本文主要是介绍open-spider开源爬虫工具:抖音数据采集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在当今信息爆炸的时代,网络爬虫作为一种自动化的数据收集工具,其重要性不言而喻。它能够帮助我们从互联网上高效地提取和处理数据,为数据分析、市场研究、内容监控等领域提供支持。抖音作为一个全球性的短视频平台,拥有海量的用户生成内容,这些内容背后蕴含着巨大的数据价值。通过分析这些数据,企业和个人可以洞察流行趋势、用户偏好、市场动态等,从而做出更加精准的决策。
一、准备工作
在开始网络爬虫的实践之前,我们需要做好充分的准备工作。首先,确保你的计算机上安装了Python环境,这是进行网络爬虫开发的基础。接下来,你需要安装一些必要的Python库,如requests用于发送HTTP请求,BeautifulSoup用于解析HTML文档,以及Selenium用于模拟浏览器行为。此外,使用Selenium时,还需要下载对应浏览器的WebDriver,以便自动化地操作浏览器。
pip install requests beautifulsoup4pip install selenium
然后,你可以使用以下Python代码作为起点:
import requests
from bs4 import BeautifulSoup# 抖音的URL
url = 'https://www.douyin.com'# 发送HTTP请求
response = requests.get(url)# 确保请求成功
if response.status_code == 200:# 解析HTML内容soup = BeautifulSoup(response.text, 'html.parser')# 打印页面标题print("页面标题:", soup.title.string)# 找到所有的视频链接(这里假设视频链接包含在特定的标签中)video_links = soup.find_all('a', href=True) # 根据实际情况调整选择器for link in video_links:print("视频链接:", link['href'])
else:print("请求失败,状态码:", response.status_code)二、静态内容抓取
静态内容抓取是指从网页中直接提取信息的过程。这通常涉及到以下几个步骤:
使用requests库发送HTTP请求,获取网页的原始数据。例如,你可以使用requests.get(url)来获取抖音首页的HTML内容。
利用BeautifulSoup库对获取到的HTML进行解析。BeautifulSoup提供了丰富的方法来处理和提取HTML文档中的数据。例如,你可以使用find()或find_all()方法来定位特定的HTML元素。
实例:抓取抖音首页信息。首先,使用requests获取抖音首页的HTML。然后,创建一个BeautifulSoup对象来解析这些HTML。接下来,你可以遍历页面元素,提取出你感兴趣的信息,如视频标题、用户信息、点赞数等。
如果你需要处理JavaScript动态加载的内容,你可以使用以下代码作为起点:
from selenium import webdriver# 设置Selenium驱动
driver = webdriver.Chrome() # 或者使用其他浏览器驱动# 打开抖音网站
driver.get('https://www.douyin.com')# 等待页面加载(这里可能需要根据实际情况调整等待时间)
driver.implicitly_wait(10) # 隐式等待,等待页面元素出现# 获取页面源代码
html = driver.page_source# 关闭浏览器
driver.quit()# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html, 'html.parser')
# ...(后续操作与上面相同)三、抓取抖音视频列表
首先,安装并设置好Selenium以及对应的WebDriver。
使用Selenium打开抖音的网页,例如driver.get("https://www.douyin.com/")。
等待页面加载完成,这可能需要一些时间,因为页面内容是通过JavaScript动态加载的。可以使用WebDriverWait和expected_conditions来等待特定元素的出现。
一旦页面加载完成,你可以使用find_element_by_xpath或其他定位方法来获取视频列表。
遍历视频列表,提取每个视频的相关信息,如视频标题、发布者、播放次数等。
如果需要,可以模拟滚动页面以加载更多的视频内容。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 设置WebDriver的路径
driver_path = 'path/to/your/webdriver' # 例如:'C:/path/to/chromedriver.exe' for Chrome# 创建WebDriver实例
driver = webdriver.Chrome(executable_path=driver_path)# 打开抖音网页
driver.get('https://www.douyin.com/')# 等待页面加载完成
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'video-list'))) # 假设视频列表的类名为'video-list'# 获取视频列表
video_list = driver.find_elements(By.CLASS_NAME, 'video-item') # 假设每个视频的类名为'video-item'# 遍历视频列表并打印视频信息
for video in video_list:# 这里假设视频标题的类名为'title',可能需要根据实际情况调整title = video.find_element(By.CLASS_NAME, 'title').textprint(f"视频标题: {title}")# 关闭WebDriver
driver.quit()四、抓取目标用户视频数据
要抓取某个博主下的所有视频数据,你需要执行以下步骤:
定位博主页面:首先,你需要找到博主的个人主页。这通常可以通过在抖音平台上搜索博主的用户名或ID来实现。
获取视频列表:在博主的个人主页上,通常会有一个视频列表,展示了博主发布的所有视频。你需要编写代码来遍历这些视频,并提取相关信息。
数据存储:将抓取的视频数据存储在适当的格式中,如CSV、JSON或数据库。
以下是一个简化的Python代码示例,展示了如何使用Selenium来抓取博主视频列表的基本思路。请注意,这个示例假设你已经知道博主的用户名或ID,并且抖音平台的页面结构没有发生变化。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# 设置WebDriver的路径
driver_path = 'path/to/your/webdriver'
driver = webdriver.Chrome(executable_path=driver_path)# 打开抖音并搜索博主
driver.get('https://www.douyin.com/')
search_box = driver.find_element(By.CLASS_NAME, 'search-input') # 假设搜索框的类名为'search-input'
search_box.send_keys('博主用户名') # 输入博主的用户名
search_box.submit()# 等待博主页面加载
time.sleep(5) # 等待5秒,确保页面加载完成# 定位博主的个人主页链接并点击进入
# 这里需要根据实际情况来定位博主的个人主页链接
# 假设我们已经找到了链接
bloger_profile_link = driver.find_element(By.CLASS_NAME, 'profile-link') # 假设类名为'profile-link'
bloger_profile_link.click()# 等待视频列表加载
time.sleep(5) # 等待5秒,确保视频列表加载完成# 获取视频列表并提取数据
video_list = driver.find_elements(By.CLASS_NAME, 'video-item') # 假设视频项的类名为'video-item'
videos_data = []
for video in video_list:# 提取视频信息,这里需要根据实际的HTML结构来定位元素title = video.find_element(By.CLASS_NAME, 'video-title').textviews = video.find_element(By.CLASS_NAME, 'video-views').text# ... 其他需要的数据videos_data.append({'title': title, 'views': views, 'url': video.get_attribute('href')})# 打印抓取的视频数据
for video in videos_data:print(video)# 关闭WebDriver
driver.quit()五、开源软件推荐
Open-Spider是一个开源的数据采集工具,它旨在简化数据采集的过程,使得即使没有数据采集技术背景的用户也能够轻松采集海量数据。这个工具提供了一个“采集应用市场”,用户可以在这里分享、交流和使用其他人上传的数据采集脚本。通过这种方式,用户可以快速获取到自己需要采集的网站数据,并且可以在自己的电脑、服务器或云端运行这些脚本。
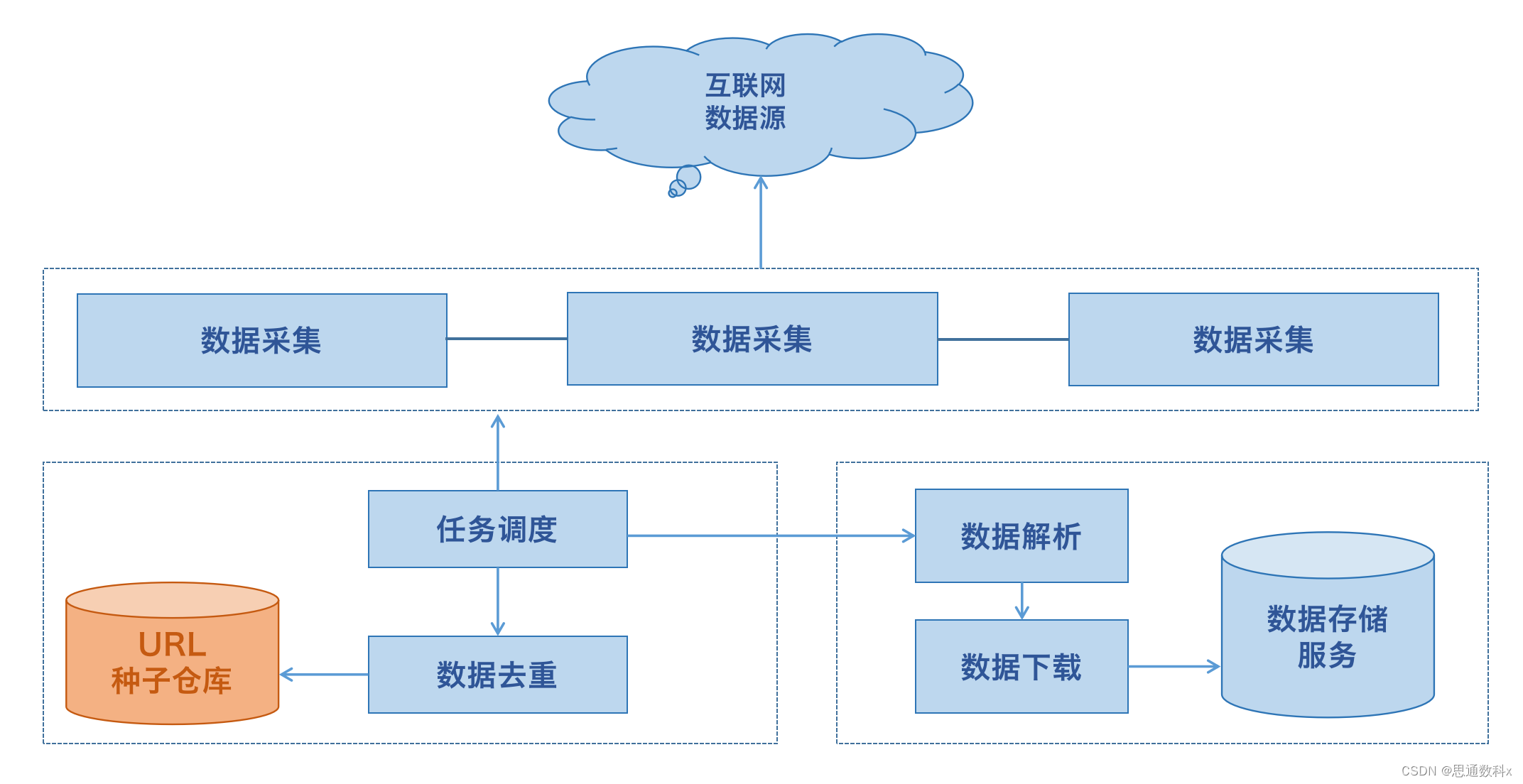
1.模板采集
模板采集模式内置上百种主流网站数据源,如京东、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
2.智能采集
采集可根据不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
3.自定义采集
针对不同用户的采集需求,可提供自动生成爬虫的自定义模式,可准确批量识别各种网页元素,还有翻页、下拉、ajax、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。

六、开源项目地址
Open-Spider: 不懂数据采集技术,也可轻松采集海量数据!简单易上手,人人可用的数据采集工具!
Open-Spider: 不懂数据采集技术,也可轻松采集海量数据!简单易上手,人人可用的数据采集工具!![]() https://gitee.com/stonedtx/open-spider
https://gitee.com/stonedtx/open-spider
这篇关于open-spider开源爬虫工具:抖音数据采集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





