本文主要是介绍Spark1.0.2 Standalone 模式部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
节点说明
| IP | 用户名 | 主机名 | 角色 |
|---|---|---|---|
| 10.6.2.109 | hadoop | client | Spark客户端 |
| 10.6.2.111 | hadoop | master | HDFS(NameNode,SecondNameNode);Spark(Master,Worker) |
| 10.6.2.112 | hadoop | worker1 | HDFS(DataNode);Spark(Worker) |
| 10.6.2.113 | hadoop | worker2 | HDFS(DataNode);Spark(Worker) |
节点说明:在10.6.2.111,10.6.2.112,10.6.2.113节点上应经搭建了hadoop-2.2.0完全分布式集群,具体教程见64位Centos6.5 Hadoop2.2.0 完全分布安装教程
1. Spark1.0.2 Standalone安装
1.1 下载安装包
从Spark官网上下载如图所示编译好的Spark安装包spark-1.0.2-bin-hadoop.tgz
注意:部署这个安装包的前提是已经安装好hadoop-2.2.0,否则会出现兼容问题
1.2 解压安装包
注意:以下操作均在10.6.2.111节点上
在当前用户目录下创建两个文件夹softwares和tar_package,将spark-1.0.2-bin-hadoop.tgz放置在 tar_package目录下,并解压到softwares目录下
cd ~/tar_package
tar -zxvf spark-1.0.2-bin-hadoop.tgz -C ~/softwares进入softwares文件夹可以看到解压后的文件夹spark-1.0.2-bin-hadoop,将spark-1.0.2-bin-hadoop重命名为spark-1.0.2
mv spark-1.0.2-bin-hadoop spark-1.0.21.3 配置
所需修改的配置文件除了spark-env.sh文件以外,还有slave文件,都位于conf目录中。
cd ~/softwares/spark-1.0.2/conf/
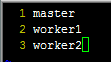
vim slaves添加下图所示内容,保存并退出
cp spark-env.sh.template spark-env.sh
vim spark-env.sh添加如下内容,保存并退出
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORE=3
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=3g注释:
- SPARK_MASTER_PORT:Master服务端口,默认为7077
- SPARK_WORKER_CORES:每个Worker进程所需要的CPU核的数目
- SPARK_WORKER_INSTANCES:每个Worker节点上运行Worker进程的数目
- SPARK_WORKER_MEMORY:每个Worker进程所需要的内存大小
将配置好的Spark文件拷贝至每个Spark集群的节点上的相同路径中
scp -r /home/hadoop/softwares hadoop@worker1:/home/hadoop/
scp -r /home/hadoop/softwares hadoop@worker2:/home/hadoop/
scp -r /home/hadoop/softwares hadoop@client:/home/hadoop/为方便使用spark-shell,可以在环境变量中配置上SPARK_HOME
回到用户当前目录下,编辑.bash_profile文件
cd
vim .bash_profile添加如下内容,保存并退出
export SPARK_HOME=/home/hadoop/softwares/spark-1.0.2
export PATH=$PATH:$SPARK_HOME/bin然后source一下
source .bash_profile注意:在每个节点上都要设置.bash_profile文件
1.4 启动
在10.6.2.111节点上启动spark standalone集群
cd ~/softwares/spark-1.0.2/sbin
ls
./start-all.sh
jps可以看到一个Jps进程,一个Master进程,一个Worker进程
在10.6.2.112上输入jps看到一个Jps进程,一个Worker进程
在10.6.2.113上输入jps看到一个Jps进程,一个Worker进程
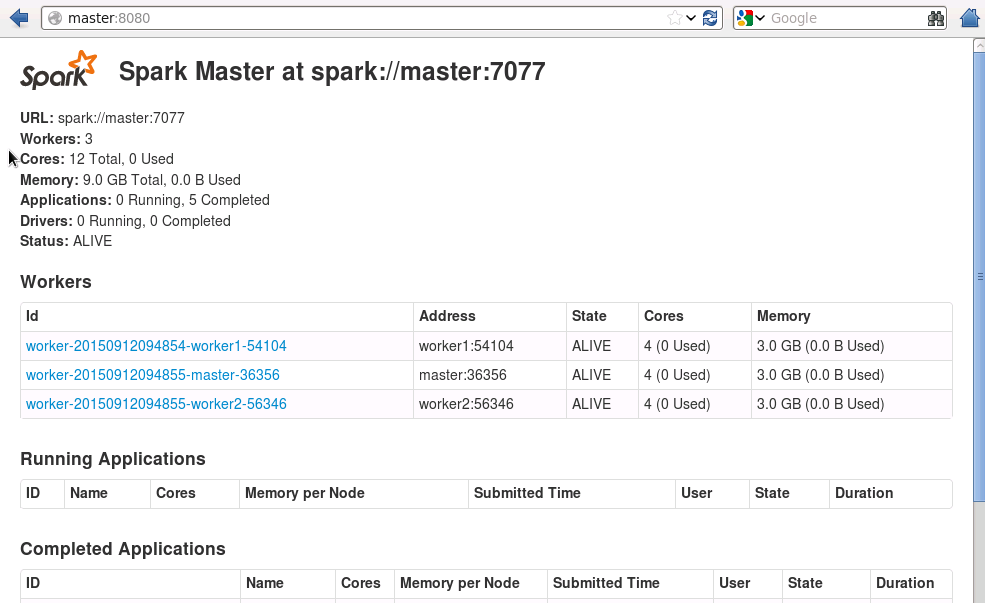
在10.6.2.111节点上,通过浏览器访问http://master:8080可以监控spark Standalone集群
2. Spark1.0.2 Standalone HA的实现
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题。如何解决这个单点故障的问题,Spark提供了两种方案:
- 基于文件系统的单点恢复
- 基于zookeeper的Standby Masters
基于文件系统的单点恢复主要用于开发或测试环境下。基于zookeeper的Standby Masters用于生产模式下。本文档采用 基于zookeeper的Standby Masters。
2.1 安装zookeeper
2.1.1 下载安装包
zookeeper-3.4.6下载地址
2.1.2 解压安装包
注意:以下操作均在10.6.2.111节点上
将zookeeper-3.4.6.tar.gz放置在 tar_package目录下,并解压到softwares目录下
cd ~/tar_package
tar -zxvf zookeeper-3.4.6.tar.gz -C ~/softwares2.1.3 配置
cd ~/softwares/zookeeper-3.4.6/conf
ls
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg添加如下内容,保存并退出
dataDir=/home/hadoop/softwares/zookeeper-3.4.6/data
dataLogDir=/home/hadoop/softwares/zookeeper-3.4.6/datalog
server.1=master:2888:3888
server.2=worker1:2888:3888
server.3=worker2:2888:3888然后回到zookeeper-3.4.6目录下进行操作
cd ..
mkdir data
mkdir datalog
echo 1 > data/myid将配置好的zookeeper文件拷贝至每个集群每个节点上的相同路径中并修改每个节点的myid
scp -r /home/hadoop/softwares/zookeeper-3.4.6 hadoop@worker1:/home/hadoop/softwares
scp -r /home/hadoop/softwares/zookeeper-3.4.6 hadoop@worker2:/home/hadoop/softwares
在10.6.2.112节点上,在用户当前目录下
cd ~/softwares/zookeeper-3.4.6/
echo 2 > data/myid在10.6.2.113节点上,在用户当前目录下
cd ~/softwares/zookeeper-3.4.6/
echo 3 > data/myid2.1.4 启动zookeeper
在10.6.2.111节点上,在用户当前目录下
cd ~/softwares/zookeeper-3.4.6/bin
./zkServer.sh start在10.6.2.112,10.6.2.113进行同样的操作启动zookeeper。
启动完成后,在每个节点上jps可以看到 QuorumPeerMain进程。
2.2 重新配置spark-env.sh文件
注意:以下操作均在10.6.2.111节点上
cd ~/softwares/spark-1.0.2/sbin/
./stop-all.sh
cd ~/softwares/spark-1.0.2/conf/
vim spark-env.sh添加如下内容,注释掉export SPARK_MASTER_IP=master export SPARK_MASTER_PORT=7077这两行,保存并退出
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,worker1:2181 ,worker2:2181 -Dspark.deploy.zookeeper.dir=/spark"将配置spark-env.sh文件发放给各节点
scp spark-env.sh hadoop@worker1:/home/hadoop/softwares/spark-1.0.2/conf/
scp spark-env.sh hadoop@worker2:/home/hadoop/softwares/spark-1.0.2/conf/在10.6.2.111节点上启动spark standalone集群
cd ~/softwares/spark-1.0.2/sbin
ls
./start-all.sh再在10.6.2.112节点上启动Master进程
cd ~/softwares/spark-1.0.2/sbin
ls
./start-master.sh在10.6.2.111节点上,通过浏览器访问http://master:8080和http://worker1:8080,如下图所示
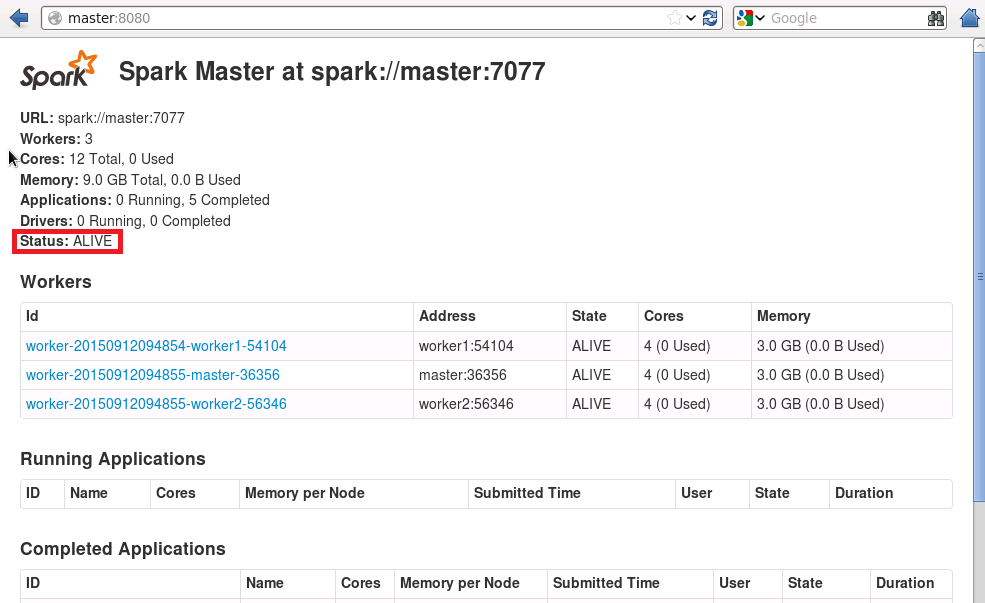
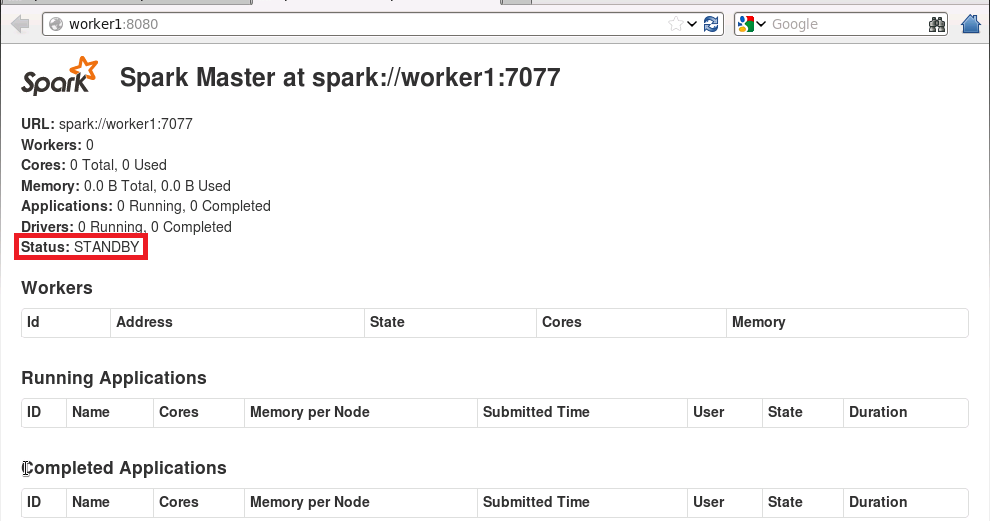
10.6.2.111节点上的Master进程的状态是alive,10.6.2.112节点上的Master进程的状态是standby。
一旦10.6.2.111节点上的Master进程关闭,10.6.2.112节点上的Master进程的状态会变成alive。
这篇关于Spark1.0.2 Standalone 模式部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







