smote专题

样本不平衡--SMOTE算法-学习笔记
1 SMOTE算法的简单理解 一个数集中的数据是分布在特征空间中的,假设数据是2维的,那么数据的就是一个平面上的点。对于类别不平衡数据来说,假设负样本数据是少量的,那么这个数据只占据了空间的一小部分。SMOTE 算法就是对这些小样本数据占据的空间中进行插值。 而不影响到正样本的空间。 2 如何插值 SMOTE算法采取了一种策略,选择两个距离接近的点进行插值。

机器学习之SMOTE重采样--解决样本标签不均匀问题
一、SMOTE原理 通常在处理分类问题中数据不平衡类别。使用SMOTE算法对其中的少数类别进行过采样,以使其与多数类别的样本数量相当或更接近。SMOTE的全称是Synthetic Minority Over-Sampling Technique 即“人工少数类过采样法”,非直接对少数类进行重采样,而是设计算法来人工合成一些新的少数样本。 二、使用 1.安装库 python提供了就是一个处
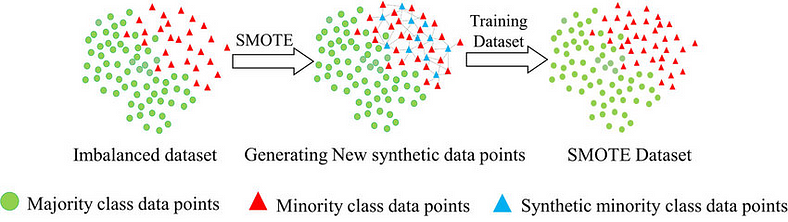
【机器学习】合成少数过采样技术 (SMOTE)处理不平衡数据(附代码)
1、简介 不平衡数据集是机器学习和人工智能中普遍存在的挑战。当一个类别中的样本数量明显超过另一类别时,机器学习模型往往会偏向大多数类别,从而导致性能不佳。 合成少数过采样技术 (SMOTE) 已成为解决数据不平衡问题的强大且广泛采用的解决方案。 在本文中,我们将探讨 SMOTE 的概念、其工作原理、优点、局限性及其对提高人工智能模型的性能和公平性的重大影响。 2、SMOTE

应用ANN+SMOTE+Keras Tuner算法进行信用卡交易欺诈侦测
目录 SMOTE: ANN:ANN(MLP) 三种预测-CSDN博客 Keras Tuner:CNN应用Keras Tuner寻找最佳Hidden Layers层数和神经元数量-CSDN博客 数据: 建模: SMOTE Sampling: Keras Tuner: SMOTE: SMOTE(Synthetic Minority Over-sampling Techni

python实现smote处理正负样本失衡问题
机器学习中难免遇到正负样本不平衡问题,处理办法通常有梁总,一:过采样,增加正样本数据;二:欠采样,减少负样本数据,缺点是会丢失一些重要信息。smote属于过采样。 代码 # from imblearn.over_sampling import BorderlineSMOTE# from imblearn.over_sampling import SMOTENC# from i
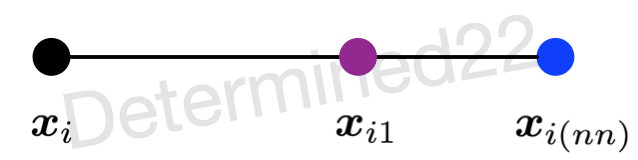
SMOTE合成少数过采样技术
1. SMOTE JAIR’2002的文章《SMOTE: Synthetic Minority Over-sampling Technique》提出了一种过采样算法SMOTE。概括来说,本算法基于“插值”来为少数类合成新的样本。 设训练集的一个少数类的样本数为T,那么SMOTE 算法将为这少数类合成NT个新样本。 考虑少数类一个样本 i,特征向量 x i , i ∈ 1 , . . . ,