本文主要是介绍应用ANN+SMOTE+Keras Tuner算法进行信用卡交易欺诈侦测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
SMOTE:
ANN:ANN(MLP) 三种预测-CSDN博客
Keras Tuner:CNN应用Keras Tuner寻找最佳Hidden Layers层数和神经元数量-CSDN博客
数据:
建模:
SMOTE Sampling:
Keras Tuner:
SMOTE:
SMOTE(Synthetic Minority Over-sampling Technique)是一种用于处理不均衡数据集的采样方法。在不均衡数据集中,某个类别的样本数量往往很少,这导致了模型对少数类别的预测效果较差。SMOTE采样通过合成新的少数类样本来增加其数量,从而提高模型对少数类样本的学习能力。
SMOTE采样的基本思想是对于每个少数类样本,从其最近的k个最近邻样本中随机选择一个样本,然后在该样本与原始样本之间生成一个合成样本。这样一来,就能增加少数类样本的数量,使得不同类别之间的样本分布更加平衡。
SMOTE采样可以应用于各种机器学习算法中,包括决策树、逻辑回归、支持向量机等。它能够有效地解决不均衡数据集带来的问题,提高模型的预测能力和准确性。
ANN:ANN(MLP) 三种预测-CSDN博客
Keras Tuner:CNN应用Keras Tuner寻找最佳Hidden Layers层数和神经元数量-CSDN博客
数据:
import numpy as np
import pandas as pd
import keras
import matplotlib.pyplot as plt
import seaborn as snsdata = pd.read_csv('creditcard.csv',sep=',')from sklearn.preprocessing import StandardScaler #数据标准化
data['Amount(Normalized)'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1,1))
data.iloc[:,[29,31]]data = data.drop(columns = ['Amount', 'Time'], axis=1) # This columns are not necessary anymore.X = data.drop('Class', axis=1)
y = data['Class']from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# We are transforming data to numpy array to implementing with keras
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test) 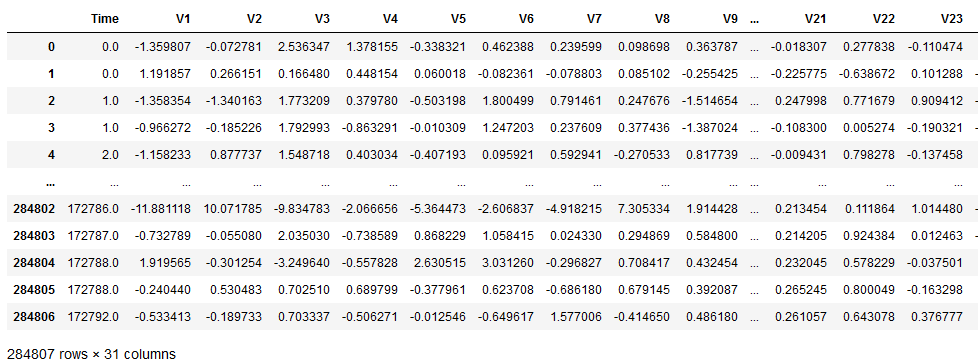
建模:
from tensorflow import keras
from tensorflow.keras import layers
from kerastuner.tuners import RandomSearchfrom keras.models import Sequential
from keras.layers import Dense, Dropout
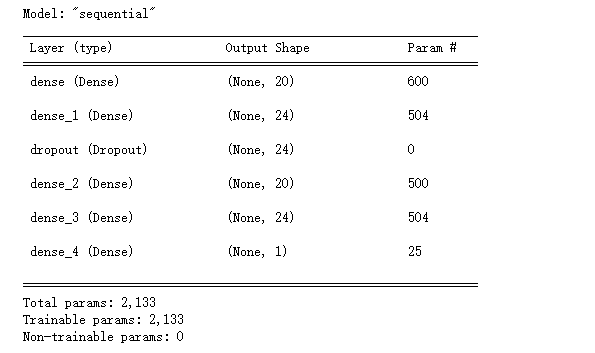
model = Sequential([Dense(units=20, input_dim = X_train.shape[1], activation='relu'),Dense(units=24,activation='relu'),Dropout(0.5),Dense(units=20,activation='relu'),Dense(units=24,activation='relu'),Dense(1, activation='sigmoid')
])
model.summary()model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=30, epochs=5)score = model.evaluate(X_test, y_test)
print('Test Accuracy: {:.2f}%\nTest Loss: {}'.format(score[1]*100,score[0]))
'''结果:
671/2671 [==============================] - 6s 2ms/step - loss: 0.0029 - accuracy: 0.9994
Test Accuracy: 99.94%
Test Loss: 0.0028619361110031605
'''
from sklearn.metrics import confusion_matrix, classification_report
y_pred = model.predict(X_test)
y_test = pd.DataFrame(y_test)
cm = confusion_matrix(y_test, y_pred.round())
sns.heatmap(cm, annot=True, fmt='.0f', cmap='cividis_r')
plt.show()#实际上我们要预测为1的数据, 虽然模型准确率很高 但是对于1的预测并没有非常准确 
SMOTE Sampling:
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42)
X_smote, y_smote = sm.fit_resample(X, y)
X_smote = pd.DataFrame(X_smote)
y_smote = pd.DataFrame(y_smote)
y_smote.iloc[:,0].value_counts()X_train, X_test, y_train, y_test = train_test_split(X_smote, y_smote, test_size=0.3, random_state=0)
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size = 30, epochs = 5)score = model.evaluate(X_test, y_test)
print('Test Accuracy: {:.2f}%\nTest Loss: {}'.format(score[1]*100,score[0]))
'''结果:
5331/5331 [==============================] - 13s 2ms/step - loss: 0.0046 - accuracy: 0.9991
Test Accuracy: 99.91%
Test Loss: 0.004645294509828091
'''y_pred = model.predict(X_test)
y_test = pd.DataFrame(y_test)
cm = confusion_matrix(y_test, y_pred.round())
sns.heatmap(cm, annot=True, fmt='.0f')
plt.show()#经过SMOTE Sampling后 对于1的失误预测从刚刚的25降为11
Keras Tuner:
def build_model(hp):model = keras.Sequential()for i in range(hp.Int('num_layers', 2, 20)):model.add(layers.Dense(units=hp.Int('units_' + str(i),min_value=32,max_value=512,step=32),activation='relu'))model.add(layers.Dense(10, activation='softmax'))model.compile(optimizer=keras.optimizers.Adam(hp.Choice('learning_rate', [1e-2, 1e-3, 1e-4])),loss='sparse_categorical_crossentropy',metrics=['accuracy'])return modeltuner = RandomSearch(build_model,objective='val_accuracy',max_trials=10,directory='my_dir',project_name='helloworld')tuner.search(X_train, y_train,epochs=5,validation_data=(X_test, y_test))
这篇关于应用ANN+SMOTE+Keras Tuner算法进行信用卡交易欺诈侦测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




