C)要好。当使用单 GPU 机器时,这个 A2C 实现比 A3C 更具成本效益,当使用更大的策略时,它比仅使用 CPU 的 A3C 实现更快。具体内容可以查看:LEARNING TO REINFORCEMENT LEARN
广义优势估计
在介绍广义优势估计之前,我们先回顾一下时序差分和蒙特卡洛方法。
- 时序差分方法可以在线学习,每走一步就可以更新,效率高。蒙特卡洛方法必须等游戏结束时才可以学习。
- 时序差分方法可以从不完整序列上进行学习。蒙特卡洛方法只能从完整的序列上进行学习。
- 时序差分方法可以在连续的环境下(没有终止)进行学习。蒙特卡洛方法只能在有终止的情况下学习。
- 时序差分方法利用了马尔可夫性质,在马尔可夫环境下有更高的学习效率。蒙特卡洛方法没有假设环境具有马尔可夫性质,利用采样的价值来估计某个状态的价值,在不是马尔可夫的环境下更加有效。
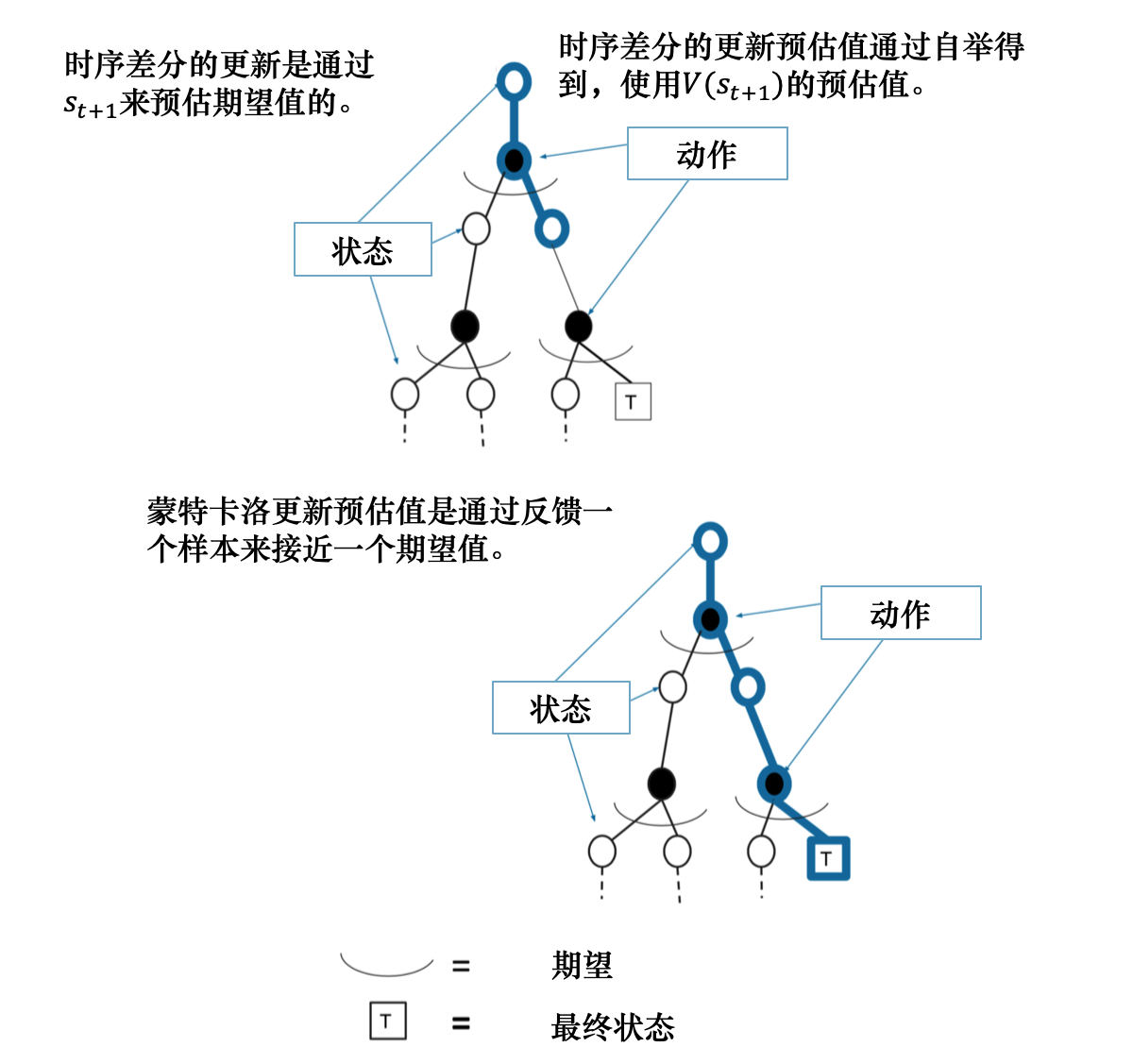
时序差分能有效解决高方差问题但是是有偏估计,而蒙特卡洛是无偏估计但是会带来高方差问题,因此通常会结合这两个方法形成一种新的估计方式,我们称之为广义优势估计( GAE \text{GAE} GAE)。
A G A E ( γ , λ ) ( s t , a t ) = ∑ l = 0 ∞ ( γ λ ) l δ t + l = ∑ l = 0 ∞ ( γ λ ) l ( r t + l + γ V π ( s t + l + 1 ) − V π ( s t + l ) ) \begin{aligned} A^{\mathrm{GAE}(\gamma, \lambda)}(s_t, a_t) &= \sum_{l=0}^{\infty}(\gamma \lambda)^l \delta_{t+l} \\ &= \sum_{l=0}^{\infty}(\gamma \lambda)^l \left(r_{t+l} + \gamma V^\pi(s_{t+l+1}) - V^\pi(s_{t+l})\right) \end{aligned} AGAE(γ,λ)(st,at)=l=0∑∞(γλ)lδt+l=l=0∑∞(γλ)l(rt+l+γVπ(st+l+1)−Vπ(st+l))
其中 δ t + l \delta_{t+l} δt+l 表示时间步 t + l t+l t+l 时的 TD \text{TD} TD 误差。
δ t + l = r t + l + γ V π ( s t + l + 1 ) − V π ( s t + l ) \begin{aligned} \delta_{t+l} = r_{t+l} + \gamma V^\pi(s_{t+l+1}) - V^\pi(s_{t+l}) \end{aligned} δt+l=rt+l+γVπ(st+l+1)−Vπ(st+l)
\qquad 当 λ = 0 \lambda = 0 λ=0 时, GAE \text{GAE} GAE退化为单步 TD \text{TD} TD 误差:
A G A E ( γ , 0 ) ( s t , a t ) = δ t = r t + γ V π ( s t + 1 ) − V π ( s t ) \begin{aligned} A^{\mathrm{GAE}(\gamma, 0)}(s_t, a_t) = \delta_t = r_t + \gamma V^\pi(s_{t+1}) - V^\pi(s_t) \end{aligned} AGAE(γ,0)(st,at)=δt=rt+γVπ(st+1)−Vπ(st)
\qquad 当 λ = 1 \lambda = 1 λ=1 时, GAE \text{GAE} GAE 退化为蒙特卡洛估计:
A G A E ( γ , 1 ) ( s t , a t ) = ∑ l = 0 ∞ ( γ λ ) l δ t + l = ∑ l = 0 ∞ ( γ ) l δ t + l \begin{aligned} A^{\mathrm{GAE}(\gamma, 1)}(s_t, a_t) = \sum_{l=0}^{\infty}(\gamma \lambda)^l \delta_{t+l} = \sum_{l=0}^{\infty}(\gamma)^l \delta_{t+l} \end{aligned} AGAE(γ,1)(st,at)=l=0∑∞(γλ)lδt+l=l=0∑∞(γ)lδt+l
A3C实现
import torch
import os
import random
import seaborn as sns
import gymnasium as gym
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
from collections import deque
from torch.distributions import Categorical
from multiprocessing import Process, Pipe
from multiprocessing_env import SubprocVecEnv
建立Actor和Critic网络
这里针对简单的环境建立一个ActorCritic网络,并且只针对离散动作空间进行处理,演员和评论家共享参数。
class ActorCritic(nn.Module):''' A2C网络模型,包含一个Actor和Critic'''def __init__(self, input_dim, output_dim, hidden_dim):super(ActorCritic, self).__init__()self.critic = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, 1))self.actor = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, output_dim),nn.Softmax(dim=1),)def forward(self, x):value = self.critic(x)probs = self.actor(x)return probs, value # 返回动作概率分布和价值
定义智能体
首先定义一个缓冲区,用于收集模型展开n_steps的轨迹,环境会根据选取的动作返回新的观测状态、奖励等信息,将这些信息存储在缓冲区中,在A3C算法中,等到智能体执行n步动作之后,将所有信息取出来进行之后的计算。
class PGReplay():def __init__(self):self.buffer = deque() # 创建缓冲区def push(self, transitions):self.buffer.append(transitions) # 将收集的信息存放在缓冲区中def sample(self):batch = list(self.buffer)return zip(*batch) # 按数据类别取出def clear(self):self.buffer.clear() # 清空缓冲区
A3C算法实际上是在A2C算法的基础上实现的,算法原理相同。A2C算法的基本原理是在演员-评论家算法的基础上引入优势函数的概念。评论家是一个函数逼近器,输入当前观测到的状态,输出评分值,也就是 Q Q Q值。而 Q Q Q值实际上可以分解为两部分,即 Q ( s , a ) = A ( s , a ) + V ( s ) Q(s,a)=A(s,a)+V(s) Q(s,a)=A(s,a)+V(s)。其中 A ( s , a ) A(s,a) A(s,a)即为优势函数,评价的是在给定状态下当前选定动作相较于其他动作的好坏,它可以通过采样数据计算得出。A2C算法的核心就在于让评论家学习 A ( s , a ) A(s,a) A(s,a)而不再是学习 Q ( s , a ) Q(s,a) Q(s,a)。
损失函数一般分为三项,策略梯度损失,值残差和策略熵正则。
- 策略梯度损失用于不断优化提升reward
- 值残差用于使critic网络不断逼近真实的reward
- 策略熵正则能够为了保证action的多样性,增加智能体探索能力。
class A3C:def __init__(self, cfg) -> None:self.gamma = cfg.gammaself.device = cfg.deviceself.model = ActorCritic(cfg.state_dim, cfg.action_dim, cfg.hidden_dim).to(self.device)self.optimizer = optim.Adam(self.model.parameters(), lr = cfg.lr)self.memory = PGReplay()self.critic_loss_coef = cfg.critic_loss_coefself.entropy_coef = cfg.entropy_coefdef compute_returns(self, next_value, rewards, masks):'''计算一个轨迹的累积奖励'''R = next_valuereturns = []for step in reversed(range(len(rewards))):R = rewards[step] + self.gamma * R * masks[step]returns.insert(0, R)return returnsdef sample_action(self,state):'''动作采样函数'''state = torch.tensor(state, device=self.device, dtype=torch.float32)probs, value = self.model(state)dist = Categorical(probs)action = dist.sample() # Tensor([0, 1, 1, 0, ...])return dist, value, action@torch.no_grad()def predict_action(self,state):'''预测动作,与动作采样函数功能相同,只是执行该函数时不需要计算梯度'''state = torch.tensor(state, device=self.device, dtype=torch.float32)probs, value = self.model(state)dist = Categorical(probs)action = dist.sample()return action.detach().cpu().numpy()def update(self, next_state, entropy):log_probs, values, rewards, masks = self.memory.sample() # 从缓冲区中取出信息进行计算next_state = torch.tensor(next_state, dtype = torch.float32).to(self.device) # numpy类型转换为tensor类型_, next_value = self.model(next_state) # shape: torch.Size([n_envs, 1])returns = self.compute_returns(next_value, rewards, masks) # shape: (n_steps, n_envs)log_probs = torch.cat(log_probs) # shape: torch.Size([n_steps * n_envs])returns = torch.cat(returns).detach() # shape: torch.Size([n_steps * n_envs])values = torch.cat(values) # shape: torch.Size([n_steps * n_envs])advantages = returns - values # shape: torch.Size([n_steps * n_envs])actor_loss = - (log_probs * advantages.detach()).mean() # 计算策略梯度损失critic_loss = advantages.pow(2).mean() # 计算值残差loss = actor_loss + self.critic_loss_coef * critic_loss - self.entropy_coef * entropy # 总loss## 梯度更新self.optimizer.zero_grad()loss.backward()self.optimizer.step()self.memory.clear() # 清空缓冲区
定义环境
在定义环境时,分别定义单个环境和多个并行的环境,用于测试和训练。
def make_envs(env_name):'''创建单个环境'''def __thunk():env = gym.make(env_name)return envreturn __thunk
def all_seed(seed = 1):''' 万能的seed函数'''if seed == 0: # 不设置seedreturn np.random.seed(seed)random.seed(seed)torch.manual_seed(seed) # config for CPUtorch.cuda.manual_seed(seed) # config for GPUos.environ['PYTHONHASHSEED'] = str(seed) # config for python scripts# config for cudnntorch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.enabled = False
def env_agent_config(cfg):env = gym.make(cfg.env_id) # 创建单个环境## 创建多个并行环境envs = [make_envs(cfg.env_id) for i in range(cfg.n_envs)]envs = SubprocVecEnv(envs) all_seed(seed=cfg.seed) # 设置随机种子state_dim = env.observation_space.shape[0] # 获取网络输入维度action_dim = env.action_space.n # 获取策略网络输出维度print(f"状态空间维度:{state_dim},动作空间维度:{action_dim}")setattr(cfg,"state_dim",state_dim) # 更新state_dim到cfg参数中setattr(cfg,"action_dim",action_dim) # 更新action_dim到cfg参数中agent = A3C(cfg) # 创建agent实例return env, envs, agent
训练
在A3C的训练过程中,通过n_envs定义多个环境,构建多个工作进程,所有的工作进程都会在每个相同的时间步上进行环境交互,经过n_steps步的交互之后,将经验收集后一起计算梯度进行模型更新。需要注意的是,这里在多进程的构建上采用的是同步更新的方法,即在每个时间步上使用的是相同的模型和策略进行交互。
def train(cfg, env, envs, agent):''' 训练'''print("开始训练!")rewards = [] # 记录所有回合的奖励steps = [] # 记录所有回合的步数sample_count = 0 # 记录智能体总共走的步数state, info = envs.reset() # 重置环境,返回初始状态 for i_ep in range(cfg.train_eps):ep_reward = 0 # 记录一条轨迹内的奖励entropy = 0 # 记录一条轨迹内的交叉熵损失for _ in range(cfg.n_steps):dist, value, action = agent.sample_action(state) # 动作采样sample_count += 1next_state, reward, terminated, truncated , info = envs.step(action.detach().cpu().numpy()) # 更新环境,返回transitionlog_prob = dist.log_prob(action)entropy += dist.entropy().mean()reward = torch.tensor(reward, dtype = torch.float32).unsqueeze(1).to(cfg.device)mask = torch.tensor(1-terminated, dtype = torch.float32).unsqueeze(1).to(cfg.device)agent.memory.push((log_prob,value,reward,mask)) # 将transition存储到缓冲区中state = next_state # 更新状态agent.update(next_state, entropy) # 更新网络参数if sample_count % 200 == 0:ep_reward = np.mean([evaluate_env(cfg, env, agent) for _ in range(10)])print(f"步数:{sample_count}/{cfg.train_eps*cfg.n_steps},奖励:{ep_reward:.2f}")rewards.append(ep_reward) print("完成训练!")envs.close()return {'rewards':rewards}
def evaluate_env(cfg, env, agent, vis=False):state, info = env.reset()if vis: env.render()terminated = Falsetotal_reward = 0for _ in range(cfg.max_steps):state = torch.tensor(state, dtype = torch.float32).unsqueeze(0).to(cfg.device)action = agent.predict_action(state)next_state, reward, terminated, truncated, _ = env.step(action[0])state = next_stateif vis: env.render()total_reward += rewardif terminated:breakreturn total_reward
def test(cfg, env, agent):print("开始测试!")rewards = [] # 记录所有回合的奖励steps = [] # 记录所有回合的步数for i_ep in range(cfg.test_eps):ep_reward = 0 # 记录一回合内的奖励ep_step = 0 # 记录一回合智能体一共走的步数state, info = env.reset(seed = cfg.seed) # 重置环境,返回初始状态for _ in range(cfg.max_steps):ep_step+=1state = torch.tensor(state, dtype = torch.float32).unsqueeze(0).to(cfg.device) action = agent.predict_action(state) # 选择动作next_state, reward, terminated, truncated , info = env.step(action[0]) # 更新环境,返回transitionstate = next_state # 更新下一个状态ep_reward += reward # 累加奖励if terminated:breaksteps.append(ep_step)rewards.append(ep_reward)print(f"回合:{i_ep+1}/{cfg.test_eps},奖励:{ep_reward:.2f}")print("完成测试")env.close()return {'rewards':rewards}
设置参数
class Config:def __init__(self) -> None:self.algo_name = 'A3C' # 算法名称self.env_id = 'CartPole-v1' # 环境idself.seed = 1 # 随机种子,便于复现,0表示不设置self.train_eps = 4000 # 训练的总步数self.test_eps = 200 # 测试的总回合数self.n_steps = 5 # 更新策略的轨迹长度self.max_steps = 200 # 测试时一个回合中能走的最大步数self.gamma = 0.99 # 折扣因子self.lr= 1e-3 # 网络学习率self.critic_loss_coef = 0.5 # 值函数系数值self.entropy_coef = 0.001 # 策略熵系数值self.hidden_dim = 256 # 网络的隐藏层维度self.n_envs = 8 # 并行的环境个数self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检测gpudef smooth(data, weight=0.9): '''用于平滑曲线,类似于Tensorboard中的smooth曲线'''last = data[0] smoothed = []for point in data:smoothed_val = last * weight + (1 - weight) * point # 计算平滑值smoothed.append(smoothed_val) last = smoothed_val return smootheddef plot_rewards(rewards,cfg, tag='train'):''' 画图'''sns.set()plt.figure() # 创建一个图形实例,方便同时多画几个图plt.title(f"{tag}ing curve on {cfg.device} of {cfg.algo_name} for {cfg.env_id}")plt.xlabel('epsiodes')plt.plot(rewards, label='rewards')plt.plot(smooth(rewards), label='smoothed')plt.legend()plt.show()
开始训练
# 获取参数
cfg = Config()
# 训练
env, envs, agent = env_agent_config(cfg)
res_dic = train(cfg, env, envs, agent)
plot_rewards(res_dic['rewards'], cfg, tag="train")
# 测试
res_dic = test(cfg, env, agent)
plot_rewards(res_dic['rewards'], cfg, tag="test") # 画出结果

查看GPU运行状况发现确实是采用了多个进程。
利用JoyRL实现多进程
JoyRL 支持多进程模式,但与矢量化环境不同,JoyRL 的多进程模式可以同时运行多个交互器和学习者。这样做的好处是,如果一个交互者或学习者失败,它不会影响其他交互者或学习者的运行,从而提高训练的稳定性。在 JoyRL 中,多进程模式可以通过将 n _ intertors 和 n _ learning 设置为大于1的整数来启动,如下所示:
n_interactors: 2
n_learners: 2
请注意,多学习者模式还不支持,即 n _ learning 必须设置为1,多学习者模式将在未来得到支持。
练习
- 相比于 REINFORCE \text{REINFORCE} REINFORCE 算法, A2C \text{A2C} A2C 主要的改进点在哪里,为什么能提高速度?
- 改进点主要有:优势估计:可以更好地区分好的动作和坏的动作,同时减小优化中的方差,从而提高了梯度的精确性,使得策略更新更有效率
- 使用 Critic \text{Critic} Critic : REINFORCE \text{REINFORCE} REINFORCE 通常只使用 Actor \text{Actor} Actor 网络,没有 Critic \text{Critic} Critic 来辅助估计动作的价值,效率更低
- 并行化:即 A3C \text{A3C} A3C ,允许在不同的环境中并行运行多个 Agent \text{Agent} Agent,每个 Agent \text{Agent} Agent 收集数据并进行策略更新,这样训练速度也会更快。
- A2C \text{A2C} A2C 算法是 on-policy \text{on-policy} on-policy 的吗?为什么?
A2C \text{A2C} A2C 在原理上是一个 on-policy \text{on-policy} on-policy算法,首先它使用当前策略的样本数据来更新策略,然后它的优势估计也依赖于当前策略的动作价值估计,并且使用的也是策略梯度方法进行更新,因此是 on-policy \text{on-policy} on-policy 的。但它可以被扩展为支持 off-policy \text{off-policy} off-policy学习,比如引入经验回放,但注意这可能需要更多的调整,以确保算法的稳定性和性能。
总结
本文首先从蒙特卡洛策略梯度算法和基于价值的DQN族算法的缺陷进行切入,引出了Actor-Critic 算法。该算法主要是对Critic 部分进行了改进,在Q Actor-Critic 算法提出的通用框架下,引入一个优势函数,即A2C算法。原先的 A2C算法相当于只有一个全局网络并持续与环境交互更新,而A3C算法中增加了多个进程,使每一个进程都拥有一个独立的网络和环境以供交互,并且每个进程每隔一段时间都会将自己的参数同步到全局网络中,提高了训练效率。之后介绍了广义优势估计着一种通用的模块,它在实践中可以用在任何需要估计优势函数的地方。最后对A2C算法进行了实现,并介绍了JoyRL包实现多进程的方法。
这篇关于深度强化学习Task3:A2C、A3C算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







