a2c专题

策略梯度与A2C算法
文章目录 从Q learning到策略梯度AC算法A2C算法 从Q learning到策略梯度 在解决MDP问题的算法中,Value Base类算法的思路将关注点放在价值函数上,传统的Q Learning等算法是一个很好的例子。Q Learning通过与环境的交互,不断学习逼近(状态, 行为)价值函数 Q ( s t , a t ) Q(s_t, a_t) Q(st,at)

深度强化学习Task3:A2C、A3C算法
本篇博客是本人参加Datawhale组队学习第三次任务的笔记 【教程地址】 文章目录 Actor-Critic 算法提出的动机Q Actor-Critic 算法A2C 与 A3C 算法广义优势估计A3C实现建立Actor和Critic网络定义智能体定义环境训练利用JoyRL实现多进程 练习总结 Actor-Critic 算法提出的动机 蒙特卡洛策略梯度算法和基于价值的DQN族算法的
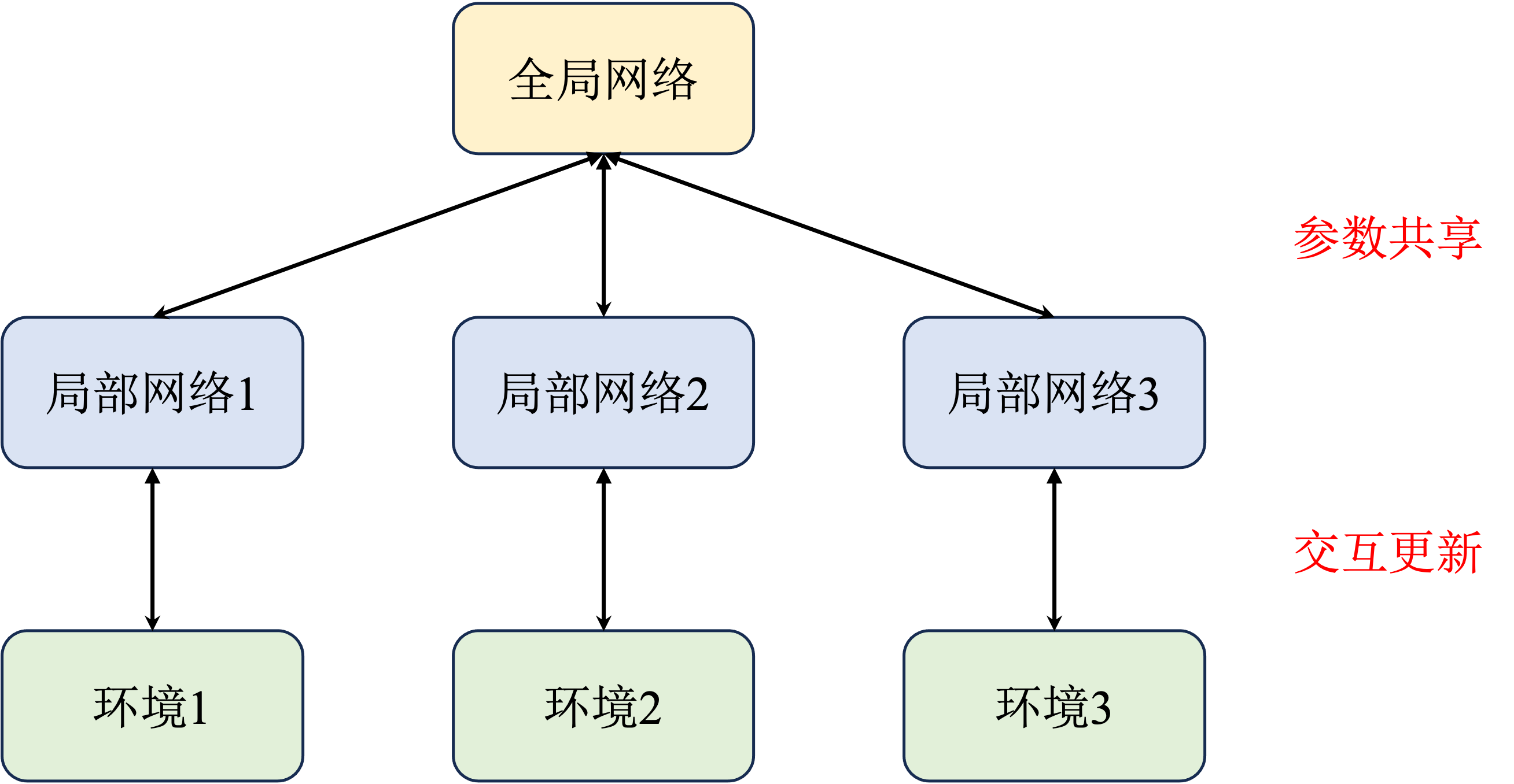
【强化学习】QAC、A2C、A3C学习笔记
强化学习算法:QAC vs A2C vs A3C 引言 经典的REINFORCE算法为我们提供了一种直接优化策略的方式,它通过梯度上升方法来寻找最优策略。然而,REINFORCE算法也有其局限性,采样效率低、高方差、收敛性差、难以处理高维离散空间。 为了克服这些限制,研究者们引入了Actor-Critic框架,它结合了价值函数和策略梯度方法的优点(适配连续动作空间和随机策略),旨在提升学习效

【RL】(task3)A2C、A3C算法、JoyRL
note 文章目录 note一、A2C算法二、A3C算法时间安排Reference 一、A2C算法 在强化学习中,有一个智能体(agent)在某种环境中采取行动,根据其行动的效果获得奖励。目标是学习一种策略,即在给定的环境状态下选择最佳行动,以最大化长期累积的奖励。 A2C(Advantage Actor-Critic) Actor-Critic 框架:A2C 基于