standalone专题

spark作业监控:standalone模式下查看历史作业
1.关闭现有的master和worker进程 2.修改spark-defaults.conf文件,配置三个属性 spark.eventLog.enabled truespark.eventLog.dir hdfs://centos-5:9001/spark-eventspark.eventLog.compress true

Flink CDC Standalone模式部署及Flink CDC Job提交
目录 部署规划 Flink CDC下载 Flink CDC安装 安装包解压 添加connector包 添加MySQL驱动 提交Flink CDC任务 独立模式(Standalone mode)是Flink最简单的部署模式。本文将介绍如何下载、安装和运行Flink CDC。 Flink CDC是基于Flink开发的一个流式数据集成
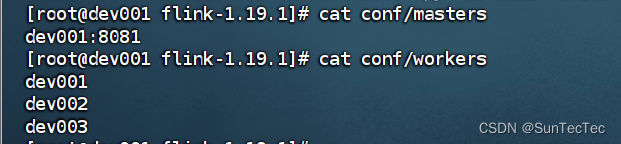
Flink 1.19.1 standalone 集群模式部署及配置
flink 1.19起 conf/flink-conf.yaml 更改为新的 conf/config.yaml standalone集群: dev001、dev002、dev003 config.yaml: jobmanager address 统一使用 dev001,bind-port 统一改成 0.0.0.0,taskmanager address 分别更改为dev所在host de

openEuler搭建hadoop Standalone 模式
Standalone 升级软件安装常用软件关闭防火墙修改主机名和IP地址修改hosts配置文件下载jdk和hadoop并配置环境变量配置ssh免密钥登录修改配置文件初始化集群windows修改hosts文件测试 1、升级软件 yum -y update 2、安装常用软件 yum -y install gcc gcc-c++ autoconf automake cmake make \z

基于Spark3.3.4版本,实现Standalone 模式高可用集群部署
目录 一、环境描述 二、部署Spark 节点 2.1 下载资源包 2.2 解压 2.3 配置 2.3.1 配置环境变量 2.3.2 修改workers配置文件 2.3.3 修改spark.env.sh文件 2.3.4 修改spark-defaults.conf 2.4 分发 2.5 启动服务 2.5.1 启动zookeeper 2.5.2 启动hdfs 2.5.

flink standalone部署模式
standalone模式可以在单台机器以不同进程方式启动,也可以以多机器分布式方式启动。 任务的提交模式有三种:application mode、session model、per-job mode(1.4x版本后过时)。 注意区分任务的提交模式与集群的部署模式区别。 以flink-1.18.1版本实验。 1.单台机器的session模式的standalone部署集群方式 此种
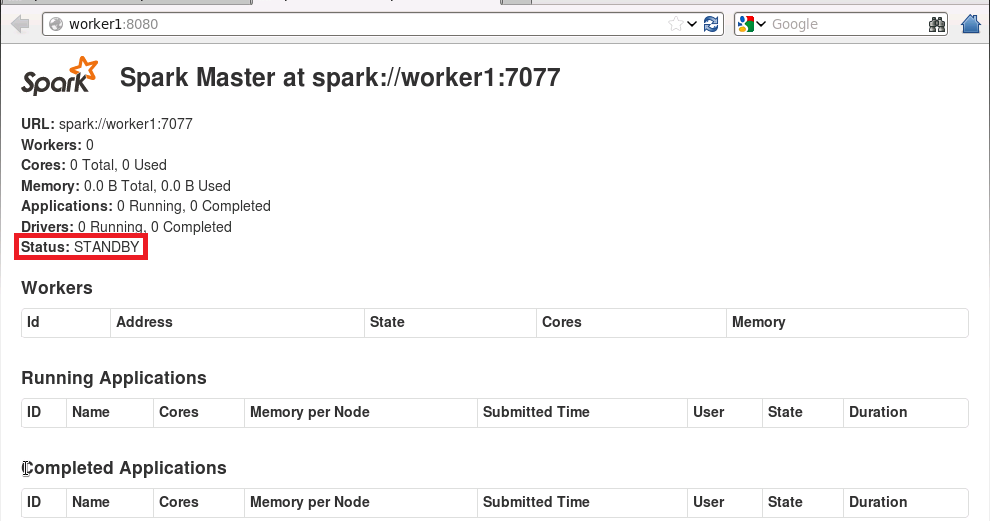
Spark1.0.2 Standalone 模式部署
节点说明 IP用户名主机名角色10.6.2.109hadoopclientSpark客户端10.6.2.111hadoopmasterHDFS(NameNode,SecondNameNode);Spark(Master,Worker)10.6.2.112hadoopworker1HDFS(DataNode);Spark(Worker)10.6.2.113hadoopworker2HDFS(Dat
linux下安装zookeeper(Standalone与Distributed模式)
环境准备 三台虚拟机:spark1,spark2,spark3 三台虚拟机已经实现免密码登录 一、搭建zookeeper的Standalone(单机)模式,在spark1上搭建。 1.向服务器上传zookeeper-3.4.6.tar.gz(版本自行选择),或通过wget下载 [root@spark1 soft]# wget http:

aws emr启动standalone的flink集群
关键组件 Client,代码由客户端获取并做转换,之后提交给JobMangerJobManager,对作业进行中央调度管理,获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的TaskManager。TaskManager,数据的处理操作 在emr上自建standalone集群,文件分发脚本xsync #!/bin/bashif [ $# -lt 1 ]thenecho No

mule-standalone 指定运行jdk版本
1.修改文件mule-standalone-3.6.0\bin\launcher.bat 1.1 指定运行的jdk code set FOUND=JAVAHOME\java.exe set FOUND =D:\Program Files\java1.7\jdk1.7\bin\java.exe 1.2 修改位置 2.修改mule-standalone-3.6.0\co
Spark standalone模式安装
Spark standalone模式安装 1、下载软件(http://www.apache.org/dyn/closer.lua/spark/spark-1.4.1/spark-1.4.1-bin-hadoop2.4.tgz) 2、准备机器我这里5台机器 192.168.80.20(cloud1) 192.168.80.21(cloud2) 192.168.80.
XML__XML文档声明? ... ?中的standalone属性
standalone在XML里的作用 今天在看用TdataSet生成的XML中第一行里有个standalone,不知道是什么意思,查了一下资料才知道它的作用,下面就把我了解的写下来。 standalone 用来表示该文件是否呼叫其它外部的文件。若值是 ”yes” 表示没有呼叫外部文件,若值是 ”no” 则表示有呼叫外部文件。默认值是 “yes”。 这里所指的外
Flink 3种部署模式、保证高可用的区别/Standalone Cluster/Yarn Cluster /Kubernetes Cluster
1 Standalone Cluster Master-Slave架构,JobManager运行在Master节点,TaskManager运行在Slave节点,与HDFS/Hadoop无关 Active JobManager挂掉时,通过Zookeeper选举多个Standby JobManager成为Active JobManager来保证高可用 2 Yarn Cluster 2.

google oauth 1.0 standalone app example
!!!OAuth in the Google Data Protocol Client Libraries讲解: http://code.google.com/intl/zh-TW/apis/gdata/docs/auth/oauth.html package example_tomson.oauth1;import java.net.URL;import com.google.gdata

05_Flink-HA高可用、JobManager HA、JobManager HA配置步骤、Flink Standalone集群HA配置、Flink on yarn集群HA配置等
1.5.Flink-HA高可用 1.5.1.JobManager高可用(HA) 1.5.2.JobManager HA配置步骤 1.5.3.Flink Standalone集群HA配置 1.5.3.1.HA集群环境规划 1.5.3.2.开始配置 1.5.3.3.配置环境变量 1.5.3.4.启动 1.5.4.Flink on yarn集群HA配置 1.5.4.1.HA集群环境规划 1.5.4.2.
ecplise提交JOB到spark on yarn/standalone
以前我通常是把scala或者java程序打包,这样在发布的时候可以结合传统运维的jekins发布规则,只需要运维手动点击发布即可,不需要每次手动发布。 最近我手动使用ecplise来提交JOB,碰到一些问题做个记录: 1. ecplise提交JOB到spark on yarn 下面是一个很简单的程序,统计a.sql行数 public class App {public static voi

Unity Standalone File Browser,Unity打开文件选择器
Unity Standalone File Browser,Unity打开文件选择器 下载地址:GitHub链接: https://github.com/gkngkc/UnityStandaloneFileBrowser 简单的示例代码 using SFB;using System;using System.IO;using UnityEngine;using UnityEngi
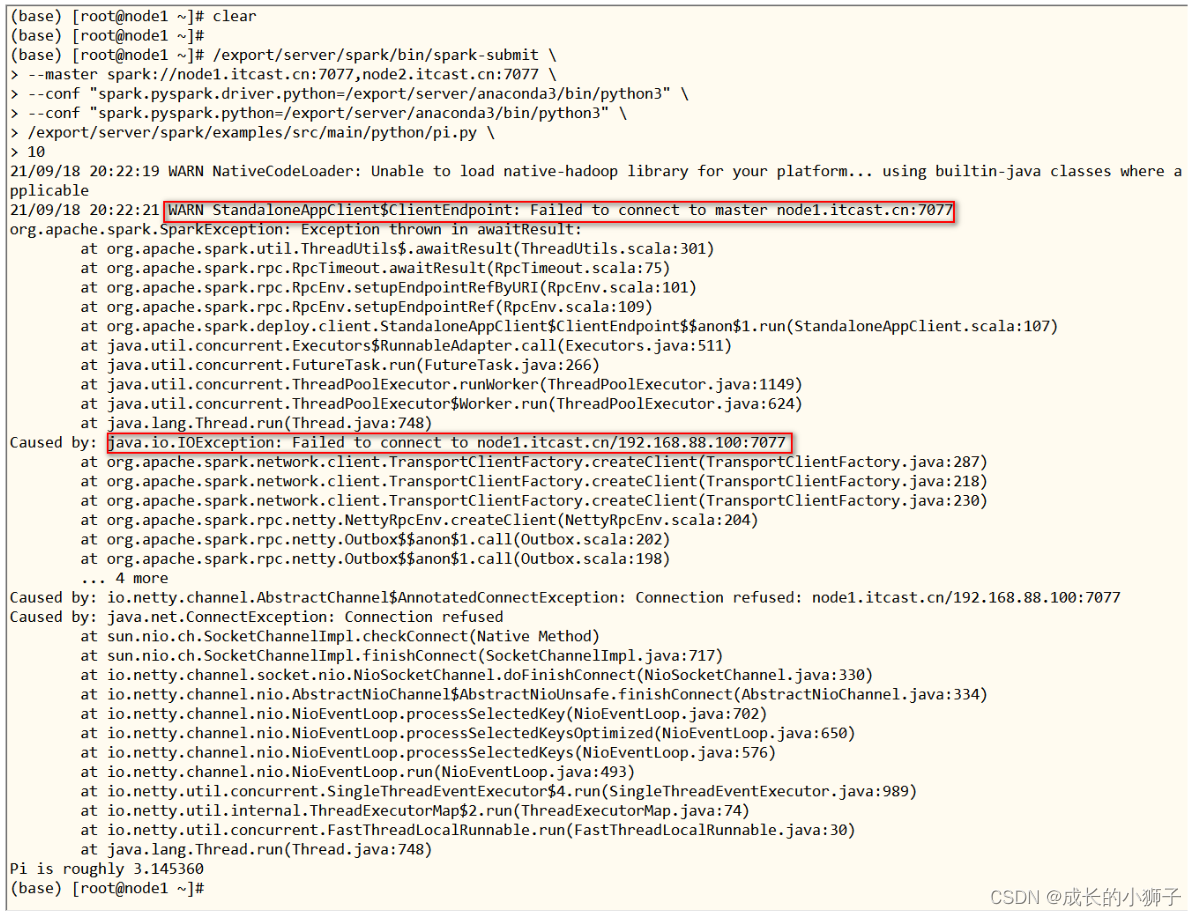
2022-02-09大数据学习日志——PySpark——Spark快速入门Standalone集群
第一部分 Spark快速入门 01_Spark 快速入门【Anaconda 软件安装】[掌握] 使用Python编写Spark代码,首先需要安装Python语言包,此时安装Anaconda科学数据分析包。 Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。Anaconda 是跨平台的,有 Windows、MacOS、Linux
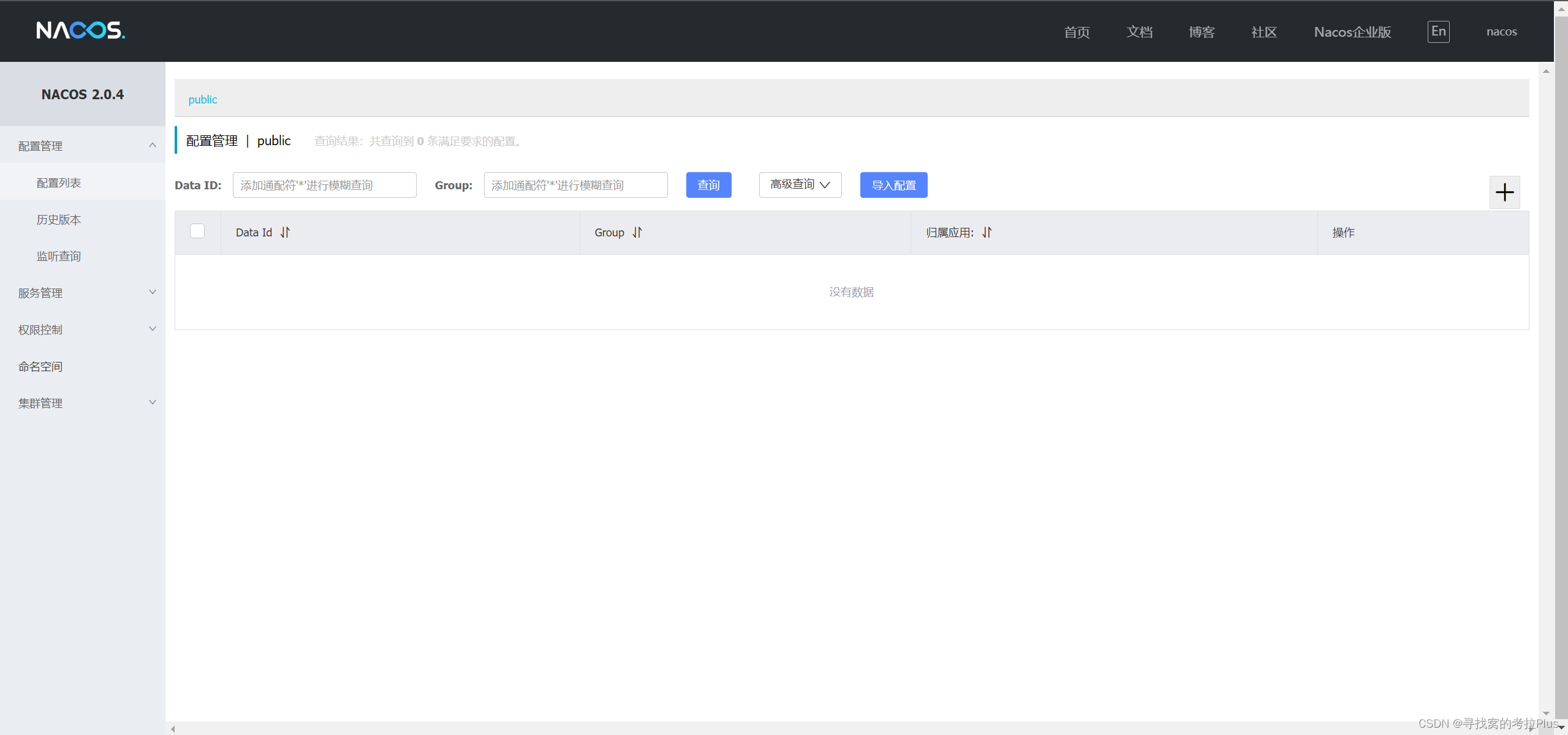
docker部署nacos,单例模式(standalone),使用内置的derby数据库,简易安装
文章目录 前言安装创建文件夹docker指令安装docker指令安装-瘦身版 制作docker-compose.yaml文件查看页面 前言 nacos作为主流的服务发现中心和配置中心,广泛应用于springcloud框架中,现在就让我们一起简易的部署一个单例模式的nacos,版本可能较低,v2.0.4,但胜在稳定且脱离mysql 安装 创建文件夹 mkdir -p /hom
spark-submit 主要参数详细说明及Standalone集群最佳实践
文章目录 1. 前言2. 参数说明3. Standalone集群最佳实践 1. 前言 部署提交应用到 spark 集群,可能会用到 spark-submit 工具,鉴于网上的博客质量残差不齐,且有很多完全是无效且错误的配置,没有搞明白诸如--total-executor-cores 、--executor-cores、--num-executors的关系和区别。因此有必要结合
EJB3(中文版) 第八集 Standalone Persistence
不启动Jboss或其它应用服务器的情况下运行EJB3程序. Enterprise_JavaBeans_3一书中的ex05_2例子. 1.检查数据库的启动2.注意事务类型 transaction-type="RESOURCE_LOCAL"3.用到jboss-EJB-3.0_Embeddable_ALPHA_9包中的Jar包4.persistence.xml文件内容<?xml version="1
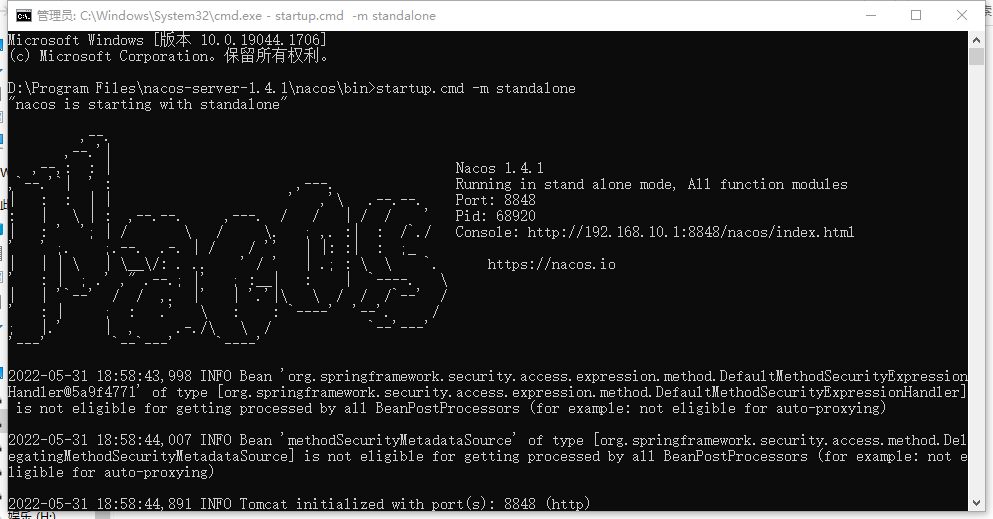
“nacos is starting with standalone“ 此时不应有 \nacos-server-1.4.1\nacos“\logs\java_heapdump.hprof -XX:-U
问题产生环境 windows10 下启动nacos 时产生 问题描述 "nacos is starting with standalone"此时不应有 \nacos-server-1.4.1\nacos"\logs\java_heapdump.hprof -XX:-UseLargePages"。 产生原因 我的nacos目录有数字,所以无法启动 解决办法 将nacos目录移动

standalone安装部署
standalone是spark的资源调度服务;作用和yarn是一样的;standlone运行时的服务: master服务;主服务;管理整个资源调度;资源的申请需要通过master进行分配;类似于yarn里的ResourceManager;(只有一个,是单点故障;一旦master有故障整个服务不可用)woke服务 ; 从服务;根据master的分配创建资源空间;给计算任务使用;类似于y
Spark Standalone 集群配置
前言 平时工作中主要用 YARN 模式,最近进行TPC测试用到了 Standalone 模式,便记录总结一下 Standalone 集群相关的配置。 集群管理类型 Spark 支持三种集群管理类型: Standalone - Spark附带的一个简单的集群管理器,可以轻松地设置集群。Apache Mesos - 一个通用的集群管理器,也可以运行HadoopMapReduce和服务应用程序。
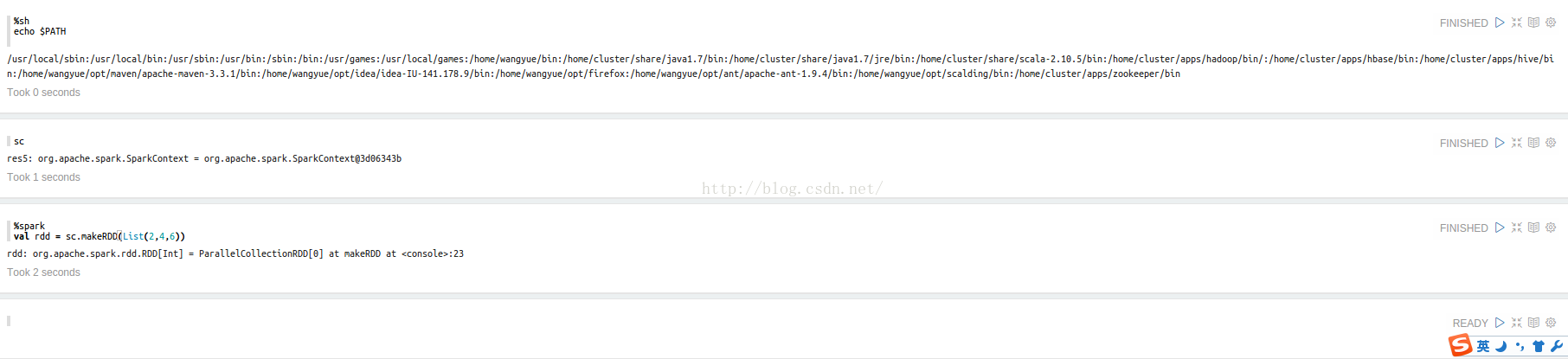
spark standalone模式 zeppelin安装
1. 前置条件 None root account Apache Maven Java 1.7 2. 源码 https://github.com/apache/incubator-zeppelin git clone https://github.com/apache/incubator-zeppelin 3. 编译 本地模式:mvn
centos7 spark standalone 模式搭建
1、先搭建spark local 模式 https://blog.csdn.net/starkpan/article/details/86437089 2、进入spark安装目录conf文件夹 cp spark-env.sh.template spark-env.sh 3、配置spark-env.sh,添加以下内容 SPARK_MASTER_HOST=hadoopOneSPARK_WO