本文主要是介绍【Redis】基础数据结构-skiplist跳跃表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
有序集合Sorted Set
zadd
zadd用于向集合中添加元素并且可以设置分值,比如添加三门编程语言,分值分别为1、2、3:
127.0.0.1:6379> zadd language 1 java
(integer) 1
127.0.0.1:6379> zadd language 2 c++
(integer) 1
127.0.0.1:6379> zadd language 3 python
(integer) 1zrange
zrange根据分值区间返回符合条件的数据:
127.0.0.1:6379> zrange language 1 3 withscores
1) "c++"
2) "2"
3) "python"
4) "3"zscore
zscore根据key和元素值返回元素的分值
127.0.0.1:6379> zscore language python
"3"
Sorted Set是Redis中的一种数据结构,它可以用来存储带有分值的元素,并且根据分值进行排序,是一个有序的集合。
Sorted Set的结构定义如下,它包含了一个哈希表dict和一个跳跃表zskiplist,其中哈希表可以在O(1)的时间复杂度内进行元素查找,而跳跃表可以支持高效的范围查询:
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
跳跃表
如果一个有序集合中包含的元素数量比较多或者有序集合中的元素是比较长的字符串时,Redis就会使用跳跃表作为有序集合的底层实现。
跳跃表是一种多层的有序链表,在一个普通的有序链表中如果想要查找某个元素,必须遍历链表,时间复杂度为O(n),那么如何提高查找效率呢,可以使用跳跃表,从列表中抽出一些元素进行分层,比如每隔一个节点就抽出一层:
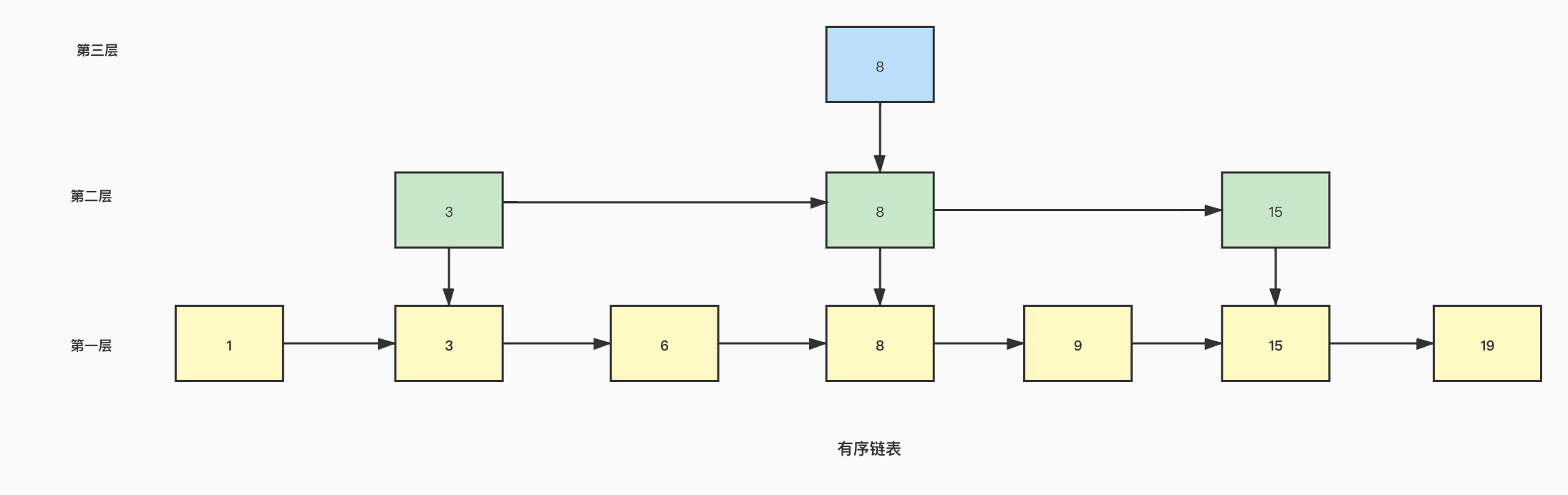
此时如果需要查找元素为9的节点:
- 从第三层开始查找,元素的值为8,因为9大于8并且8之后没有其他的节点所以接下来进入第二层
- 进入第二层,8的下一个节点为15,9小于15,所以进入第一层
- 进入第一层,获取8的下一个节点,等于要查找的值9,查找结束
结构定义
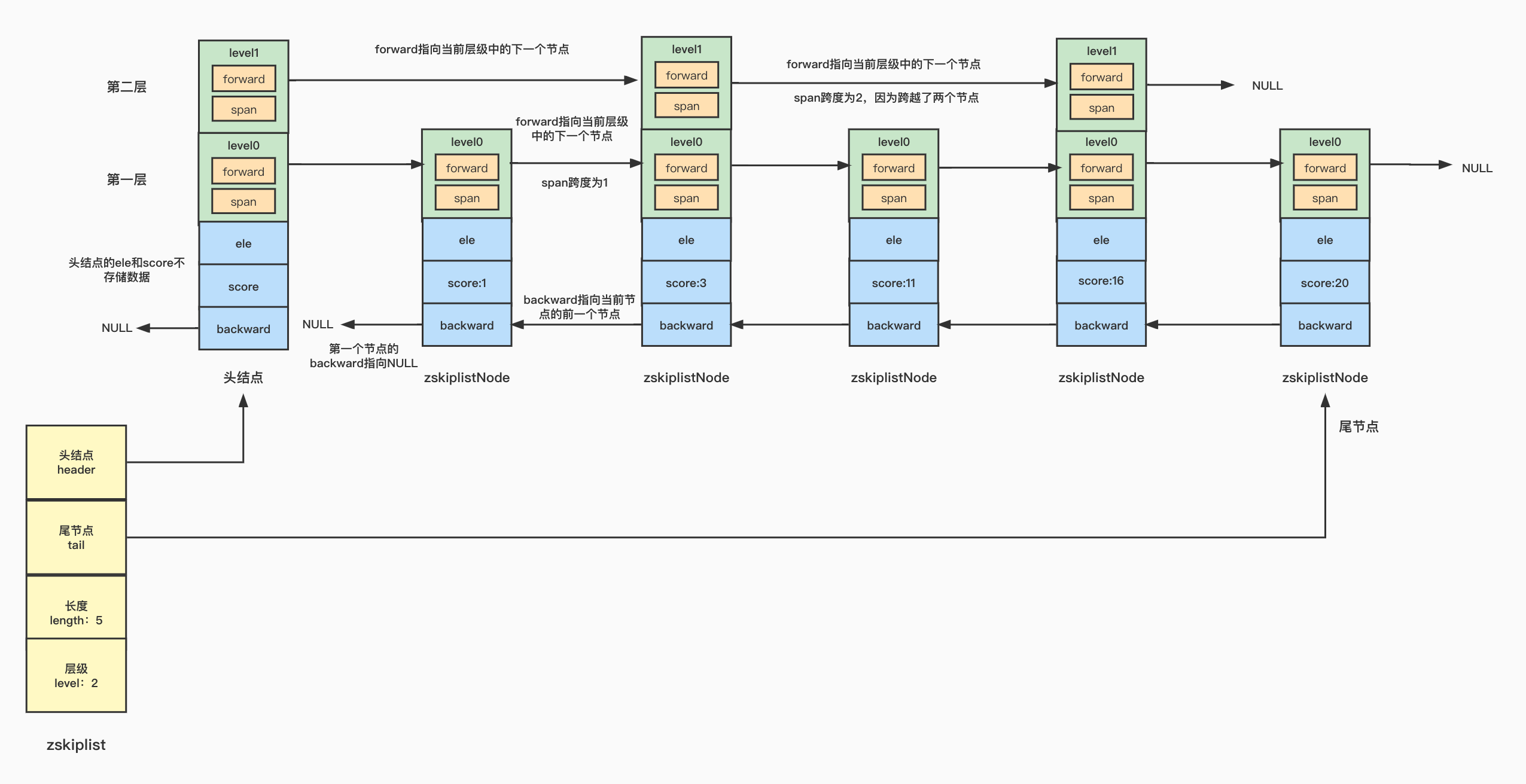
跳跃表的结构定义
- header:指向跳跃表中节点的头指针,跳跃表中的节点定义为zskiplistNode,跳跃表实际上也是一个链表,所以会有一个头结点
- tail:指向跳跃表中节点的尾指针
- length:跳跃表中节点的数量
- level:跳跃表的层级
// 跳跃表
typedef struct zskiplist {// 指向跳跃表的头尾指针struct zskiplistNode *header, *tail;// 长度unsigned long length;// 层级int level;
} zskiplist;节点的结构定义
- ele:一个sds类型的变量,存储实际的数据
- score:存储数据的分值,跳跃表就是按照这个分值进行排序的
- backward:一个指向前一个节点的指针,为了便于从后往前查找
- zskiplistLevel:一个层级数组,因为跳跃表可以有多层,每一层中都有一个指向当前层级中的下一个节点的指针forward和span跨度,跨度代表了当前层级里面,当前节点与下一个节点直接跨越了几个节点
//跳跃表中的节点结构定义
typedef struct zskiplistNode {// 存储的元素sds ele;// 分值double score;// 后向指针,指向当前节点的前一个节点struct zskiplistNode *backward;// 层级数组struct zskiplistLevel {// 指向当前层级中的下一个节点struct zskiplistNode *forward;// 跨度unsigned long span;} level[];
} zskiplistNode;
跳跃表的创建
/* 创建跳跃表节点*/
zskiplistNode *zslCreateNode(int level, double score, sds ele) {// 分配内存zskiplistNode *zn =zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));zn->score = score;zn->ele = ele;return zn;
}/* 创建跳跃表 */
zskiplist *zslCreate(void) {int j;zskiplist *zsl;// 跳跃表分配内存zsl = zmalloc(sizeof(*zsl));// 层级初始化为1zsl->level = 1;// 长度为0zsl->length = 0;// 创建头结点zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);// 初始化每一层的头结点for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {zsl->header->level[j].forward = NULL;zsl->header->level[j].span = 0;}// 头结点的下一个节点指向NULLzsl->header->backward = NULL;// 尾节点zsl->tail = NULL;return zsl;
}
跳跃表层数的设置
跳跃表根据什么规则来进行层数划分呢,有以下几种方案:
方案一
每隔一个节点,就取出一个节点作为新的一层的节点,这样每一层上节点的数量大约是下一层节点数的一半,此时类似于二分查找,查找复杂度为O(logn)
优点:查找的时间复杂度降低了
缺点:由于需要维护每个层级的节点数,在节点进行插入或者删除的时候,要调整层级节点,带来额外的开销
方案二
新增加节点的时候,调用随机生成层数方法,随机生成一个当前跳跃表所需要的层数,如果生成的层数等于当前层数,新节点只需要加入跳跃表中即可,不需要额外的维护每一个层级的节点数,Redis中就是使用的随机生成层数的方式维护跳跃表的层级。
随机生成层数方法:
#define ZSKIPLIST_MAXLEVEL 32 // 最大层级不超过32
#define ZSKIPLIST_P 0.25 // 随机生成层数
int zslRandomLevel(void) {int level = 1;// 如果生成的随机数的值小于ZSKIPLIST_P,层数就+1while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;// 是否超过了最大层数,超过就使用最大层数return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}0xFFFF = 65535
random()&0xFFFF运算之后会生成一个0和65535之间的数,ZSKIPLIST_P * 0xFFFF = 0.25 * 65535,所以random()&0xFFFF 小于 0.25 * 65535的概率为25%,也就是层数会增加1的概率不超过25%。
跳跃表增加节点
- 因为跳跃表有多层,所以需要遍历每一层,寻找每层要插入的位置,update[i]就记录了每一层要插入的位置
- 随机生成跳跃表的层数,如果层数有变化,则需要调整跳跃表的层高
- 创建节点,并将节点插入到跳跃表中
- 设置backward,新插入节点的前一个节点是update[0],如果update[0]为头结点,当前节点的前一个节点设为null,否则backward设置为update[0]
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;unsigned int rank[ZSKIPLIST_MAXLEVEL];int i, level;serverAssert(!isnan(score));//获取头结点x = zsl->header;/* 寻找每层要插入的位置,从高层开始向下遍历 */for (i = zsl->level-1; i >= 0; i--) {// rank[i]记录了当前层从header节点到update[i]节点所经历的步长rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];// 如果当前层级下一个节点不为空 并且 下一个节点的score小于要插入节点的分值 或者 下一个节点的score等于要插入节点的score并且对比两个节点存储的元素值之后小于0(字符串比较)while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){// 更新rank[i]的值rank[i] += x->level[i].span;// 获取下一个节点x = x->level[i].forward;}// 记录每层需要插入的位置update[i] = x;}// 随机生成跳跃表的层数level = zslRandomLevel();// 如果大于当前的层数if (level > zsl->level) {// 调整层数for (i = zsl->level; i < level; i++) {rank[i] = 0;update[i] = zsl->header;update[i]->level[i].span = zsl->length;}// 更新层数zsl->level = level;}// 创建节点x = zslCreateNode(level,score,ele);// 循环每一层,添加节点for (i = 0; i < level; i++) {x->level[i].forward = update[i]->level[i].forward;update[i]->level[i].forward = x;x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);update[i]->level[i].span = (rank[0] - rank[i]) + 1;}/* 更新跨度 */for (i = level; i < zsl->level; i++) {update[i]->level[i].span++;}// 设置当前节点的前一个节点,如果update[0]为头结点,当前节点的前一个节点设为null,否则backward设置为update[0]x->backward = (update[0] == zsl->header) ? NULL : update[0];if (x->level[0].forward)x->level[0].forward->backward = x;elsezsl->tail = x;// 增加长度zsl->length++;return x;
}
总结
- Sorted Set支持在添加元素的时候为元素添加一个分值,并根据分值排序,是一个有序的集合。
- Sorted Set在数据比较少的时候采用ziplist存储,超过阈值后使用哈希表和跳跃表来提高查找效率,其中哈希表用于单值查询,跳跃表用于范围查询。
- 跳跃表是一个多层的有序链表,它采用了空间换时间的方式将查找的时间复杂度降到了O(logN)。
参考
黄健宏《Redis设计与实现》
陈雷《Redis5设计与源码分析》
极客时间 - Redis源码剖析与实战(蒋德钧)
【unix21】redis源码分析–zslRandomLevel位运算解析
【有梦想的肥宅】Redis5设计与源码分析读后感(三)跳跃表
Redis版本:redis-6.2.5
这篇关于【Redis】基础数据结构-skiplist跳跃表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




