本文主要是介绍【机器学习】合成少数过采样技术 (SMOTE)处理不平衡数据(附代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、简介
不平衡数据集是机器学习和人工智能中普遍存在的挑战。当一个类别中的样本数量明显超过另一类别时,机器学习模型往往会偏向大多数类别,从而导致性能不佳。
合成少数过采样技术 (SMOTE) 已成为解决数据不平衡问题的强大且广泛采用的解决方案。
在本文中,我们将探讨 SMOTE 的概念、其工作原理、优点、局限性及其对提高人工智能模型的性能和公平性的重大影响。
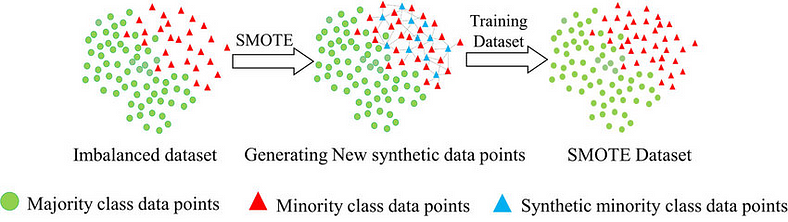
2、SMOTE
SMOTE 背后的主要思想是通过生成合成样本来弥合少数群体和多数群体之间的差距。
以下是 SMOTE 工作原理的分步说明:
2.1识别少数样本:
第一步涉及识别数据集中属于少数类别的样本。
2.2 识别K近邻:
对于每个少数样本,SMOTE 识别其在特征空间中的 K-近邻。通常,欧几里德距离度量用于测量数据点之间的相似性。
2.3 合成样本生成:
一旦识别出邻居,SMOTE 就会选择随机邻居并计算少数样本的特征向量与其所选邻居之间的差异。
然后将该差异乘以 0 到 1 之间的随机数,并将其添加到少数样本的特征向量中。
此过程会创建新的合成样本,这些样本位于少数样本与其所选邻居之间的线段上
重复生成合成样本的过程,直到达到所需的类别平衡水平。
3.SMOTE的好处
3.1 提高模型性能:
通过解决类不平衡问题,SMOTE 使 AI 模型能够更好地识别模式并跨类进行泛化,从而提高整体性能。
3.2 减轻偏差:
SMOTE 有助于减少类别不平衡带来的偏差,确保模型不会以牺牲少数类别为代价而偏向多数类别。
3.3 数据效率:
SMOTE 有效地放大了少数类中的样本数量,而无需收集额外的数据,使其成为一种资源高效的技术。
3.4和各种算法的兼容性:
SMOTE 与算法无关,这意味着它可以与各种 AI 算法一起使用,包括决策树、支持向量机、神经网络等。
虽然 SMOTE 已被证明是一种有价值的工具,但在应用该技术时必须意识到其局限性并考虑某些方面:
1.过度拟合风险:如果使用不当,SMOTE 可能会导致过度拟合,尤其是在生成过多合成样本时。适当的交叉验证对于准确评估模型性能至关重要。
2.潜在噪声:SMOTE 生成的合成样本可能无法准确代表真实世界的数据实例,从而引入可能对模型性能产生负面影响的噪声。
3.k 的合适选择:SMOTE 的性能受到参数 k 的选择的影响,它决定了要考虑的最近邻居的数量。k 值不合适可能会导致不良结果
4.代码
下面是合成少数过采样技术 (SMOTE) 的 Python 实现:
import numpy as np
from sklearn.neighbors import NearestNeighborsdef SMOTE(X, y, N, k=5):"""合成少数类过采样技术(SMOTE)参数:X (numpy数组): 包含数据点的特征矩阵。y (numpy数组): 对应的标签数组(多数类为0,少数类为1)。N (int): 生成的合成样本数量。k (int, 可选): 考虑的最近邻居数量,默认为5。返回:X_synthetic (numpy数组): 包含生成样本的合成特征矩阵。y_synthetic (numpy数组): 合成样本对应的标签数组。"""# 分离多数类和少数类样本X_majority = X[y == 0]X_minority = X[y == 1]# 计算每个少数类样本需要生成的合成样本数量N_per_sample = N // len(X_minority)# 如果k大于少数样本数量,则将其减少到可能的最大值k = min(k, len(X_minority) - 1)# 初始化列表以存储合成样本和相应的标签synthetic_samples = []synthetic_labels = []# 在少数类样本上拟合k近邻knn = NearestNeighbors(n_neighbors=k)knn.fit(X_minority)for minority_sample in X_minority:# 查找当前少数类样本的k个最近邻居_, indices = knn.kneighbors(minority_sample.reshape(1, -1), n_neighbors=k)# 随机选择k个邻居并创建合成样本for _ in range(N_per_sample):neighbor_index = np.random.choice(indices[0])neighbor = X_minority[neighbor_index]# 计算当前少数类样本和邻居之间的差异difference = neighbor - minority_sample# 生成一个0到1之间的随机数alpha = np.random.random()# 创建一个合成样本作为少数类样本和邻居的线性组合synthetic_sample = minority_sample + alpha * difference# 将合成样本及其标签追加到列表中synthetic_samples.append(synthetic_sample)synthetic_labels.append(1)# 将列表转换为numpy数组X_synthetic = np.array(synthetic_samples)y_synthetic = np.array(synthetic_labels)# 将原始多数类样本与合成样本合并X_balanced = np.concatenate((X_majority, X_synthetic), axis=0)y_balanced = np.concatenate((np.zeros(len(X_majority)), y_synthetic), axis=0)return X_balanced, y_balancedSMOTE函数接受特征矩阵X、对应的标签数组y、要生成的合成样本数N以及最近邻居数k(默认设置为5)。
该函数返回包含生成样本的合成特征矩阵X_synthetic和对应的标签数组y_synthetic。
请注意,这个实现假设是二元分类,其中少数类标记为1,多数类标记为0。原始的多数类样本被保留,合成样本仅为少数类创建。
要使用SMOTE函数,您可以使用您的数据集调用它,并指定您想要生成的合成样本数量,例如:
X_balanced, y_balanced = SMOTE (X_train, y_train, N= 1000 )在这个示例中,SMOTE函数将生成1000个合成样本来平衡训练数据,X_balanced和y_balanced分别包含增强的特征矩阵和对应的标签。
下面是一个如何定义X_train和y_train为numpy数组的简单二元分类问题示例:
import numpy as np # 具有 10 个样本和 2 个特征的示例特征矩阵
X_train X_train = np.array([ [ 1.0, 2.0 ], [ 2.0, 3.0 ], [ 3.0, 4.0 ], [ 4.0, 5.0 ], [ 5.0, 6.0 ], [ 6.0, 7.0 ], [ 7.0, 8.0 ], [ 8.0, 9.0 ], [ 9.0, 10.0 ], [ 10.0, 11.0 ]
]) # 标签数组示例 y_train (0 代表多数类,1 代表少数类)y_train = np.array([ 0 , 0 , 0 , 0 , 0 , 1 , 0 , 1 , 0 , 0 ])在这个示例中,X_train是一个二维numpy数组,代表具有10个样本(行)和2个特征(列)的特征矩阵。每行对应一个数据样本,每列对应一个特定的特征。
y_train是一个一维numpy数组,代表X_train中样本的对应标签。在这个示例中,多数类被标记为0,少数类被标记为1。
您可以使用前面代码片段中提供的SMOTE函数来平衡X_train和y_train数据集,并为少数类创建合成样本。例如:
X_balanced, y_balanced = SMOTE(X_train, y_train, N=1000)调用SMOTE函数后,X_balanced和y_balanced将包含用合成样本增强的特征矩阵和对应的标签,以平衡数据集。
生成的合成样本数量(在这个示例中为1000)可以根据不平衡程度和您的具体需求进行调整。
5.结语
合成少数类过采样技术(SMOTE)已成为解决AI中不平衡数据集挑战的一个强大而有效的解决方案。
通过生成合成样本,SMOTE平衡了类别分布,使AI模型能够做出更好的决策,减少偏见并提高性能。
然而,使用SMOTE时必须谨慎,考虑其局限性,并确保合成数据的质量和相关性。
随着AI的不断发展,SMOTE和类似技术将继续作为追求更准确、公平和稳健AI模型的关键工具。
这篇关于【机器学习】合成少数过采样技术 (SMOTE)处理不平衡数据(附代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




