spider专题

暗链威胁与检测方法之Screaming Frog SEO Spider
尖叫青蛙, 网站暗链检测方法网站暗链是指那些隐藏在网页上,对普通用户不可见或难以察觉的超链接。这些链接可能被故意设置为与背景颜色相同、使用极小的字体、或通过CSS技巧使其隐藏,从而在视觉上对用户隐藏。暗链通常用于不良的SEO实践,如操纵搜索引擎排名,或链接到恶意网站。这种做法可能导致网站在搜索引擎中被降级或罚款,损害网站的可信度和用户体验 为了解决网站暗链,一次性筛选所有暗链 买了一个软件 Scr

spider-图片验证码自动识别
声明 本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途或非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! 图片验证码识别 在很多登录、注册、频繁操作等行为时,一般都会加入验证码的功能。 如果想要基于代码实现某些功能,就必须实现:自动识别验证码,然后再做其他功能。 识别 基于python模块 ddddocr 自动识别图片
![NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]](https://img-blog.csdnimg.cn/img_convert/bc38e06d7f0023955abf2015b4f51801.png)
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
Text-to-SQL(或者Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,NL)问题,转化为在关系型数据库中可以执行的结构化询语言(Structured Query Language,SQL),因此Text-to-SQL也可以被简写为NL2SQL。 输入:自然语言问题,比如“查询表t_user的相关信息,结
font-spider按需生成字体文件
font-spider可以全局安装,也可以单个项目内安装,使用npm run xxxx的形式 npm i font-spider"dev": "font-spider ./*.html" <!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=d
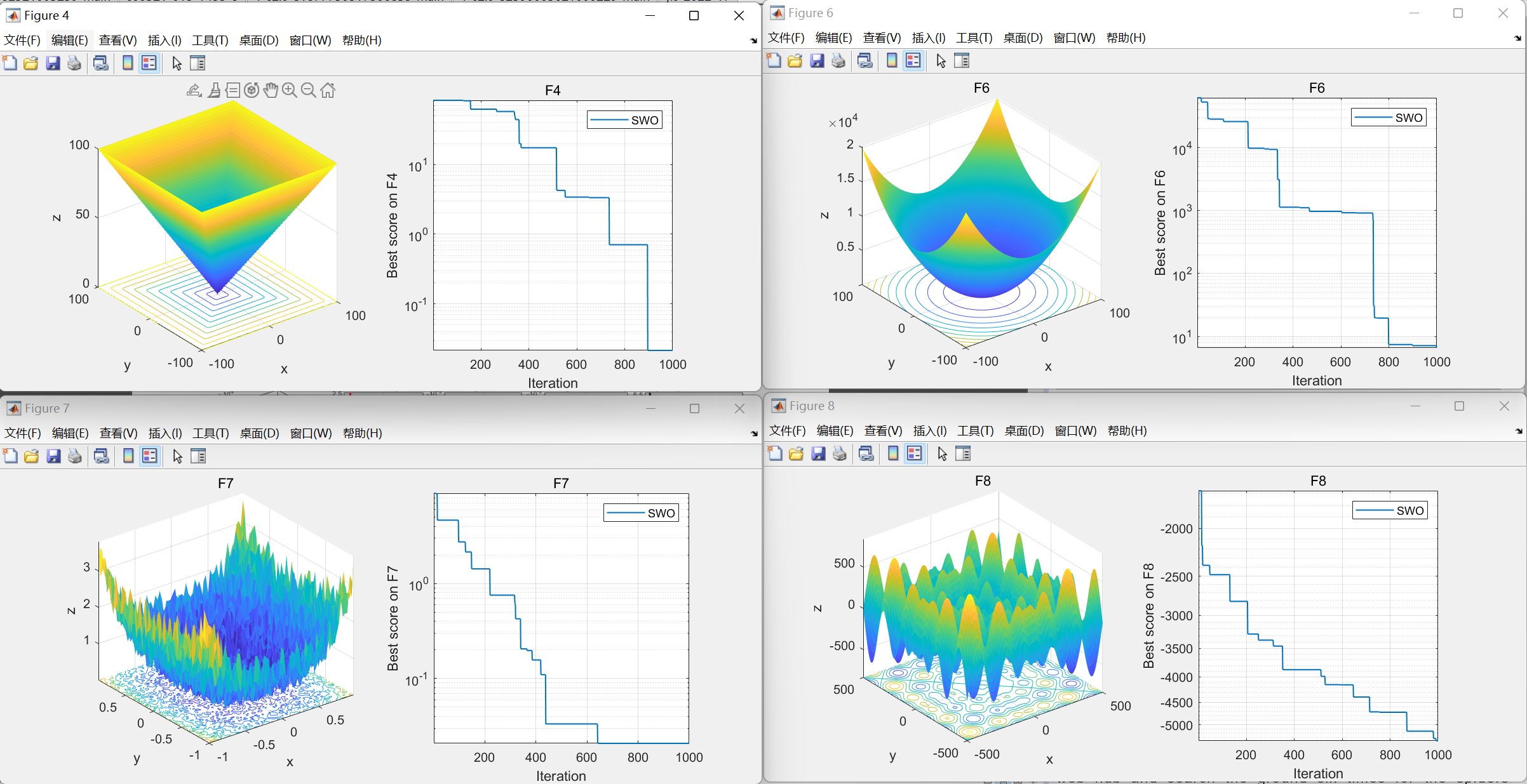
【智能优化算法】蛛蜂优化算法(Spider Wasp Optimizer,SWO)
蛛蜂优化算法(Spider Wasp Optimizer,SWO)是期刊“ARTIFICIAL INTELLIGENCE REVIEW”(中科院二区 IF=11.6)的2023年智能优化算法 01.引言 蛛蜂优化算法(Spider Wasp Optimizer,SWO)基于对自然界中雌性黄蜂的狩猎、筑巢和交配行为的复制。该算法具有多种独特的更新策略,适用于各种具有不同勘探开发要求的优化问题。

spider-java (Jsoup) (媒体信息的爬取)
媒体基础信息爬取实例 GetAppname.java (代码为hive的udf,静态页面的获取) package com.hb.hive.utils;import java.util.Random;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;import org.jsoup.Js

spider-python (媒体信息的爬取)
环境搭建 selenium-3.8.1+python2.7+chromedriver 具体的搭建方式请百度 参考: http://blog.csdn.net/zxy987872674/article/details/53082896 媒体基础信息爬取实例 app-spider.py # coding: UTF-8from selenium import webdr
Scrapy中的Spider Middleware
(一)Spider Middleware作用 Downloader生成的Response发送给Spider之前Spider生成的Request发送给Scheduler之前Spider生成的Item发送给ItemPipeline之前 (二)核心方法 process_spider_input(response,spider)process_spider_output(response,resul
Scrapy 中 SPIDER_MIDDLEWARES 和 DOWNLOADER_MIDDLEWARES 的区别
1. 下载中间件的方法 process_request(request,spider): 所有请求都会调用此方法process_response(request, response, spider): 这里的参数比上面的多了response,肯定是用来处理response的process_exception(request, exception, spider):处理异常from_crawler
解决scrapy爬虫框架多个spider指定pipeline
现在来看一个问题:当存在多个爬虫的时候如何指定对应的管道呢? 这里定义了两个爬虫:film、meiju 1.首先想到settings设置文件。 settings里针对item_pipelines的设置如下: 内置设置参考:ITEM_PIPELINES 默认: {} 包含要使用的项目管道及其顺序的字典。顺序值是任意的,但通常将它们定义在0-1000范围内。较低订单处理较高订单前。 例:
BurpSuite系列(三)----Spider模块(蜘蛛爬行)
一、简介 Burp Spider 是一个映射 web 应用程序的工具。它使用多种智能技术对一个应用程序的内容和功能进行全面的清查。 Burp Spider 通过跟踪 HTML 和 JavaScript 以及提交的表单中的超链接来映射目标应用程序,它还使用了一些其他的线索,如目录列表,资源类型的注释,以及 robots.txt 文件。结果会在站点地图中以树和表的形式显示出来,提供了一个清楚
Hello,Spider!入门第一个爬虫程序
在各大编程语言中,初学者要学会编写的第一个简单程序一般就是“Hello, World!”,即通过程序来在屏幕上输出一行“Hello, World!”这样的文字,在Python中,只需一行代码就可以做到。我们把这第一个爬虫就称之为“HelloSpider”,见下例。 import lxml.html,requestsurl = 'https://www.python.org/dev/peps/p
使用font-spider提取文字,压缩文字,减小文件大小
项目中遇到有特殊字体要求,且中文字体文件包比较大的时候,为了压缩字体文件一般有两种思路 一、让设计根据常用字将原文件筛选字体子集,只需要给出所需文字的字体包就好。 二、用font-spider对文字进行筛选子集生成新的字体文件-- 官网:font-spider.org - font spider 资源和信息。font-spider.org 是关于 font spider 信息的第一个最佳来源。
open-spider开源爬虫工具:抖音数据采集
在当今信息爆炸的时代,网络爬虫作为一种自动化的数据收集工具,其重要性不言而喻。它能够帮助我们从互联网上高效地提取和处理数据,为数据分析、市场研究、内容监控等领域提供支持。抖音作为一个全球性的短视频平台,拥有海量的用户生成内容,这些内容背后蕴含着巨大的数据价值。通过分析这些数据,企业和个人可以洞察流行趋势、用户偏好、市场动态等,从而做出更加精准的决策。 一、准备工作 在开始网络爬虫的实践之前,我
python学习之-用scrapy框架来创建爬虫(spider)
scrapy简单说明 scrapy 为一个框架 框架和第三方库的区别:库可以直接拿来就用,框架是用来运行,自动帮助开发人员做很多的事,我们只需要填写逻辑就好 命令:创建一个 项目 :cd 到需要创建工程的目录中,scrapy startproject stock_spider其中 stock_spider 为一个项目名称创建一个爬虫cd ./stock_spider/spiders
Scrapy(一):Spider框架
说道Python,估计很多同学跟我一样都是从学习Python的爬虫开始的。当然你可以使用lxml、BeautifulSoup、Request等第三方库来编写自己的爬虫。但是当需要爬取海量数据,特别是大数据的实际应用中,若自己编写爬虫,是一件特别困难的事情。还好Python提供了类似Scrapy等类似的爬虫框架。 1. Scrapy框架介绍 图1 Scrapy Spider 框架图
py spider 第一天
总结: selenium只是个虚拟的浏览器,或者说是一个web自动化测试工具,而不是真正意义上的爬虫框架 一、Scrapy Scrapy A Fast and Powerful Scraping and Web Crawling Framework 关键词是和,使用过确实感觉如此。我感觉就是一个全家桶,它把爬虫所需要的大部分东西(为什么不是全部,下面会说到)都集成到这个框架中,如:下载器、中
Spider Proxry /蜘蛛 非常实用的抓包教程
有需要规则定制的可以联系我qq:1219481875 最近又发现APP Store一款宝藏软件,Spider Proxy 抓包工具,app刚上架,功能不断迭代中,目前18软妹币实惠价可享受终身版!现在是下手的最好时机。 应用描述: Spider Proxy是一款移动端HTTP/HTTPS抓包及调试工具,支持不连接电脑的情况下,直接查看/修改iOS系统的HTTP(S)请求和响应,并支持对网
NodeJs爬虫框架-Spider
gz-spider 一个基于Puppeteer和Axios的NodeJs爬虫框架 源码仓库 为什么需要爬虫框架 爬虫框架可以简化开发流程,提供统一规范,提升效率。一套优秀的爬虫框架会利用多线程,多进程,分布式,IP池等能力,帮助开发者快速开发出易于维护的工业级爬虫,长期受用。 特性 可配置代理支持任务重试支持Puppeteer异步队列服务友好多进程友好 安装 npm i gz-sp
使用 font-spider 对 webfont 网页字体进行压缩
原文链接:使用 font-spider 对 webfont 网页字体进行压缩 随着当前 Web 技术的日新月异,网页界面内容越来越丰富,让人眼花缭乱,其中就包括了网页中的各种自定义字体。 例如,个人博客的首页字体: CSS3 引入的 @font-face 这一属性可以很好的解决这个问题,可以帮助我们非常灵活的使用一些特殊的字体,即使用户电脑里面没有安装这个字体,网页也可以显示。 EO
免费ttf文件压缩工具font-spider
一个ttf文件压缩工具font-spider npm i font-spider -g在一个文件夹中创建一个index.html,文件中引入需要压缩的ttf文件 <!DOCTYPE html><html lang="en"><head><meta charset="utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><me
Matlab数据挖掘工具箱 spider + Weka
http://blog.sciencenet.cn/home.php?mod=space&uid=242887&do=blog&id=263095 转自数据挖掘青年 http://blogger.org.cn/blog/more.asp?name=DMman&id=27375 一 spider主页http://www.kyb.mpg.de/bs/people/spider/ (也可以在

【Python网络爬虫入门教程2】成为“Spider Man”的第二课:观察目标网站、代码编写
Python 网络爬虫入门:Spider man的第二课 写在最前面观察目标网站代码编写 第二课总结 写在最前面 有位粉丝希望学习网络爬虫的实战技巧,想尝试搭建自己的爬虫环境,从网上抓取数据。 前面有写一篇博客分享,但是内容感觉太浅显了 【一个超简单的爬虫demo】探索新浪网:使用 Python 爬虫获取动态网页数据 本期邀请了擅长爬虫的朋友@PoloWitty,来撰写这篇博
Scrapy 下载器中间件、spider中间件
Scrapy 官方文档 ( 下载器中间件 ) :https://doc.scrapy.org/en/latest/topics/downloader-middleware.html:https://www.osgeo.cn/scrapy/topics/downloader-middleware.html Scrapy 扩展中间件: 针对特定响应状态码,使用代理重新请求:https://ww
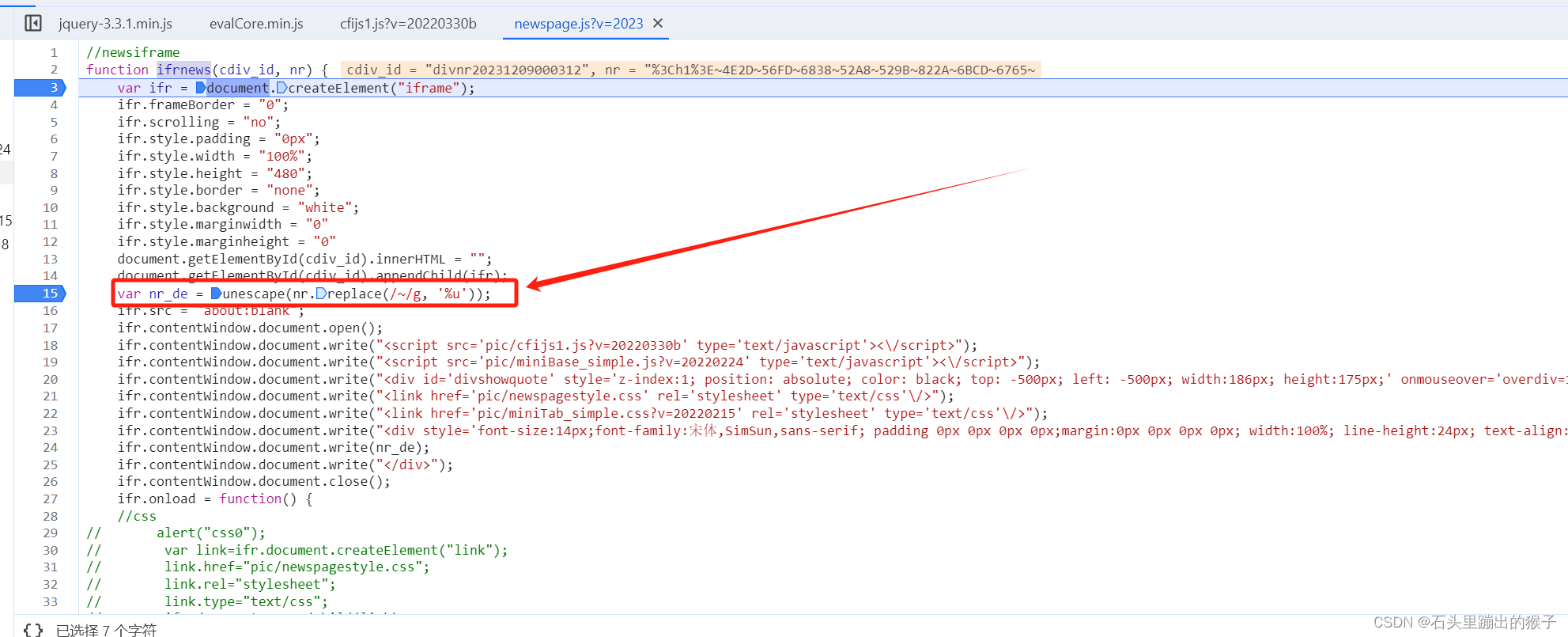
spider小案例~https://industry.cfi.cn/BCA0A4127A4128A4141.html
一、获取列表页信息 通过抓包发现列表页信息非正常返回,列表信息如下图: 通过观察发现列表页信息是通过unes函数进行处理的,我们接下来去看下该函数 该函数是对列表页的信息先全局替换"~"为"%u",然后再通过unescape函数对替换后的字符串进行解码,到此我们就可以获取到列表页的信息了,我们用Python来还原一下 import refrom urllib.parse
【Python网络爬虫入门教程2】成为“Spider Man”的第二课:观察目标网站、代码编写
Python 网络爬虫入门:Spider man的第二课 写在最前面观察目标网站代码编写 第二课总结 写在最前面 有位粉丝希望学习网络爬虫的实战技巧,想尝试搭建自己的爬虫环境,从网上抓取数据。 前面有写一篇博客分享,但是内容感觉太浅显了 【一个超简单的爬虫demo】探索新浪网:使用 Python 爬虫获取动态网页数据 本期邀请了擅长爬虫的朋友@PoloWitty,来撰写这篇博