本文主要是介绍2022-02-09大数据学习日志——PySpark——Spark快速入门Standalone集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一部分 Spark快速入门
01_Spark 快速入门【Anaconda 软件安装】[掌握]
使用Python编写Spark代码,首先需要安装Python语言包,此时安装Anaconda科学数据分析包。

Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。Anaconda 是跨平台的,有 Windows、MacOS、Linux 版本。
# 下载地址:https://repo.anaconda.com/archive/# 清华大学开源软件镜像站:https://mirrors.tuna.tsinghua.edu.cn/anaconda/
使用Python编程Spark程序,无论是开发还是运行,需要安装如下基本组件:
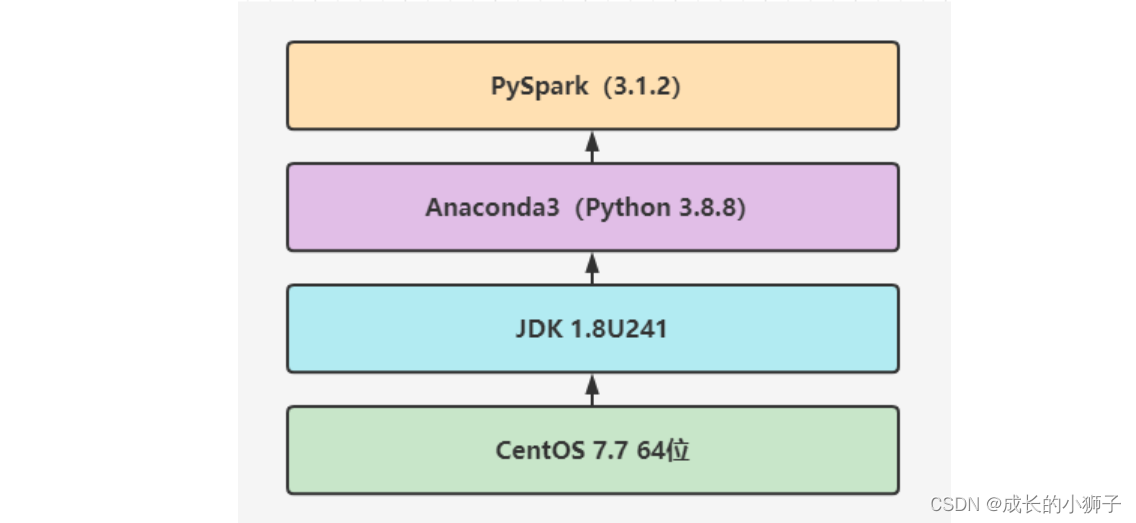
# 可以直接安装Spark 软件包包含pyspark库# 直接安装pyspark库pip install pyspark
在CentOS7系统上安装Anaconda3-2021-05版本,具体步骤如下,集群所有集群如下方式安装。
1、安装包上传并解压
[root@node1 ~]# cd /export/server/
[root@node1 server]# rz[root@node1 server]# chmod u+x Anaconda3-2021.05-Linux-x86_64.sh [root@node1 server]# sh ./Anaconda3-2021.05-Linux-x86_64.sh
第一次:【直接回车】Please, press ENTER to continue>>>
第二次:【输入yes】Do you accept the license terms? [yes|no][no] >>> yes
第三次:【输入解压路径:/export/server/anaconda3】[/root/anaconda3] >>> /export/server/anaconda3
第四次:【输入yes,是否在用户的.bashrc文件中初始化Anaconda3的相关内容】Do you wish the installer to initialize Anaconda3by running conda init? [yes|no][no] >>> yes
2、进入 conda 虚拟环境
第一次需要先激活,命令行键入以下命令: source /root/.bashrc,进入conda默认虚拟环境(base)
[root@node1 ~]# source /root/.bashrc## 测试python3
(base) [root@node1 ~]# python3
Python 3.8.8 (default, Apr 13 2021, 19:58:26)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print("Hello Python")
Hello Python
3、设置系统环境变量
[root@node1 ~]# vim /etc/profile
# Anaconda Home
export ANACONDA_HOME=/export/server/anaconda3
export PATH=$PATH:$ANACONDA_HOME/bin[root@node1 ~]# source /etc/profile[root@node1 ~]# python3
Python 3.8.8 (default, Apr 13 2021, 19:58:26)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print("Hello Python")
Hello Python
4、创建软链接
[root@node1 ~]# ln -s /export/server/anaconda3/bin/python3 /usr/bin/python3
注意:集群中三台机器node1、node2和node3都需要按照上述步骤安装Anconada3,不要使用
scp命令拷贝。
02_Spark 快速入门【Spark Python Shell】[了解]
本地模式运行Spark框架提供:基于python交互式命令行:
pyspark,其中本地模式LocalMode含义为:启动一个JVM Process进程,执行任务Task,使用方式如下:

本地模式启动JVM Process进程,示意图:

- 1、框架安装包上传解压
# 第一、进入软件安装目录
(base) [root@node1 ~]# cd /export/server/
# 第二、上传框架软件包
(base) [root@node1 server]# rz
# 第三、赋予执行权限
(base) [root@node1 server]# chmod u+x spark-3.1.2-bin-hadoop3.2.tgz # 第四、解压软件包
(base) [root@node1 server]# tar -zxf spark-3.1.2-bin-hadoop3.2.tgz
# 第五、赋予root用户和组
(base) [root@node1 server]# chown -R root:root spark-3.1.2-bin-hadoop3.2# 第六、重命名为spark-local
(base) [root@node1 server]# mv spark-3.1.2-bin-hadoop3.2 spark-local
- 2、启动
pyspark shell命令行
# 第一、进入spark框架安装目录
(base) [root@node1 ~]# cd /export/server/spark-local
(base) [root@node1 spark-local]# ll# 查看Spark软件安装包目录结构:
# 第二、启动pyspark shell命令行,设置本地模式运行
(base) [root@node1 ~]# /export/server/spark-local/bin/pyspark --master local[2]Python 3.8.8 (default, Apr 13 2021, 19:58:26)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
21/09/18 15:08:25 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//__ / .__/\_,_/_/ /_/\_\ version 3.1.2/_/Using Python version 3.8.8 (default, Apr 13 2021 19:58:26)
Spark context Web UI available at http://node1.itcast.cn:4040
Spark context available as 'sc' (master = local[2], app id = local-1631948908036).
SparkSession available as 'spark'.
>>>
其中,创建SparkContext实例对象:sc 和 SparkSession会话实例对象:spark,方便加载数据源数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jB3dZ9go-1644386077021)(assets/1632055712959.png)]
-
1、Spark context Web UI available at http://node1.itcast.cn:4040
- 每个Spark应用运行,提供WEB UI监控页面,默认端口号:
4040
- 每个Spark应用运行,提供WEB UI监控页面,默认端口号:
-
2、Spark context available as ‘sc’ (master = local[2], app id = local-1631948908036).
- 创建SparkContext类对象,名称为:
sc - Spark应用程序入口,读取数据和调度Job执行
- 创建SparkContext类对象,名称为:
-
3、Spark session available as ‘spark’.
- Spark2.0开始,提供新的程序入口:SparkSession,创建对象,名称为:
spark
- Spark2.0开始,提供新的程序入口:SparkSession,创建对象,名称为:
启动
pyspark shell命令行后,可以直接书写pyspark和python代码, 数据分析处理,如果是pyspark代码,将运行Task任务计算处理数据。案例演示:并行化列表为RDD,对其中元素平方和。
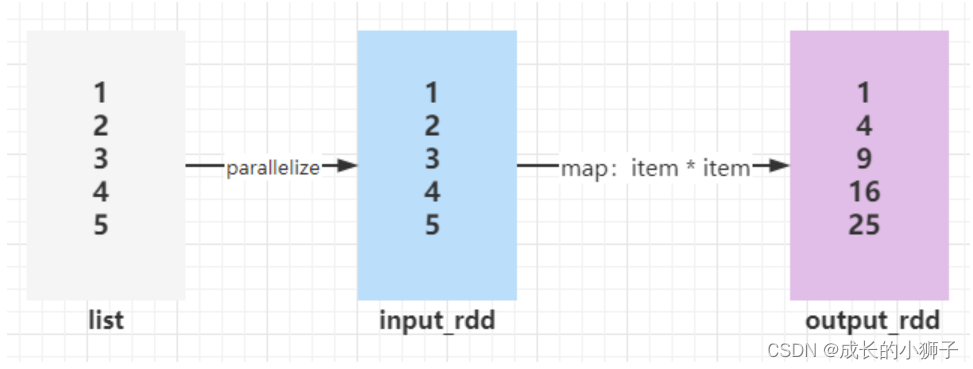
# 第一、创建RDD,并行化列表
>>> input_rdd = sc.parallelize([1, 2, 3, 4, 5])
>>>
# 第二、对集合中每个元素平方
>>> result_rdd = input_rdd.map(lambda number: number * number)
>>>
# 第三、将RDD数据转存本地列表List
>>> result_rdd.collect()
[1, 4, 9, 16, 25]

03_Spark 快速入门【词频统计WordCount】[理解]
WordCount词频统计:加载本地文件系统文本文件数据,进行词频统计WordCount

- 数据文件:
vim /root/words.txt
spark python spark hive spark hive
python spark hive spark python
mapreduce spark hadoop hdfs hadoop spark
hive mapreduce
-
词频统计WordCount
- 第一步、从LocalFS读取文件数据,
sc.textFile方法,将数据封装到RDD中 - 第二步、调用RDD中函数,进行处理转换处理,函数:
flapMap、map和reduceByKey - 第三步、将最终处理结果RDD保存到LocalFS或打印控制台,函数:
foreach、saveAsTextFile
- 第一步、从LocalFS读取文件数据,
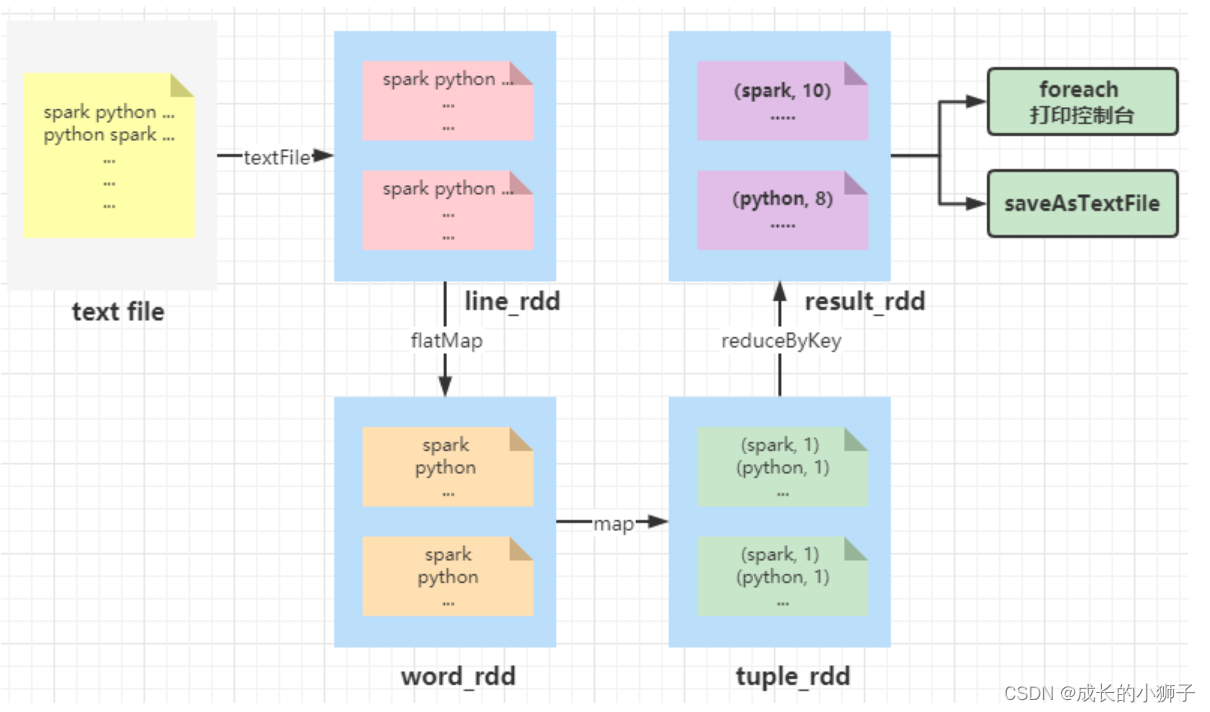
# 第一、加载本地文件系统文本文件
>>> input_rdd = sc.textFile("file:///root/words.txt")
>>> type(input_rdd)
<class 'pyspark.rdd.RDD'># 第二、每行数据按照空格分词并且进行扁平化
>>> word_rdd = input_rdd.flatMap(lambda line: line.split(" ")) # 第三、每个单词转换为二元组
>>> tuple_rdd = word_rdd.map(lambda word: (word, 1))# 第四、按照key单词分组,对组内数据求和
>>> result_rdd = tuple_rdd.reduceByKey(lambda tmp, item: tmp + item)# 第五、打印RDD集合中每条数据至控制台
>>> result_rdd.foreach(lambda item: print(item))
('python', 3)
('hive', 4)
('hadoop', 2)
('hdfs', 1)
('spark', 7)
('mapreduce', 2)# 第六、保存数据至本地文件系统文件中
result_rdd.saveAsTextFile("file:///root/wordcount-output")# 查看文件保存数据
(base) [root@node1 ~]# ll /root/wordcount-output/
total 8
-rw-r--r-- 1 root root 52 Sep 18 16:32 part-00000
-rw-r--r-- 1 root root 30 Sep 18 16:32 part-00001
-rw-r--r-- 1 root root 0 Sep 18 16:32 _SUCCESS(base) [root@node1 ~]# more /root/wordcount-output/part-00000
('python', 3)
('hive', 4)
('hadoop', 2)
('hdfs', 1)(base) [root@node1 ~]# more /root/wordcount-output/part-00001
('spark', 7)
('mapreduce', 2)
浏览器打开WEB UI监控页面:http://node1.itcast.cn:4040,首页显示运行完成Job:

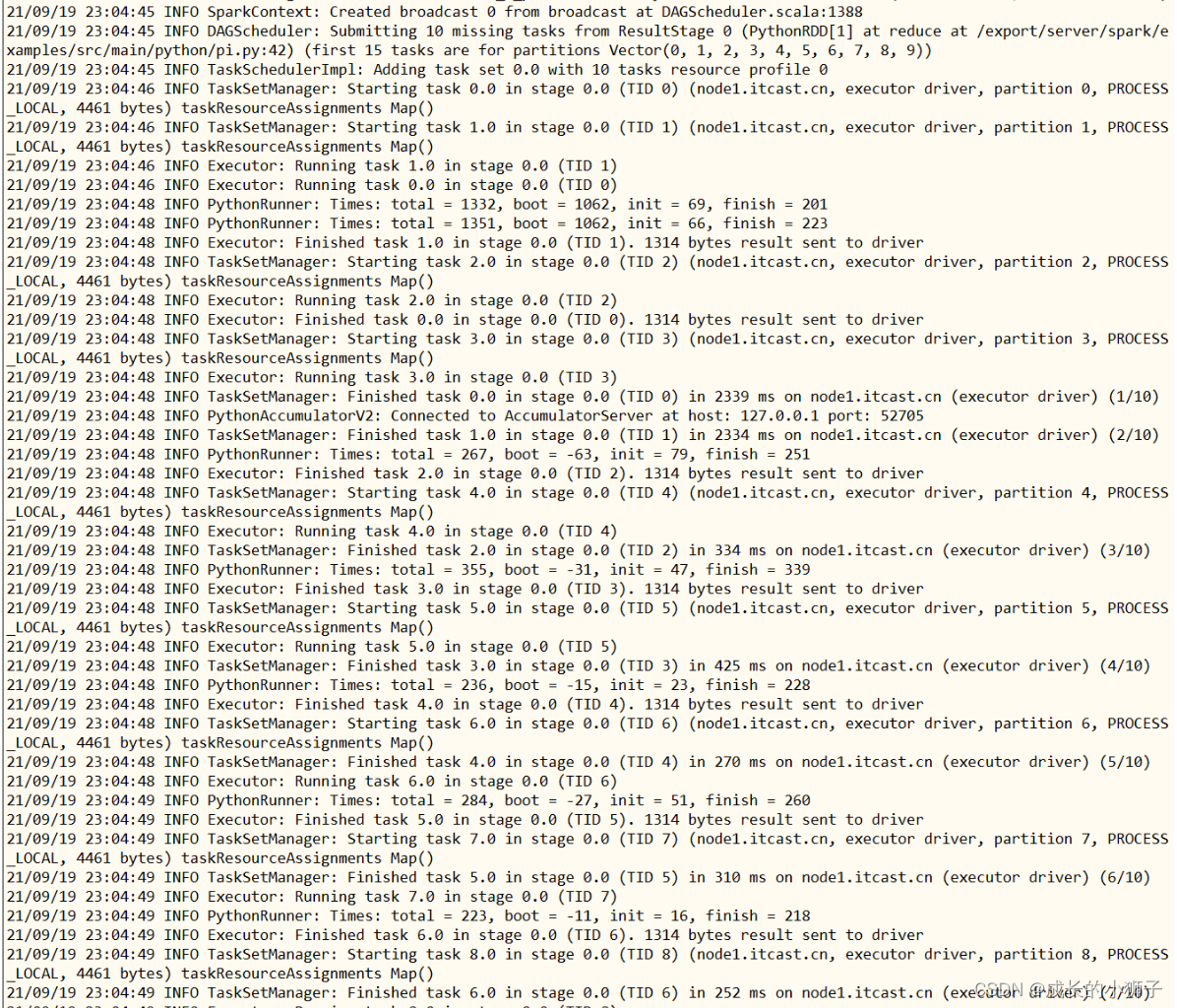
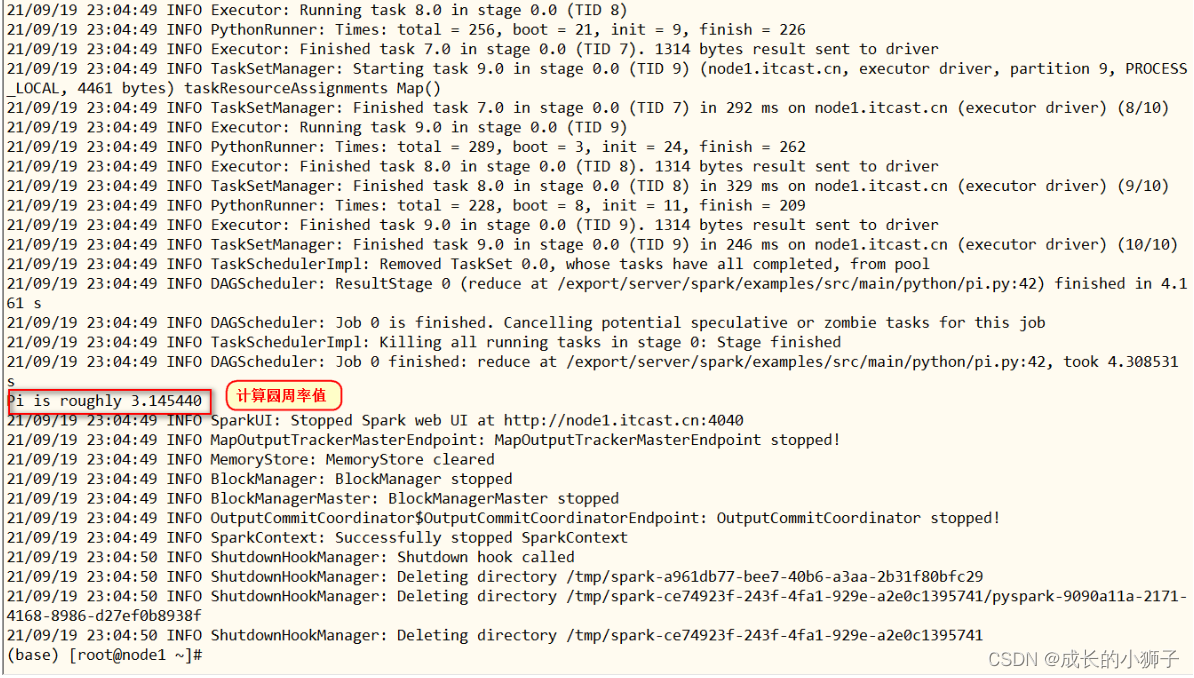
04_Spark 快速入门【运行圆周率PI】[了解]

Hadoop MapReduce中运行圆周率PI,本地模式运行,提交命令
/export/server/hadoop/bin/yarn jar \
/export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar \
pi \
-Dmapreduce.framework.name=local \
-Dfs.defaultFS=file:/// \
10 10000# 第一个参数:10,表示运行10个MapTask任务
# 第二个参数:10000,表示每个MapTask任务投掷次数
# -D设置属性参数值:MapReduce运行本地模式local和文件系统为本地文件系统file
Spark框架自带的案例Example中涵盖圆周率PI计算程序,可以使用【
$SPARK_HOME/bin/spark-submit】提交应用执行,运行在本地模式localmode。
使用spark-submit脚本,提交运行圆周率PI,采用蒙特卡罗算法。
/export/server/spark-local/bin/spark-submit \
--master local[2] \
/export/server/spark-local/examples/src/main/python/pi.py \
10

第二部分:Standalone 集群【4个小节】
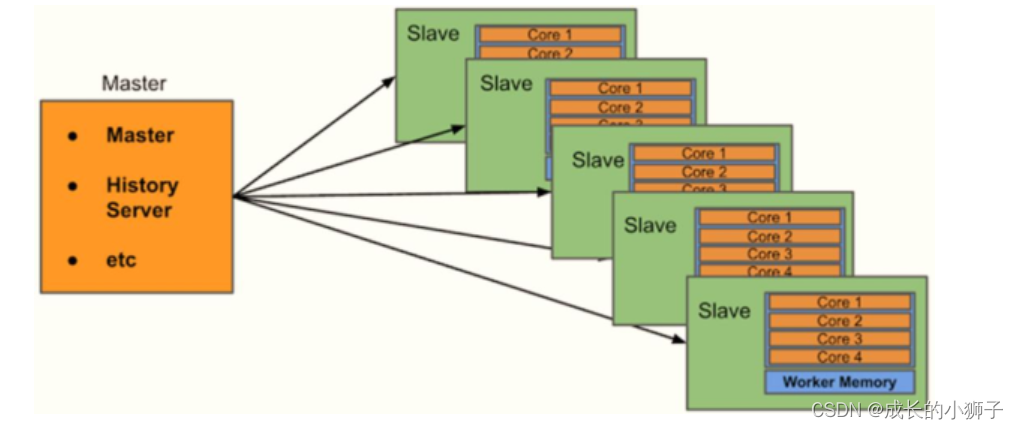
05_Standalone 集群【架构及安装部署】[理解]
Standalone集群使用了分布式计算中的
master-slave模型,master是集群中含有Master进程的节点,slave是集群中的Worker节点含有Executor进程。Spark Standalone集群,仅仅只能向其提交运行Spark Application程序,其他应用无法提交运行
- 主节点:
Master,管理整个集群的资源,类似Hadoop YARN中ResourceManager - 从节点:
Workers,管理每台机器的资源(内存和CPU)和执行任务Task,类似Hadoop YARN中NodeManager
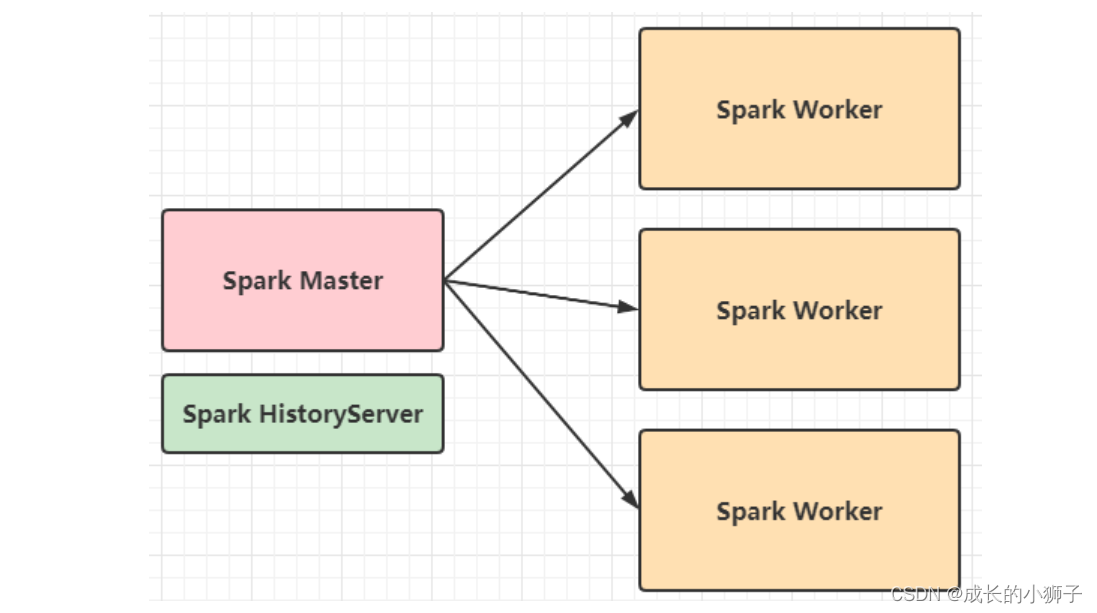
Spark Standalone集群,类似Hadoop YARN集群,管理集群资源和调度资源:

Standalone 集群资源配置,使用三台虚拟机,安装CentOS7操作系统。
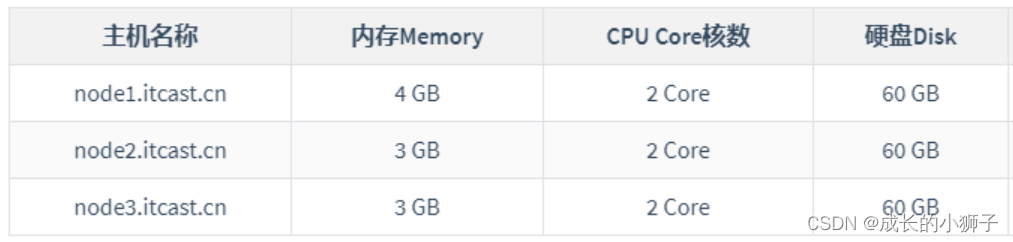
Standalone 集群服务规划,1个Master主节点、3个Workers从节点和1个历史服务节点,Master主节点和HistoryServer历史服务节点往往在一台机器上。

Standalone集群配置,在
node1.itcast.cn机器上配置,分发到集群其他机器。
- 1、框架安装包上传解压
# 第一、进入软件安装目录
(base) [root@node1 ~]# cd /export/server/# 第二、上传框架软件包
(base) [root@node1 server]# rz# 第三、赋予执行权限
(base) [root@node1 server]# chmod u+x spark-3.1.2-bin-hadoop3.2.tgz # 第四、解压软件包
(base) [root@node1 server]# tar -zxf spark-3.1.2-bin-hadoop3.2.tgz # 第五、赋予root用户和组
(base) [root@node1 server]# chown -R root:root spark-3.1.2-bin-hadoop3.2# 第六、重命名为spark-local
(base) [root@node1 server]# mv spark-3.1.2-bin-hadoop3.2 spark-standalone
-
2、配置Master、Workers、HistoryServer
在配置文件**
$SPARK_HOME/conf/spark-env.sh**,添加如下内容:
## 第一、进入配置目录
cd /export/server/spark-standalone/conf## 第二、修改配置文件名称
mv spark-env.sh.template spark-env.sh## 第三、修改配置文件
vim spark-env.sh
## 增加如下内容:## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk## HADOOP软件配置文件目录
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop## 指定Master主机名称和端口号
SPARK_MASTER_HOST=node1.itcast.cn
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080## 指定Workers资源和端口号
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081## 历史日志服务器
SPARK_DAEMON_MEMORY=1g
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1.itcast.cn:8020/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
-
3、创建EventLogs存储目录
先确定HDFS服务启动,再创建事件日志目录
# 第一、在node1.itcast.cn启动服务
(base) [root@node1 ~]# hadoop-daemon.sh start namenode
(base) [root@node1 ~]# hadoop-daemons.sh start datanode
# 启动后,浏览器输入:http://node1.itcast.cn:9870/,确定启动成功,离开安全模式# 第二、创建EventLog目录
(base) [root@node1 ~]# hdfs dfs -mkdir -p /spark/eventLogs/
-
4、Workers节点主机名称
将
$SPARK_HOME/conf/workers.template名称命名为【workers】,填写从节点名称。
## 第一、进入配置目录
cd /export/server/spark-standalone/conf## 第二、修改配置文件名称
mv workers.template workers## 第三、编辑和添加内容
vim workers
##内容如下:
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
-
5、配置Spark应用保存EventLogs
将
$SPARK_HOME/conf/spark-defaults.conf.template重命名为**spark-defaults.conf**,添加内容:
## 第一、进入配置目录
cd /export/server/spark-standalone/conf## 第二、修改配置文件名称
mv spark-defaults.conf.template spark-defaults.conf## 第三、添加应用运行默认配置
vim spark-defaults.conf
## 添加内容如下:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1.itcast.cn:8020/spark/eventLogs
spark.eventLog.compress true
-
6、设置日志级别
将
$SPARK_HOME/conf/log4j.properties.template重命名为log4j.properties,修改日志级别为警告**WARN**。
## 第一、进入目录
cd /export/server/spark-standalone/conf## 第二、修改日志属性配置文件名称
mv log4j.properties.template log4j.properties## 第三、改变日志级别
vim log4j.properties
## 修改内容: 第19行
log4j.rootCategory=WARN, console
-
7、分发到其他机器
将配置好的将 Spark 安装包分发给集群中其它机器
scp -r /export/server/spark-standalone root@node2.itcast.cn:/export/server/
scp -r /export/server/spark-standalone root@node3.itcast.cn:/export/server/
06_Standalone 集群【服务启动及测试】[理解]
启动Spark Standalone 集群服务,在主节点
node1.itcast.cn上先启动Master服务,再启动Workers服务,最后启动历史服务HistoryServer。必须配置主节点到所有从节点的SSH无密钥登录,集群各个机器时间同步。
- 1、主节点Master服务
## 启动Master服务
/export/server/spark-standalone/sbin/start-master.sh## 停止Master服务
/export/server/spark-standalone/sbin/stop-master.sh
- 2、从节点Workers服务
## 启动Workers服务
/export/server/spark-standalone/sbin/start-workers.sh## 停止Workers服务
/export/server/spark-standalone/sbin/stop-workers.sh

- 3、Master监控UI界面
- 主节点Master主节点WEB UI服务地址:http://node1.itcast.cn:8080/

监控页面可以看出,配置3个Worker进程实例,每个Worker实例为1核1GB内存,总共是3核 3GB 内存。目前显示的Worker资源都是空闲的,当向Spark集群提交应用之后,Spark就会分配相应的资源给程序使用,可以在该页面看到资源的使用情况。
- 4、启动历史服务
## 启动HistoryServer服务
/export/server/spark-standalone/sbin/start-history-server.sh## 停止HistoryServer服务
/export/server/spark-standalone/sbin/stop-history-server.sh
案例运行(1):圆周率PI运行
将圆周率PI程序,提交运行在Standalone集群上,修改【--master】为Standalone集群地址:spark://node1.itcast.cn:7077
/export/server/spark-standalone/bin/spark-submit \
--master spark://node1.itcast.cn:7077 \
--conf "spark.pyspark.driver.python=/export/server/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/export/server/anaconda3/bin/python3" \
/export/server/spark-standalone/examples/src/main/python/pi.py \
10## 属性参数:spark.pyspark.driver.python和spark.pyspark.python,指定python解析器位置
案例运行(2):词频统计WordCount
- 数据文件:
vim /root/words.txt
spark python spark hive spark hive
python spark hive spark python
mapreduce spark hadoop hdfs hadoop spark
hive mapreduce
- 上传HDFS文件系统
# 创建目录
hdfs dfs -mkdir -p /datas/input
# 上传文件
hdfs dfs -put /root/words.txt /datas/input
- 启动
pyspark shell交互式命令行
/export/server/spark-standalone/bin/pyspark \
--master spark://node1.itcast.cn:7077 \
--conf "spark.pyspark.driver.python=/export/server/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/export/server/anaconda3/bin/python3"
- 词频统计WordCount:
# 第一、加载HDFS文件系统文本文件
input_rdd = sc.textFile("hdfs://node1.itcast.cn:8020/datas/input/words.txt")
input_rdd.collect()"""
第二、词频统计2-1. 每行数据按照空格分词并且进行扁平化2-2. 每个单词转换为二元组2-3. 按照key单词分组,对组内数据求和
"""
result_rdd = input_rdd\.flatMap(lambda line: line.split(" "))\.map(lambda word: (word, 1))\.reduceByKey(lambda tmp, item: tmp + item)
result_rdd.collect()# 第三、打印RDD集合中每条数据至控制台
result_rdd.foreach(lambda item: print(item))# 保存数据至本地文件系统文件中
result_rdd.saveAsTextFile("hdfs://node1.itcast.cn:8020/datas/wordcount-output")# 查看文件保存数据
hdfs dfs -ls /datas//wordcount-output
hdfs dfs -text /datas/wordcount-output/part-*07_Standalone 集群【应用运行架构】[掌握]
当将Spark Application运行在集群上时,所有组件组成如下所示,分为2个部分:
- 第一部分、集群资源管理框架,比如Standalone 集群
- 第二部分、每个应用组成,应用管理者和应用执行者
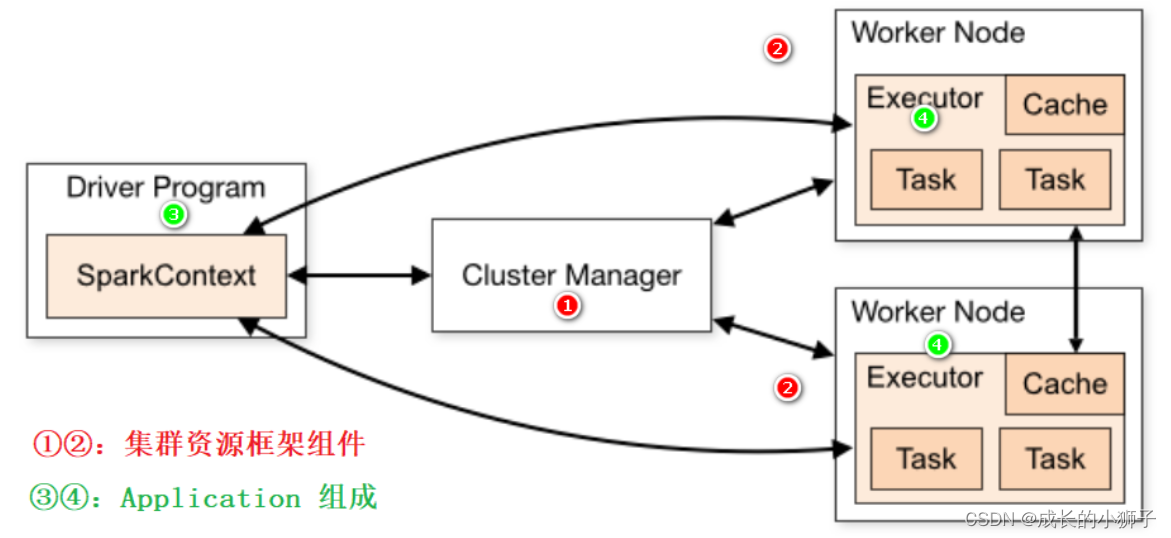
第一部分、集群资源管理框架,以Standalone 集群为例
- 主节点Master:集群老大,管理节点
- 接受客户端请求、管理从节点Worker节点、资源管理和任务调度
- 类似YARN中ResourceManager
- 从节点Workers:集群小弟,工作节点
- 使用自身节点的资源运行Executor进程:给每个Executor分配一定的资源
- 类似YARN中NodeManager
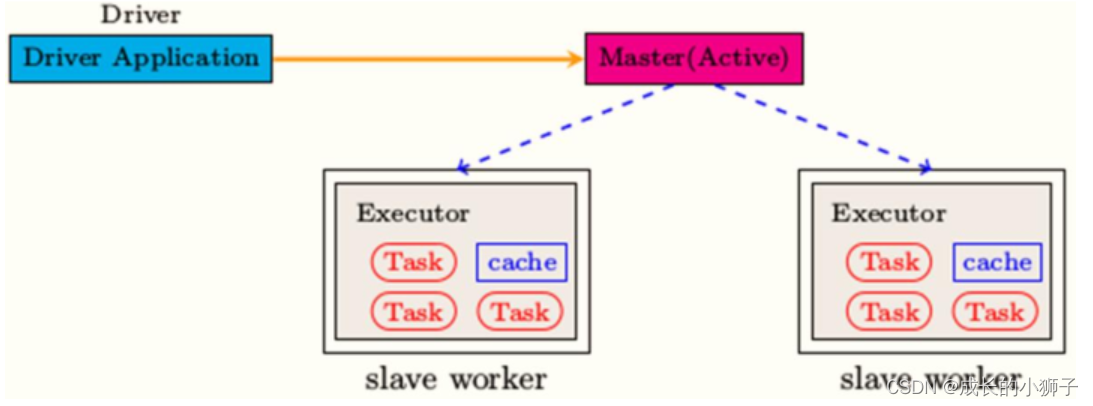
第二部分、每个应用组成,应用管理者Driver和应用执行者Executors
- 应用管理者Driver Program:每个应用老大
- 向主节点申请Executor资源,让主节点在从节点上根据需求配置启动对应的Executor
- 解析代码逻辑:将代码中的逻辑转换为Task
- 将Task分配给Executor去运行
- 监控每个Executor运行的Task状态
- 应用执行者Executors:应用中干活的
- 运行在Worker上,使用Worker分配的资源等待运行Task
- 所有Executor启动成功以后会向Driver进行注册
- Executor收到分配Task任务,运行Task
- 可以将RDD数据缓存到Executor内存
登录Spark HistoryServer历史服务器WEB UI界面,点击前面运行圆周率PI程序:
历史服务器网址:http://node1.itcast.cn:18080/
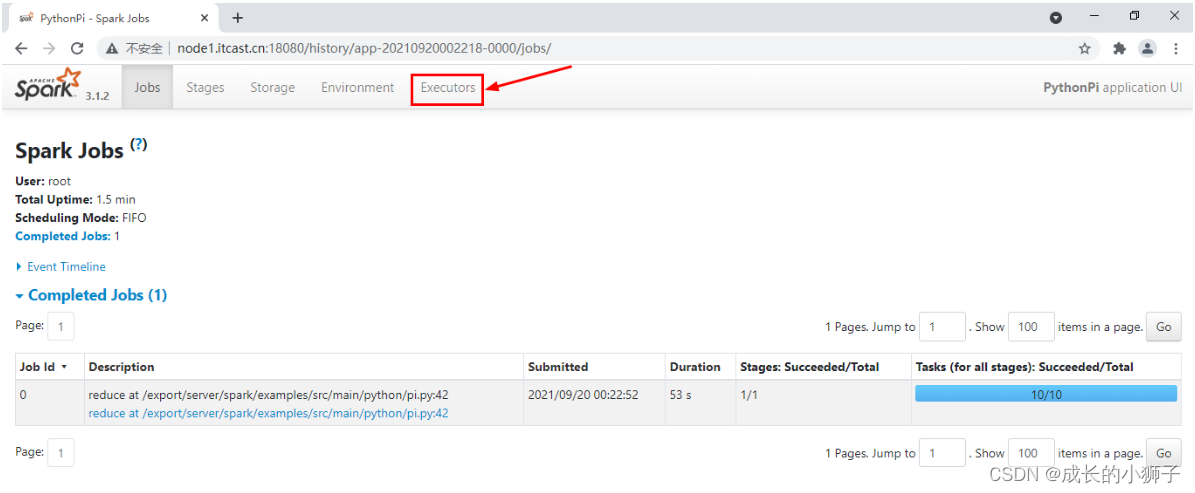
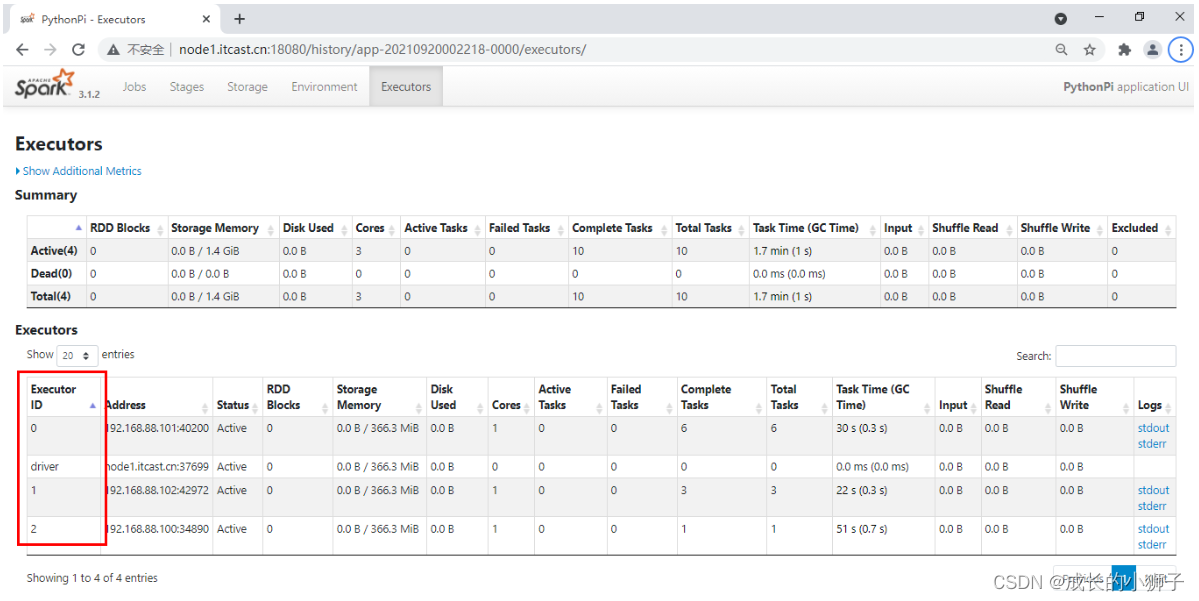
切换到【Executors】Tab页面:
08_Standalone 集群【高可用HA】[了解]
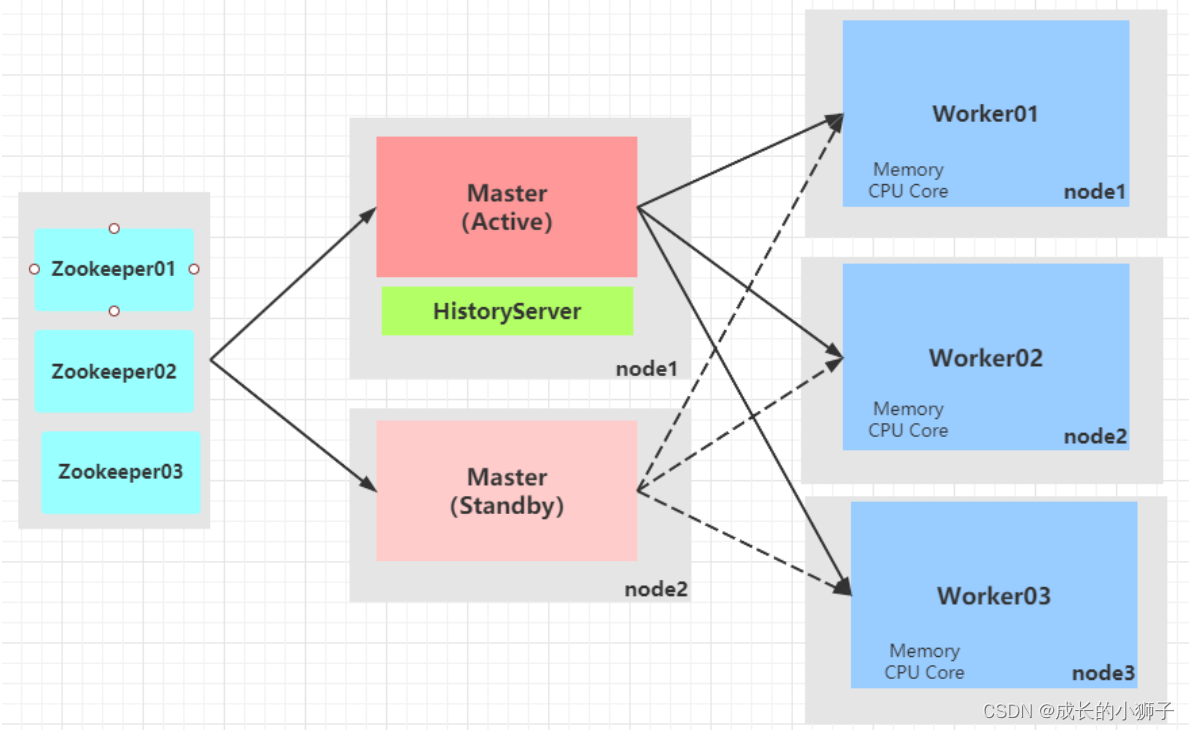
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。
基于
Zookeeper的Standby Masters机制实现高可用High Available,其中ZooKeeper提供了一个Leader Election机制,可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。
官方文档:https://spark.apache.org/docs/3.1.2/spark-standalone.html#standby-masters-with-zookeeper
Spark提供高可用HA方案:运行2个或多个Master进程,其中一个是Active状态:正常工作,其余的为Standby状态:待命中,一旦Active Master出现问题,立刻接上。
- 1、停止Sprak集群
(base) [root@node1 ~]# /export/server/spark-standalone/sbin/stop-all.sh ## 复制1份spark-standalone为spark-ha
cp -r /export/server/spark-standalone /export/server/spark-ha
- 2、修改配置文件:
spark-env.sh,在node1.itcast.cn上执行
## 编辑配置文件
vim /export/server/spark-ha/conf/spark-env.sh
### 注释或删除MASTER_HOST内容
SPARK_MASTER_HOST=node1.itcast.cn### 增加配置
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1.itcast.cn:2181,node2.itcast.cn:2181,node3.itcast.cn:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"### 参数含义说明
spark.deploy.recoveryMode:恢复模式
spark.deploy.zookeeper.url:ZooKeeper的Server地址
spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。包括Worker、Driver、Application信息
- 3、直接将配置完成HA目录:spark-ha,发送到集群所有节点
scp -r /export/server/spark-ha root@node2.itcast.cn:/export/server
scp -r /export/server/spark-ha root@node3.itcast.cn:/export/server
- 4、启动Zookeeper集群服务
## node1、node2和node3 分别启动Zookeeper服务
/export/server/zookeeper/bin/zkServer.sh start## 查看服务状态
/export/server/zookeeper/bin/zkServer.sh status

- 5、启动Master服务,分别在node1.itcast.cn和node2.itcast.cn机器
/export/server/spark-ha/sbin/start-master.sh
服务启动以后,分别打开node1和node2上Master WEB UI监控业务,查看哪个时Alive状态。

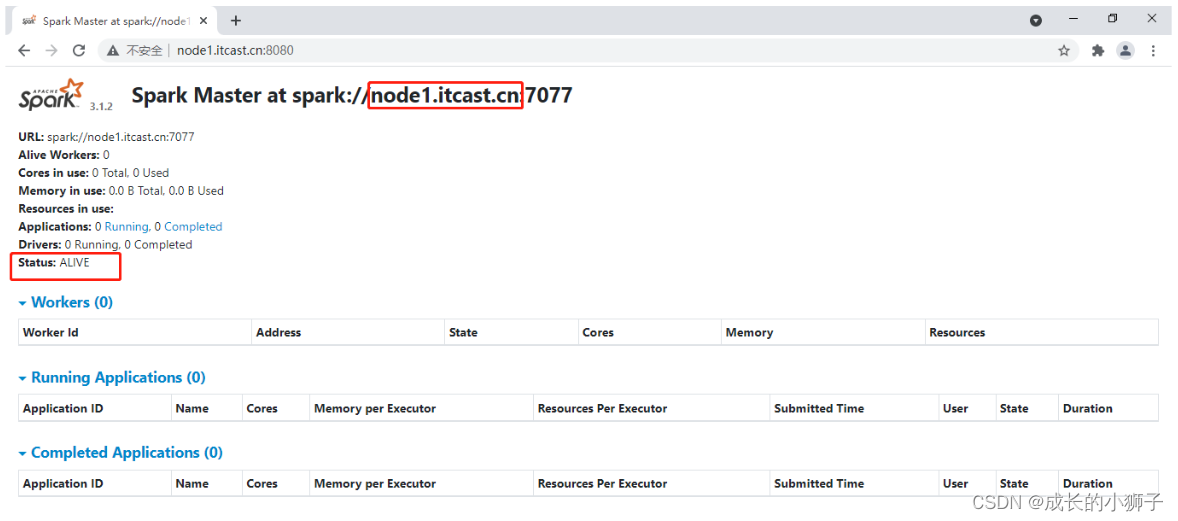
-
6、启动Workers服务
在Master为Alive机器上,启动Workers服务
/export/server/spark-ha/sbin/start-workers.sh
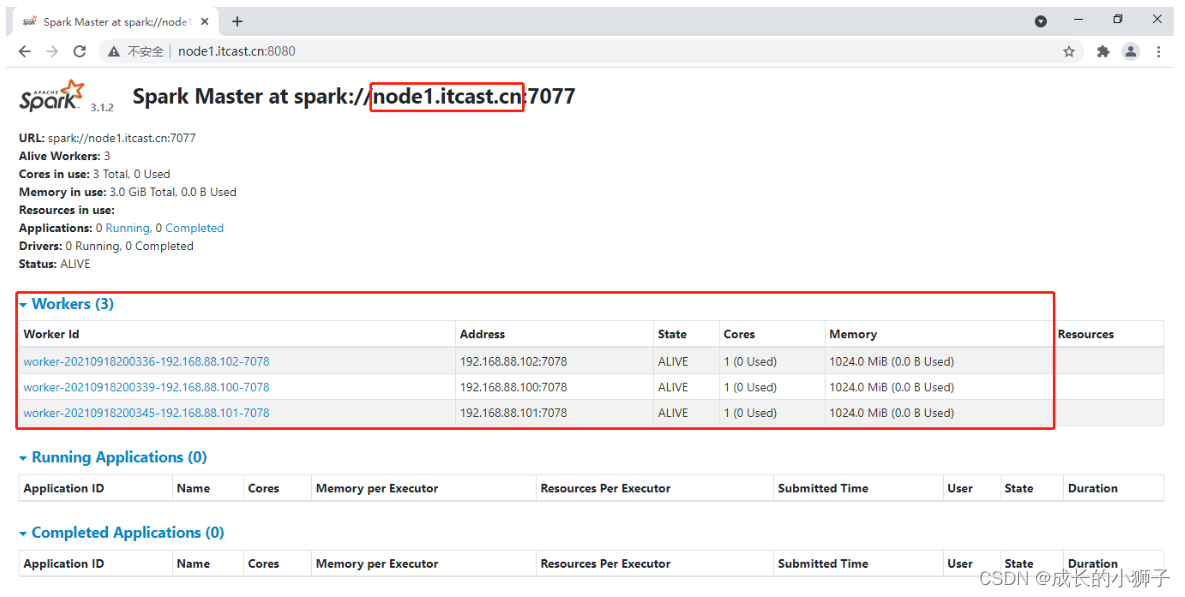
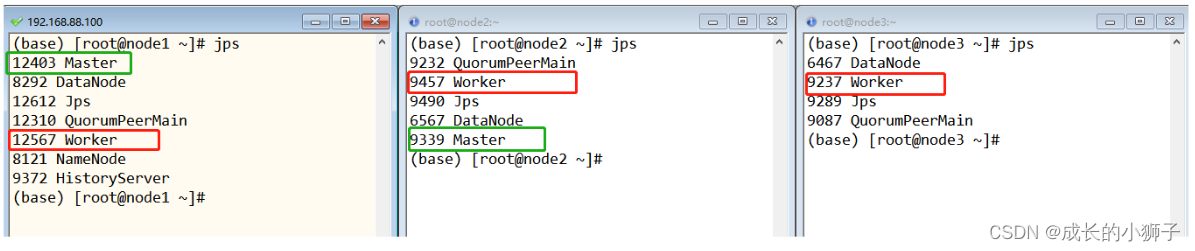
查看node1、node2和node3,三台机器上进程,如下截图:
测试主备切换步骤:
- 第一、在
node1.itcast.cn上使用jps查看master进程id - 第二、使用
kill -9 id号强制结束该进程 - 第三、稍等片刻后刷新
node2.itcast.cn的WEB界面发现为Alive
Standalone HA集群运行应用时,指定master参数值为:
--master spark://host1:port1,host2:port2
/export/server/spark-ha/bin/spark-submit \
--master spark://node1.itcast.cn:7077,node2.itcast.cn:7077 \
--conf "spark.pyspark.driver.python=/export/server/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/export/server/anaconda3/bin/python3" \
/export/server/spark-ha/examples/src/main/python/pi.py \
10
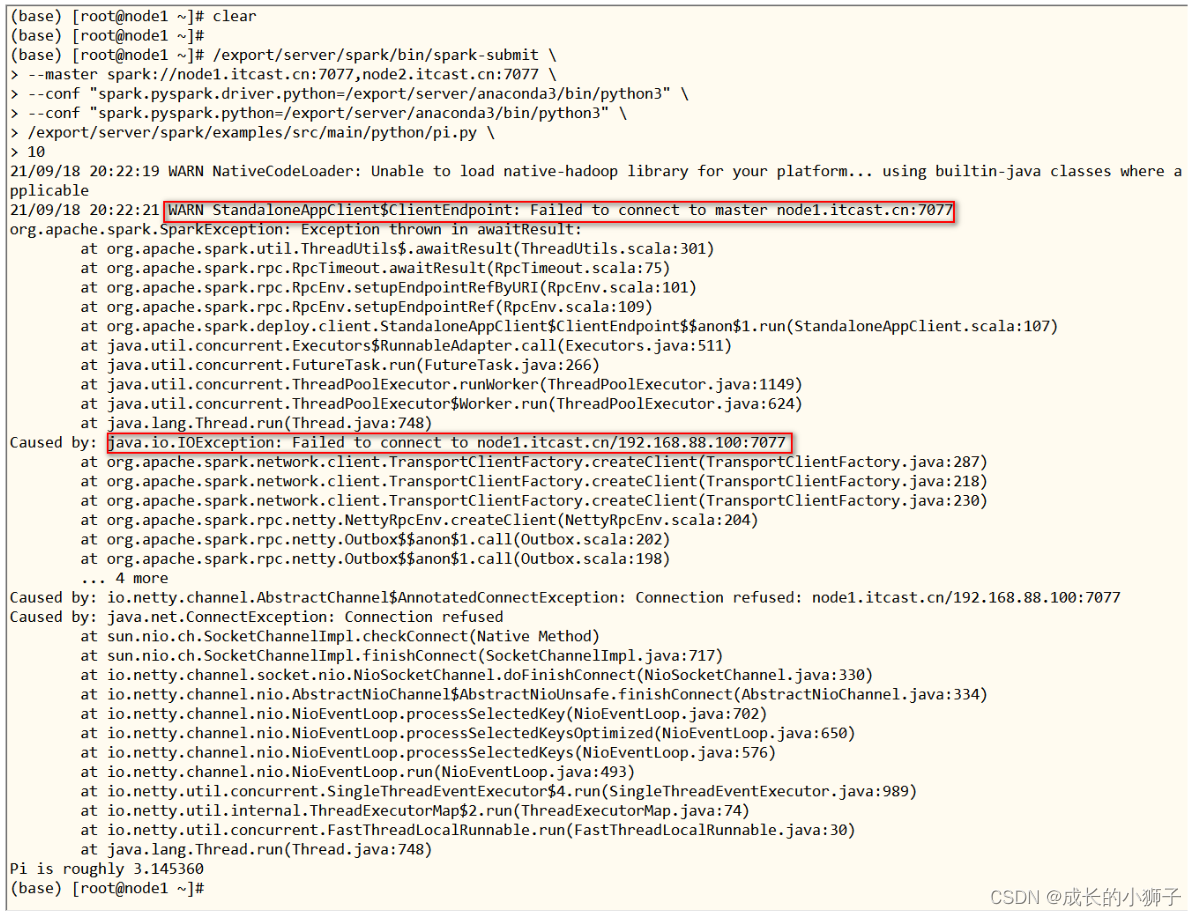
圆周率应用运行时,将Active Master主节点进程直接kill掉,观察应用运行最终结束。
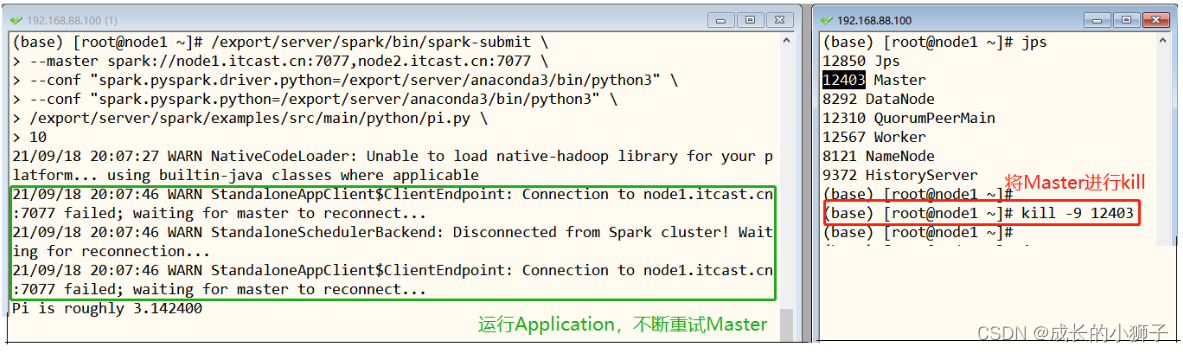
稍等一段时间(1-2分钟)刷新node2机器上Master界面,状态已经由Standby变为Alive。

再次运行上述圆周率PI应用程序,依然成功,但是会有警告:连接不到node1.itcast.cn:7077
[附录]-导入提供好的虚拟机:略
这篇关于2022-02-09大数据学习日志——PySpark——Spark快速入门Standalone集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




