skiplist专题
其它高阶数据结构⑦_Skiplist跳表_概念+实现+对比
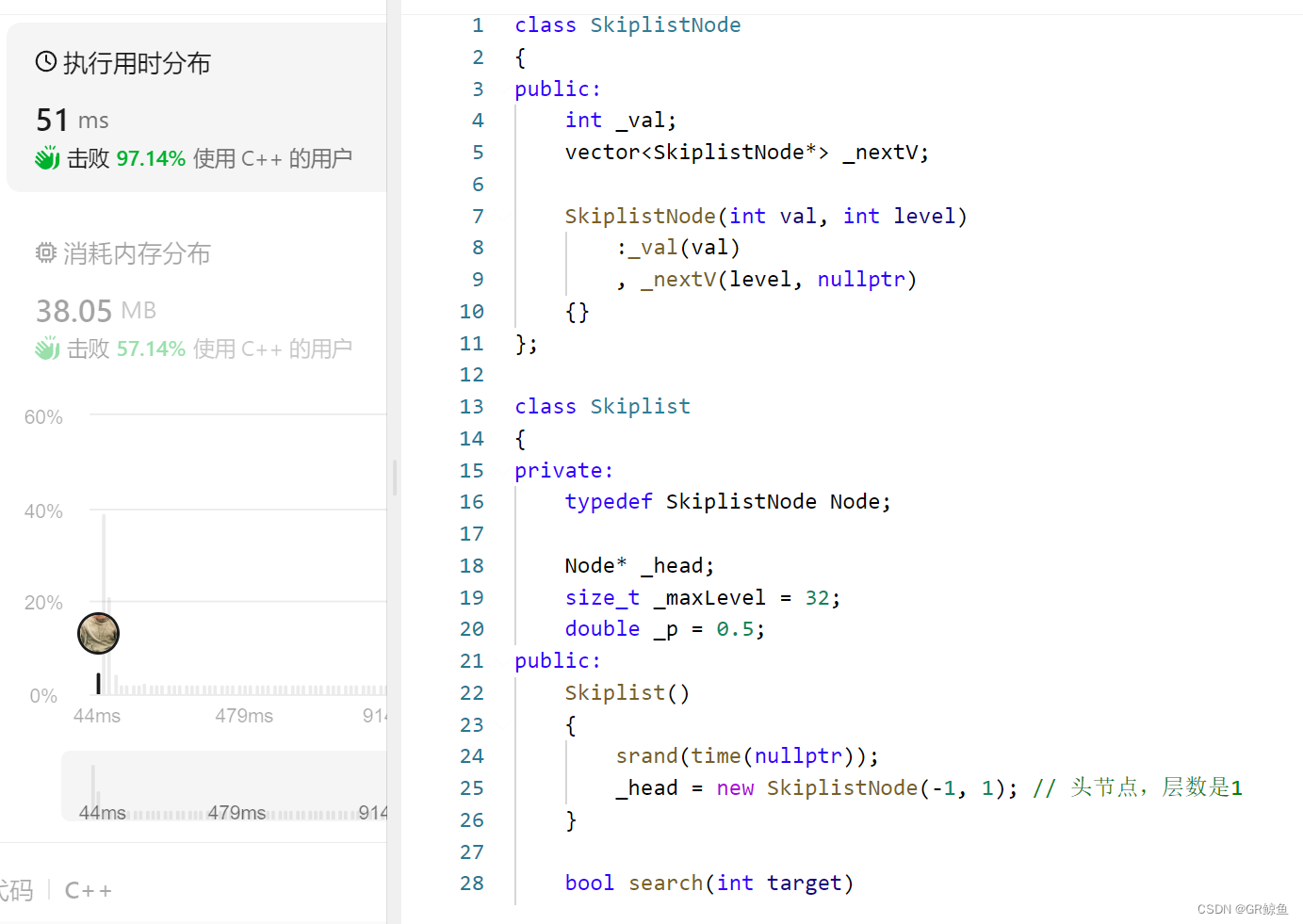
目录 1. Skiplist跳表的概念 2. Skiplist跳表的效率 3. Skiplist跳表的实现 3.1 力扣1206. 设计跳表 3.2 Skiplist的初始化和查找 3.3 Skiplist的增加和删除 3.4 Skiplist的源码和OJ测试 4. 跳表和平衡搜索树/哈希表的对比 本篇完。 1. Skiplist跳表的概念 skipl

Redis入门到通关之数据结构解析-SkipList
文章目录 ☃️概述☃️总结 ☃️概述 SkipList(跳表)是一种数据结构,用于实现有序元素的动态集合,它的设计目的是在有序链表的基础上通过增加多级索引来提高查找效率。 跳表的核心思想是在原始链表的基础上建立多层索引,每一层索引都是原始链表的子集,其中每个节点都具有指向下一层的指针。这样,从头节点到尾节点的路径形成了一种类似跳跃的结构,使得在搜索时可以跳过一些节
浅析SkipList跳跃表原理及代码实现
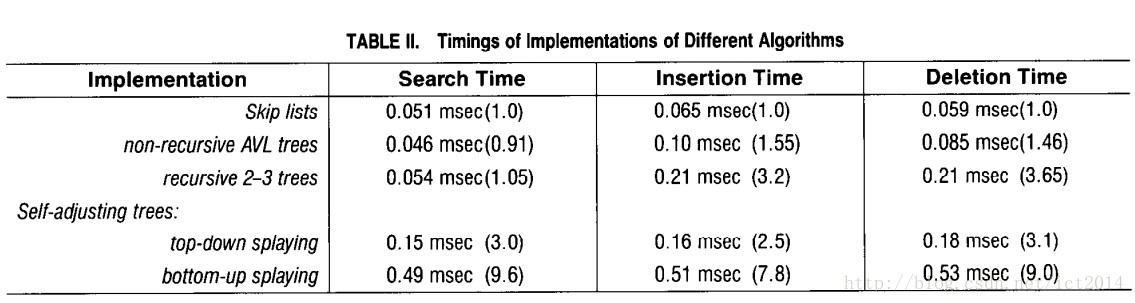
转载请注明:http://blog.csdn.net/ict2014/article/details/17394259 SkipList在leveldb以及lucence中都广为使用,是比较高效的数据结构。由于它的代码以及原理实现的简单性,更为人们所接受。我们首先看看SkipList的定义,为什么叫跳跃表? “ Skip lists are data structures that
SkipList 跳表
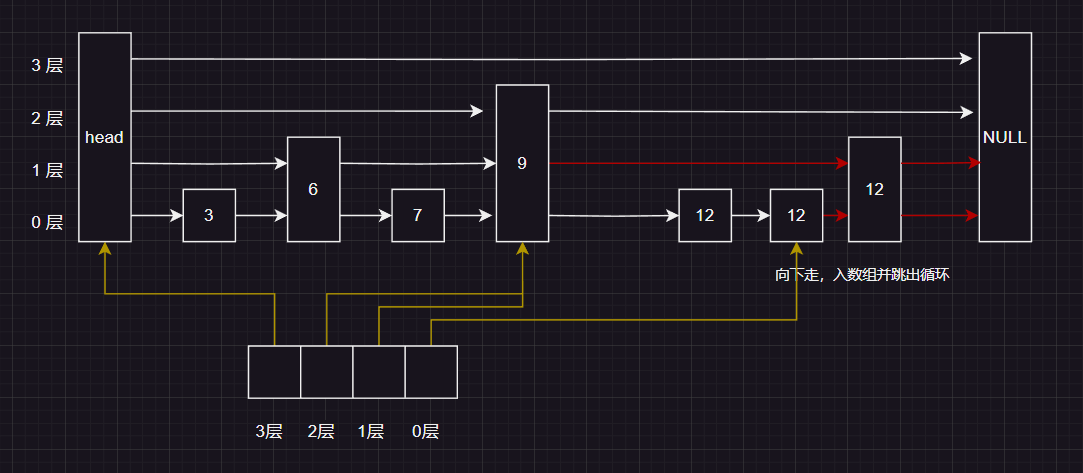
文章目录 查询增加删除写法优化 GO版本题外话 最近在读 LevelDB 的源码,正好看到里面使用了跳表这种数据结构于是学习一下 跳表实际上是由多个链表组成的,时间复杂度是O(logn)一种思路: 每相邻两个节点升高一层,增加一个指针,让指针指向下一个节点以此类推,我们可以在第二层新产生的链表上,继续为每相邻的两个节点升高一层如果严格按照上面的设计来执行,那么调表的查询的

数据结构 跳表SkipList的原理和代码实现
跳表简介 跳表是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。 我们知道,普通单链表查询一个元素的时间复杂度为O(n),即使该单链表是有序的,我们也不能通过2分的方式缩减时间复杂度。 如上图,我们要查询元素为55的结点,必须从头结点,循环遍历到最后一个节点,不算-INF(负无穷)一共查询

leveldb阅读-Skiplist
Skiplist是一种随机化的链表,通过并联链表,可以实现数据的快速插入和查找,同时能够取得比较好的时间开销和空间开销。详细的实现原理可以参照http://blog.csdn.net/haidao2009/article/details/8206856。leveldb采用skiplist来实现k-value的处理应该也是综合考虑到空间开销和时间开销的成本。 在介绍leveldb中的Skiplis

数据映射--跳表(skiplist)
http://blog.sina.com.cn/s/blog_693f08470101n2lv.html 本周我要介绍的数据结构,是我非常非常喜欢的一个数据结构,因为咱也是吃过平衡二叉树的苦的人啊T_T ,神马左旋,右旋,上旋,下旋,看原理的时候就已经晕晕乎乎的了,再看源码,发现比原理还复杂,心理就想,这东西是不是就是为了让我挂科给学校交重修费来拯救学校财政的东西啊?!。。 当

golang实现skiplist 跳表
跳表 package mainimport ("errors""math""math/rand")func main() {// 双向链表///**先理解查找过程Level 3: 1 6Level 2: 1 3 6Level 1: 1 2 3 4 6比如 查找2 ; 从高层往下找;如果查找的值比当前值小 说明没有可查找的值2比1大 往当前层的下个节点查找,3层的后面没有了或者比后面
跳表(SkipList)
SkipList跳表基本原理 为什么选择跳表 目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等。 想象一下,给你一张草稿纸,一只笔,一个编辑器,你能立即实现一颗红黑树,或者AVL树 出来吗? 很难吧,这需要时间,要考虑很多细节,要参考一堆算法与数据结构之类的树, 还要参考网上的代码,相当麻烦。 用跳表吧,跳表是一种随机化的数据结构,目前开源软件 Red
redis底层数据结构之skiplist实现
skiplist实现 skiplist跳跃表,是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,来达到快速访问节点的目的,redis使用skiplist作为zsort的底层实现之一 结构很像树形结构 typedef struct zskiplistNode { // 对象 sds ele; // 分值 double score; // 后退指针,从表尾向表头

跳转表Skiplist学习记录
这里写自定义目录标题 9.1.3 接口定义 template <typename K, typename V> struct Dictionary {virtual int size() const = 0;virtual bool put(K, V) = 0;virtual V* get(K k) = 0;virtual bool remove(K k) = 0;}

skiplist 跳转表基本概念
跳转表的基本概念 跳转表是一个基于列表list的数据结构,从结构上来说,它是由多个列表组成的。各个列表在纵向形成多层,其中第一层(最底层)拥有跳转表中的所有数据节点,以上各层列表中的数据都是其底层列表的一个子集,特别地,最顶层的列表不包含任何数据,仅含有两个头尾哨兵。跳转表的结构如图所示: 用地铁站对跳转表打一个比方,设想有一个城市的地铁分为多层,其中最底层的地铁要经过该城市的所有站台;所
Redis skiplist源码解析(支持范围查询)
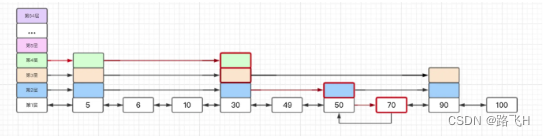
跳表是一个多层的有序链表,在跳表中进行查询操作时,查询代码可以从最高层开始查询。层数越高,结点数越少,同时高层结点的跨度会比较大。因此,在高层查询结点时,查询一个结点可能就已经查到了链表的中间位置了。 这样一来,跳表就会先查高层,如果高层直接查到了等于待查元素的结点,那么就可以直接返回。如果查到第一个大于待查元素的结点后,就转向下一层查询。下层上的结点数多于上层,所以这样可以在更多的结点中进一步
redis6.0源码分析:跳表skiplist
文章目录 前言什么是跳表跳表(redis实现)的空间复杂度相关定义 跳表(redis实现)相关操作创建跳表插入节点查找节点删除节点 前言 太长不看版 跳跃表是有序集合zset的底层实现之一, 除此之外它在 Redis 中没有其他应用。每个跳跃表节点的层高都是 1 至 64 之间的随机数。层高越高出现的概率越低,层高为i的概率为跳跃表中,分值可以重复, 但对象成员唯一。分值相同
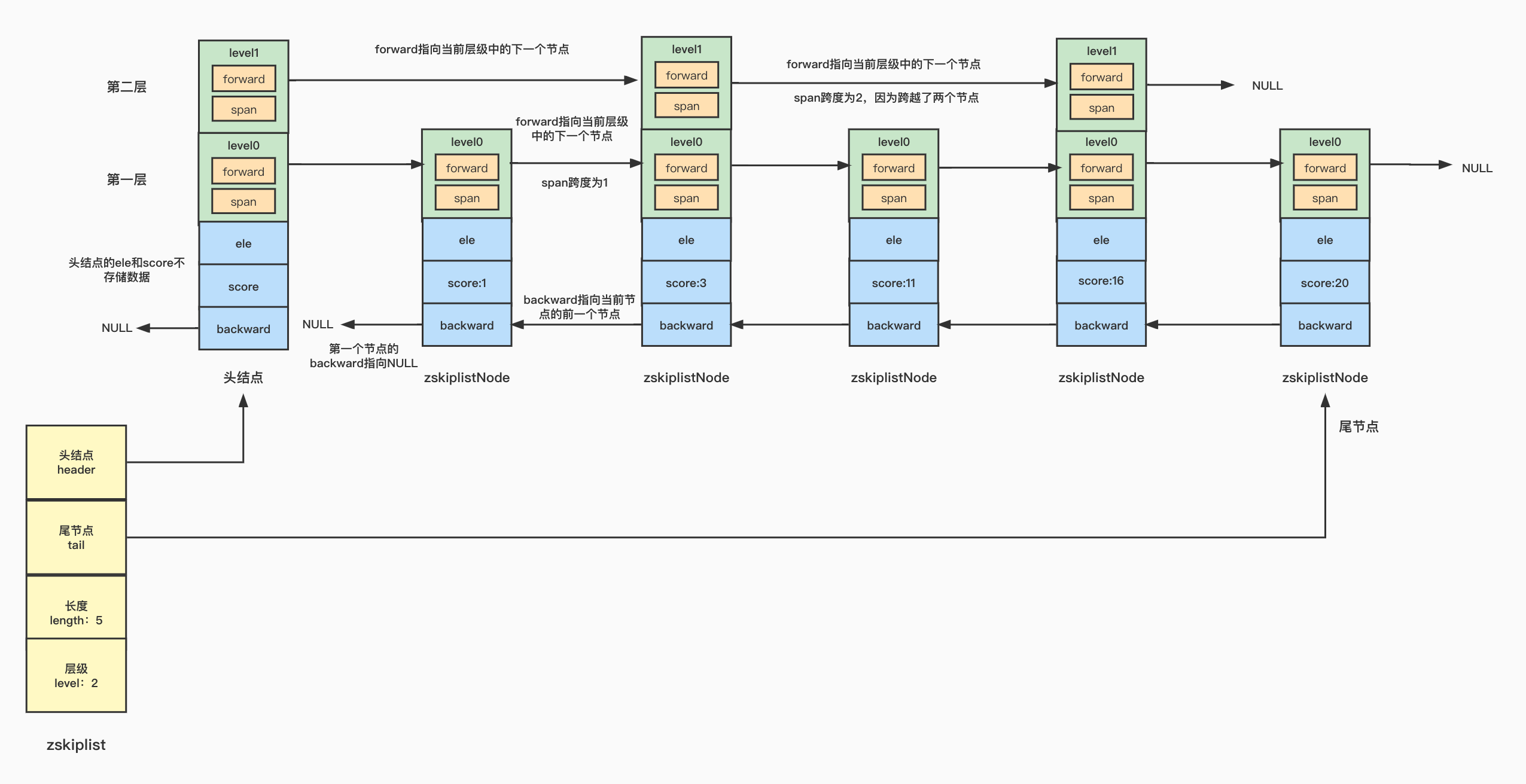
【Redis】基础数据结构-skiplist跳跃表
有序集合Sorted Set zadd zadd用于向集合中添加元素并且可以设置分值,比如添加三门编程语言,分值分别为1、2、3: 127.0.0.1:6379> zadd language 1 java(integer) 1127.0.0.1:6379> zadd language 2 c++(integer) 1127.0.0.1:6379> zadd language 3 py